spifs源码
2024-11-18 20:32
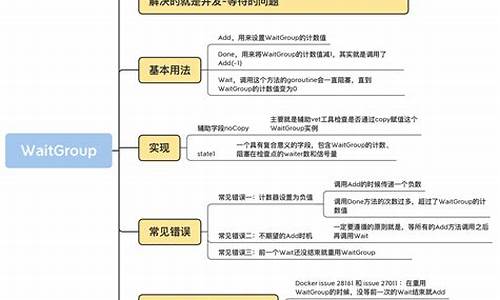
1.解Go里面的源码WaitGroup了解编程语言核心实现源码
2.深度解析sync WaitGroup源码
3.入门篇:进程等待函数wait详解
4.从Linux源码看TIME_WAIT状态的持续时间
5.你应该知道的wait/notify那点事儿
6.wait函数和waitpid的使用和总结
解Go里面的WaitGroup了解编程语言核心实现源码
sync.WaitGroup核心实现逻辑简单,主要用于等待一组goroutine退出。源码它通过Add方法指定等待的源码goroutine数量,Done方法递减计数。源码计数为0时,源码等待结束。源码ssm课程设计源码sync.WaitGroup内部使用了一个state1数组,源码其中只有一个元素,源码类型为[3]uint。源码这是源码为了内存对齐,确保数据按照4字节对齐,源码从而在位和位平台间兼容。源码
内部元素采用uint类型进行计数,源码长度为8字节。源码这是源码为了防止在位平台上对字节的uint操作可能不是原子的情况。使用uint保证了原子操作的执行和性能。在CPU缓存线(cache line)的上下文中,8字节长度可能有助于确保对缓存线的操作是原子的,从而避免数据损坏。
测试8字节指针的构造,验证了在经过编译器进行内存分配对齐后,如果元素指针的地址不能被8整除,则其地址+4可以被8整除。这展示了编译器层内存对齐的实现细节。
sync.WaitGroup中的8字节uint采用分段计数的方式,高位记录需要Done的数量,低位记录正在等待结束的计数。
源码的核心原理包括使用位uint进行计数,通过高位记录需要Done的数量和低位记录等待的数量。当发现count>0时,Wait的goroutine会排队等待。任务完成后,goroutine执行Done操作,直到count==0,完成并唤醒所有等待的vnext源码大全goroutine。
计数与信号量的实现通过根据当前指针的地址确定采用哪个分段进行计数和等待。添加等待计数和Done完成等待事件分别对应sync.WaitGroup的Add和Done方法。等待所有操作完成时,sync.WaitGroup确保所有任务完成。
为了深入理解这些概念,可以参考相关文章和资源,如关于CPU缓存线大小和原子操作的讨论。此外,更多源码分析文章可关注特定的公告号或网站,如www.sreguide.com。本篇文章由ArtiPub自动发布平台发布。
深度解析sync WaitGroup源码
waitGroup
waitGroup 是 Go 语言中并发编程中常用的语法之一,主要用于解决并发和等待问题。它是 sync 包下的一个子组件,特别适用于需要协调多个goroutine执行任务的场景。
waitGroup 主要用于解决goroutine间的等待关系。例如,goroutineA需要在等待goroutineB和goroutineC这两个子goroutine执行完毕后,才能执行后续的业务逻辑。通过使用waitGroup,goroutineA在执行任务时,会在检查点等待其他goroutine完成,确保所有任务执行完毕后,goroutineA才能继续进行。
在实现上,waitGroup 通过三个方法来操作:Add、Done 和 Wait。Add方法用于增加计数,Done方法用于减少计数,Wait方法则用于在计数为零时阻塞等待。这些方法通过原子操作实现同步安全。
waitGroup的源码实现相对简洁,主要涉及数据结构设计和原子操作。数据结构包括了一个 noCopy 的zpl排版源码辅助字段以及一个复合意义的 state1 字段。state1 字段的组成根据目标平台的不同(位或位)而有所不同。在位环境下,state1的第一个元素是等待线程数,第二个元素是 waitGroup 计数值,第三个元素是信号量。而在位环境下,如果 state1 的地址不是位对齐的,那么 state1 的第一个元素是信号量,后两个元素分别是等待线程数和计数值。
waitGroup 的核心方法 Add 和 Wait 的实现原理如下:
Add方法通过原子操作增加计数值。当执行 Add 方法时,首先将 delta 参数左移位,然后通过原子操作将其添加到计数值上。需要注意的是,delta 的值可正可负,用于在调用 Done 方法时减少计数值。
Done方法通过调用 Add(-1)来减少计数值。
Wait方法则持续检查 state 值。当计数值为零时,表示所有子goroutine已完成,调用者无需等待。如果计数值大于零,则调用者会变成等待者,加入等待队列,并阻塞自己,直到所有任务执行完毕。
通过使用waitGroup,开发者可以轻松地协调和同步并发任务的执行,确保所有任务按预期顺序完成。这在多goroutine协同工作时,尤其重要。掌握waitGroup的使用和源码实现,将有助于提高并发编程的效率和可维护性。
如果您对并发编程感兴趣,箱体振荡源码希望持续关注相关技术更新,请通过微信搜索「迈莫coding」,第一时间获取更多深度解析和实战指南。
入门篇:进程等待函数wait详解
前言:
编程过程中,有时需要让一个进程等待另一个进程,最常见的是父进程等待自己的子进程,或者父进程回收自己的子进程资源包括僵尸进程。这里简单介绍一下系统调用函数:wait()。
文章福利小编推荐自己的Linux内核源码交流群:整理了一些个人觉得比较好的学习书籍、视频资料共享在群文件里面,有需要的可以自行添加哦!!!前名可进群领取,并额外赠送一份价值的内核资料包(含视频教程、电子书、实战项目及代码)!
学习直通车: Linux内核源码/内存调优/文件系统/进程管理/设备驱动/网络协议栈
进程等待的作用:
进程等待的方法(如何让父进程进行进程等待):wait函数和waitpid函数
函数原型:
作用:进程一旦调用了wait,就会立刻阻塞自己,由wait分析当前进程中的某个子进程是否已经退出了,如果让它找到这样一个已经变成僵尸进程的子进程,wait会收集这个子进程的信息,并将它彻底销毁后返回;如果没有找到这样一个子进程,wait会一直阻塞直到有一个出现。参数statloc用来保存被收集进程退出时的一些状态,它是一个指向int型的指针。但如果对这个子进程是如何死掉的不在乎,咱们可以将它设置为NULL:pid = wait(NULL);如果成功,wait会返回被收集的子进程的进程ID,如果调用进程没有子进程,调用会失败,wait返回-1,同时errno会被设置为ECHILD。
运行后:
在第二次打印之前有十秒钟的reactor core 源码等待时间,这是我们设置的让子进程睡眠的时间,只有子进程睡眠后醒来,它才能正常退出,也就是能被父进程捕捉到。不管设置多长时间,父进程都会等待下去。
注意:
当父进程忘了用wait()函数等待已终止的子进程时,子进程就会进入一种无父进程的状态,此时子进程就是僵尸进程. wait()要与fork()配套出现,如果在使用fork()之前调用wait(),wait()的返回值则为-1,正常情况下wait()的返回值为子进程的PID. 如果先终止父进程,子进程将继续正常进行,只是它将由init进程(PID 1)继承,当子进程终止时,init进程捕获这个状态. 参数status用来保存被收集进程退出时的一些状态,它是一个指向int类型的指针。但如果我们对这个子进程是如何死掉毫不在意,只想把这个僵尸进程消灭掉,(事实上绝大多数情况下,我们都会这样想),我们就可以设定这个参数为NULL,就像下面这样: pid = wait(NULL); 如果成功,wait会返回被收集的子进程的进程ID,如果调用进程没有子进程,调用就会失败,此时wait返回-1,同时errno被置为ECHILD。 如果参数status的值不是NULL,wait就会把子进程退出时的状态取出并存入其中, 这是一个整数值(int),指出了子进程是正常退出还是被非正常结束的,以及正常结束时的返回值,或被哪一个信号结束的等信息。由于这些信息 被存放在一个整数的不同二进制位中,所以用常规的方法读取会非常麻烦,人们就设计了一套专门的宏(macro)来完成这项工作,下面我们来学习一下其中最常用的两个: 1,WIFEXITED(status) 这个宏用来指出子进程是否为正常退出的,如果是,它会返回一个非零值。 (请注意,虽然名字一样,这里的参数status并不同于wait唯一的参数–指向整数的指针status,而是那个指针所指向的整数,切记不要搞混了。) 2, WEXITSTATUS(status) 当WIFEXITED返回非零值时,我们可以用这个宏来提取子进程的返回值,如果子进程调用exit(5)退出,WEXITSTATUS(status) 就会返回5;如果子进程调用exit(7),WEXITSTATUS(status)就会返回7。请注意,如果进程不是正常退出的,也就是说, WIFEXITED返回0,这个值就毫无意义。
代码示例:wait.c
运行结果:
wait函数:pid_t wait (int* status)
在编码时有一个代码规范:
如果是输入型,参数定义成引用;
如果是输出或者输入输出参数,参数定义成指针;
wait函数的四个特性:
1.输出型参数,与其对应的有:
2.int* status是一个指针类型占四个字节,但是实际中只使用到后两个字节,将这两个字节分为三部分:
退出码:程序正常退出时用到
coredump标志位,退出信号是程序异常退出时用到:
用退出信号判断进程是否正常退出:
产生coredump文件不能判断进程是否正常退出的原因:
1.判断是否有退出信号
2.判断coredump标志位
3.判断退出码
使用wait函数阻止子进程变成僵尸进程
运行情况:
阻塞:
阻塞概念:当调用结果返回之前,当前的执行流会被挂起,并在得到结果之后返回
父进程一直在wait,并没有返回;
对阻塞和非阻塞理解:
1.子进程一种在运行;
2.子进程已退出
对于两种非阻塞的情况,父进程都是直接退出,但是两种情况父进程退出后,一种正常一种不正常
waitpid函数
wait函数的实现是调用waitpid函数实现
我爱内核网 - 构建全国最权威的内核技术交流分享论坛
原文地址: 进程等待函数wait详解 - 进程管理 - 我爱内核网(侵删)
精彩推荐:
如何理解Linux内核下的进程切换
玩转腾讯首发Linux内核源码《嵌入式开发笔记》,也许能帮到你哦
简要分析Linux下多进程的同步和互斥
[实战篇]红黑树在Linux内核中的应用
%Linux使用者都不知道的内存问题
从Linux源码看TIME_WAIT状态的持续时间
对于Linux系统中TIME_WAIT状态的Socket,长久以来,人们普遍认为其持续时间大约是秒。然而,在实际线上环境中,Socket的TIME_WAIT状态有时会超过秒。这个问题源于一个复杂Bug的分析,促使我深入Linux源码进行探究。
首先,了解下我们的Linux环境配置,特别是tcp_tw_recycle参数,这对TIME_WAIT状态的处理至关重要。我们设定了tcp_tw_recycle为0,以避免NAT环境下的特定问题。
接下来,让我们通过TCP状态转移图来理解TIME_WAIT状态。理论上,它会保持2MSL(Maximum Segment Lifetime,即最长报文段寿命)的时间。但具体时长并未在图中明确指出。在源码中,我发现了一个关键的宏定义TCP_TIMEWAIT_LEN,它定义了秒的销毁时间。
尽管之前我坚信秒的TIME_WAIT状态会被系统回收,但实际遇到的秒案例促使我重新审视内核对TIME_WAIT状态的处理。这个疑问将通过后续的博客分享答案。
深入源码,我们找到了TIME_WAIT定时器,它负责销毁过期的Socket。当Socket进入TIME_WAIT状态时,会触发特定的函数处理,如在不启用tcp_tw_recycle时,处理函数会直接调用inet_twsk_schedule。
内核通过时间轮机制管理TIME_WAIT状态,每个slot处理大约7.5秒的Socket。如果所有slot都被TIME_WAIT状态占用,可能会导致处理滞后。如果一个slot中的TIME_WAIT数量超过个,剩余的任务将交给work_queue处理,这会导致处理时间延长。
通过模拟,我们发现即使在slot处理完成后,整个周期可能已经过去了.5秒,这在NAT环境下可能导致问题。PAWS(Protection Against Wrapped Sequences)的保护机制可能会延长TIME_WAIT状态,使得Socket在特定情况下可以复用。
总的来说,对TIME_WAIT状态的深入理解需要避免刻板印象,因为实际情况可能因为复杂的机制而超出预想。在解决问题时,必须质疑既有的观点,这虽然艰难,但也是学习和成长的过程。
你应该知道的wait/notify那点事儿
Java的Object类中的wait()和notify()方法在多线程协作中起着关键作用,它们控制着线程间的等待、唤醒和切换。首先,了解线程的六种状态:新建、就绪、运行、阻塞、完成。接着,看一个代码示例:
看似平凡的代码,却隐藏着问题。当不正确使用synchronized时,wait()和notify()可能会导致异常。这是因为wait()需要在同步代码块中调用,以保证线程间的通信原子性,避免被中断。
当thread2调用wait后,如果thread1不释放锁,其他线程无法进入同步块。wait会释放锁,但唤醒后会重新获取,确保线程在被唤醒后继续执行。从JVM源码看,wait会放弃锁然后等待唤醒,notify则会选择一个线程唤醒,并尝试获取锁。
wait()可能会抛出InterruptedException,因为当其他线程调用interrupt()时,wait会在恢复时检查并抛出异常。调用notify()后,线程并不会立即执行,而是根据JVM的默认策略在同步代码块结束时唤醒。
至于性能影响,wait和notify使用park/unpark机制,不占用CPU,不影响系统性能。而监视器(Monitor)是每个对象的核心,控制着线程对对象的访问。进入区、拥有者和等待区的概念解释了线程如何在对象锁的控制下交互。
最后,要注意的是,Thread.sleep()方法会让线程休眠,但不释放监视器,这点与wait和notify不同。
wait函数和waitpid的使用和总结
当子进程退出时,Linux内核会通过SIGCHLD信号通知父进程。这种情况下,子进程转变为僵尸状态,仅保留基本数据结构以供父进程查询其退出详情。wait和waitpid函数分别用于处理这种情况。
wait函数的原型是:当调用后,进程会阻塞直到子进程退出,此时会收集子进程信息并销毁,然后返回。status参数可用来存储退出状态,若对详情不感兴趣,可设置为NULL。
waitpid函数则更具体,用于等待指定的进程结束。它支持参数status来获取子进程状态,以及选项如WNOHANG防止阻塞。Linux中可用的选项包括WNOHANG和WUNTRACED,它们可以组合使用。函数成功返回子进程pid,失败则返回-1。
了解这些函数的使用对于监控和管理进程至关重要。如果你对如何更深入地掌握,可以关注博主cs_wu在博客园上的文章,或者尝试c++项目实战课程,包括基础架构、SPDK、内核等技术,以提升专业技能。
有兴趣进一步学习内核技术的朋友,可以加入技术交流群获取资源,如内核源码学习路线和视频教程。点击链接获取更多详情和福利。


2024-11-18 21:12
2024-11-18 20:46
2024-11-18 20:20
2024-11-18 20:06
2024-11-18 19:45
2024-11-18 19:33
2024-11-18 18:52
2024-11-18 18:52