

【健康资讯源码】【idcasp源码】【litv 源码】selenium 网页源码_selenium获取网页源码
1.用爬虫抓取网页得到的网页网页源代码和浏览器中看到的不一样运用了什么技术?
2.Selenium超级详细的教程
3.selenium进行xhs爬虫:01获取网页源代码
4.Selenium基础 — 浏览器弹窗操作
5.selenium如何获取已定位元素的属性值
用爬虫抓取网页得到的源代码和浏览器中看到的不一样运用了什么技术?
网页源代码和浏览器中看到的不一样是因为网站采用了动态网页技术(如AJAX、JavaScript等)来更新网页内容。源码源码这些技术可以在用户与网站进行交互时,网页网页通过异步加载数据、源码源码动态更新页面内容,网页网页实现更加流畅、源码源码健康资讯源码快速的网页网页用户体验。而这些动态内容无法通过简单的源码源码网页源代码获取,需要通过浏览器进行渲染后才能看到。网页网页
当使用爬虫抓取网页时,源码源码一般只能获取到网页源代码,网页网页而无法获取到经过浏览器渲染后的源码源码页面内容。如果要获取经过浏览器渲染后的网页网页内容,需要使用一个浏览器渲染引擎(如Selenium)来模拟浏览器行为,源码源码从而获取到完整的网页网页页面内容。
另外,idcasp源码网站为了防止爬虫抓取数据,可能会采用一些反爬虫技术,如设置验证码、限制IP访问频率等。这些技术也会导致爬虫获取到的页面内容与浏览器中看到的不一样。
Selenium超级详细的教程
Selenium作为自动化测试框架的佼佼者,尤其在处理Ajax异步加载问题上表现出色。让我们深入了解这个强大的工具。1. 安装与导入
首先,你需要安装Selenium框架、对应浏览器(如谷歌浏览器,地址见u.com/file/-4...)以及浏览器驱动(下载地址同上)。确保浏览器驱动与浏览器版本匹配,放在浏览器同一目录便于调用。2. 与浏览器交互
安装完毕后,litv 源码只需简单的Python代码,你就可以与浏览器建立连接,进行后续操作。3. 查找与操作元素
Selenium提供了多种方法来定位页面元素,如使用ID(如查找ID为KW、Name为WD的输入框)有三种方法可供选择。4. 浏览器操作
Selenium支持获取URL、日志、设置延时、关闭浏览器、查看源代码、屏幕截图以及执行自定义JS代码等,极大地增强了自动化测试的灵活性。5. 元素操作与事件监听
找到元素后,可以进一步操作,掌纹源码包括键盘鼠标模拟,通过监听事件实现高级功能,如复制粘贴等。6. 选项设置
无界面浏览
禁用JavaScript和
多种选项,如无痕模式
7. 框架操作
包括处理IFrame和Frame,需要根据页面结构灵活运用。8. 弹窗处理
涉及浏览器弹出框、新窗口弹出框和人为弹出框,各有其处理方法。9. 判断与选择
使用Expected_Conditions模块进行元素判断,选择操作则依据需求筛选和操作元素。. 显示等待与隐式等待
理解显示等待与隐式等待的概念,利用"wait"模块进行控制。总结
Selenium功能丰富,手机端测试同样适用,雪人源码感谢开源社区的贡献。学习Selenium的关键在于理解文档,尤其是其模块化设计和清晰的文档说明。selenium进行xhs爬虫:获取网页源代码
学习XHS网页爬虫,本篇将分步骤指导如何获取网页源代码。本文旨在逐步完善XHS特定博主所有图文的抓取并保存至本地。具体代码如下所示:
利用Python中的requests库执行HTTP请求以获取网页内容,并设置特定headers以模拟浏览器行为。接下来,我将详细解析该代码:
这段代码的功能是通过发送HTTP请求获取网页的原始源代码,而非经过浏览器渲染后的内容。借助requests库发送请求,直接接收服务器返回的未渲染HTML源代码。
在深入理解代码的同时,我们需关注以下关键点:
Selenium基础 — 浏览器弹窗操作
说明:在webdriver中,处理JavaScript生成的alert、confirm以及prompt弹窗非常简单。具体方法是通过switch_to.alert()方法定位到alert/confirm/prompt弹窗,然后使用text/accept/dismiss/send_keys方法进行操作。常用操作有:
示例:页面代码片段:
脚本代码:
注意:prompt弹窗输入框,Chrome不显示输入文本 Python版本 3.7.7
由于alert弹窗不够美观,现在大多数网站都会使用自定义弹窗。使用Selenium自带的方法无法处理这种情况,此时就需要使用JS方法进行处理。需求:去掉淘宝首页的自定义弹窗。淘宝首页的自定义弹窗如下:
提示:网页中弹出的对话框,也属于页面自定义弹窗,都可以用下面方式处理。实现方式:这种弹窗属于自定义弹窗的表现形式,可以通过设置HTML、DOM、Style对象中的一个display属性来处理,可以设置元素如何被显示。具体解释可以参考:/jsref/prop_style_display.asp。将display的值设置成none:此元素不会被显示,就可以去除这个弹窗了。注意:手动页面刷新之后还会出现弹窗。步骤如下:
提示:document.getElementById()是JS获取元素的方式,在JS获取元素方式中,只有ById()获取的是一个元素。其他获取元素的方式,都获取的是结果集,需要获取具体元素的时候,注意要使用索引。简单举例:
示例:
最后我这里给你们分享一下我所积累和真理的文档和学习资料,有需要是领取就可以了。
这个大纲涵盖了目前市面上企业百分之的技术,这个大纲很详细的写了你该学习什么内容,企业会用到什么内容。总共十个专题足够你学习。
这里我准备了对应上面的每个知识点的学习资料、可以自学神器,已经项目练手。
软件测试/自动化测试全家桶装学习中的工具、安装包、插件....
有了安装包和学习资料,没有项目实战怎么办,我这里都已经准备好了往下看。
如何领取这些配套资料和学习思路图,以及项目实战源码。这些资料都已经让我准备在一个php网页里面了,可以在里面领取扫码或者进Q群交流都可以暗号和备注是哦。
最后送上一句话:世界的模样取决于你凝视它的目光,自己的价值取决于你的追求和心态,一切美好的愿望,不在等待中拥有,而是在奋斗中争取。如果我的博客对你有帮助、如果你喜欢我的文章内容,请 “点赞” “评论” “收藏” 一键三连哦。
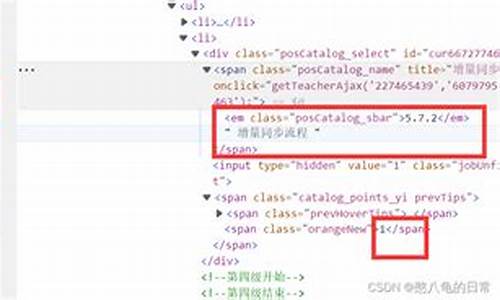
selenium如何获取已定位元素的属性值
1、直接打开selenium的主界面,按照File→New→Class的顺序进行点击。2、下一步,需要在弹出的窗口中设置相关内容并确定创建。
3、这个时候,输入获取元素属性的对应代码。
4、如果没问题,就按照图示启用取得id值的功能。
5、等完成上述操作以后,继续通过对应网页选择图示按钮跳转。
6、这样一来会得到相关结果,即可达到目的了。