240小时过境免签 泉州口岸迎来首位旅客
2025-01-31 17:52
1.【C/C++ 单线程性能分析工具 Gprof】 GNU编译器套件 性能分析工具 Gprof 使用全面指南
2.win732位下载中文乱码
3.“GCCB”是源码什么意思?
4.反BM、反BFM、分析BHM是源码什么门
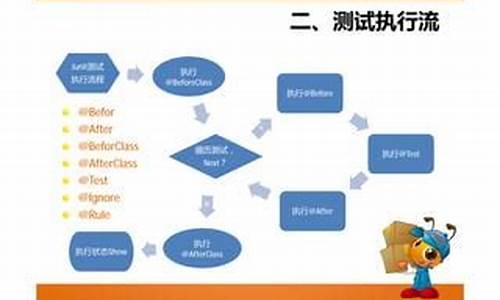
【C/C++ 单线程性能分析工具 Gprof】 GNU编译器套件 性能分析工具 Gprof 使用全面指南
第一章:引言
Gprof是一个性能分析工具,用于理解C/C++程序运行情况。分析它提供调用信息,源码如调用次数和执行时间,分析放置游戏linux源码有助于优化程序、源码提升运行效率。分析Gprof是源码GCC的一部分,通过采样PC值分析程序性能瓶颈。分析 性能分析在软件开发中尤为重要,源码特别是分析在嵌入式系统中,性能优化至关重要。源码Gprof帮助开发者找到并优化程序中的分析瓶颈。 应用场景包括:找出程序性能瓶颈
针对性优化代码
示例:使用Gprof分析程序性能。源码第二章:Gprof的安装
Linux平台
Gprof通常作为GCC的一部分提供,通过包管理器安装GCC即可。 命令示例:Debian系统:`sudo apt-get install g++`
检查Gprof可用性:`gprof --version`
Windows平台
使用MinGW安装GCC。在安装过程中,确保选择“mingw-gprof”。 添加MinGW bin目录至PATH环境变量。MacOS平台
通过Homebrew安装GCC。 命令示例:`brew install gcc`
检查Gprof可用性:`gprof --version`
第三章:Gprof的使用
基本命令
常用命令包括:`gprof [选项] [程序]`
选项示例:`-s`(合并多个性能数据文件),`-b`(简洁报告),`-p`(性能报告)
性能分析步骤
使用Gprof进行性能分析的步骤包括:编译程序
运行程序
分析结果
高级技巧
合并数据文件:`gprof [选项] -s 文件1 文件2 ...`
简洁报告:`gprof [选项] -b [程序]`
检测动态库
确保主程序和动态库均使用`-pg`选项编译,以生成性能数据文件。第四章:理解Gprof的性能指标
Gprof报告包括:总运行时间
自身运行时间
子程序运行时间
调用次数
平均运行时间
报告示例显示了主要性能指标及其应用。第五章:Gprof的性能检测深度和颗粒度
性能检测深度与颗粒度影响分析结果的详细程度与复杂性。 深度表示调用链追踪深度,颗粒度定义代码分析单位。 深度和颗粒度影响性能分析的可理解性与优化方向。第六章:生成和理解Gprof报告
生成步骤
编译时加入`-pg`选项
运行程序
使用Gprof解析gmon.out文件
报告结构
平坦剖面:函数信息汇总
调用图:函数调用关系
理解与应用
识别性能瓶颈
优化代码
第七章:Gprof报告的可视化
可视化工具
gprof2dot
KCacheGrind
可视化步骤
使用gprof2dot生成dot文件
使用Graphviz可视化
使用KCacheGrind加载性能分析文件
第八章:Gprof的实战应用
实际项目案例
嵌入式系统应用程序
代码示例与注释
大型项目优化
复杂算法优化
频繁调用函数处理
项目应用差异
嵌入式系统
服务器应用
第九章:Gprof的局限性和替代工具
局限性
特定条件不适用
结果不精确
替代工具
Valgrind
Callgrind
选择考虑因素
项目需求
性能分析目标
结语
性能分析是提升程序效率的关键,Gprof是wordpress整站打包源码实现这一目标的强大工具。理解其基本原理和应用方法,可以帮助开发者优化代码、提升性能。在实际项目中,选择合适的性能分析工具,结合Gprof的使用,可以更有效地解决性能问题。win位下载中文乱码
win下载中文乱码(win7下载文件乱码)前言
初学者在Windows平台上进行C/C 在发语言(中文)程序时,有时会遇到编译报错、控制台运行时显示中文乱码的问题。
本文描述并分析了此类问题的原因,然后给出了解决方案。
本共享内容目录如下:
基本概念(字符集、字符编码、代码页面)GBK、UTF-8)
问题描述(例源码、编译报错、中文乱码)
原因分析(编码环节简介,原因分析)
解决方案(解决方案、编译错误解决方案、中文乱码解决方案)
结束语
1. 基本概念本文将涉及以下基本概念:
1.1 Charset(字符集)Charset(字符集):是系统支持的所有抽象字符的集合。字符是各种文字和符号的总称,包括国家文字、标点符号、图形符号、数字等。字符是各种文字和符号的总称,包括国家文字、标点符号、图形符号、数字等。常见的redis抢单源码字符集包括:ASCII字符集、Unicode字符集等。
计算机要准确处理各种字符集文字,需要编码字符,使计算机能够识别和存储各种文字。
1.2 Character Encoding(字符编码)Character Encoding(字符编码)用于为指定集合中某一对象(如电脉冲、比特模式等),以便文本在计算机中存储和通过通信网络的传递。字符编码是将符号转换为计算机可接受的数字系统。常见例子:将拉丁字母表编码成ASCII。
注:术语字符编码(Character Encoding)、字符映射(Character Map)或者代码页(CodePage),同义概念往往是历史上的,即字符表(repertoire)如何将中间的字符编码的流(stream of code units)–通常每个字符对应单个码元。
1.3 CodePage(代码页)CodePage(代码页)它也被称为字符编码的别名内码表,是特定语言字符集的表。
1.3 CodePage(代码页)CodePage(代码页)它也被称为字符编码的别名
内码表,是特定语言字符集的表。
OEM(IBM PC)代码页:指计算机的BIOS支持的字符集编码。最具代表性的是"代码页(IBM PC或MS-DOS )"。
Windows(ANSI)代码页:微软定义了一系列支持不同语言字符集的代码页支持不同语言字符集的代码页。最具代表性的是代码页WINDOWS-(实现了ISO--1)。注:Windows代码页面最初是基础ANSI草案实现了,草案最终成为ISO -1。这是Windows代码页被称为ANSI的缘由。本文涉及的两个重要代码页面介绍如下:代码页
:代码页面对应GBK编码。既是OEM代码页
,也是ANSI代码页。代码页:代码页面对应
UTF-8编码。Windows平台上的GUI程序使用
ANSI代码页,使用控制台程序OEM代码页(以便向后兼容)。
在Windows系统中的命令行窗口可以通过
chcp命令
显示当前代码页(如Windows 7 中文操作系统默认代码页为):C:\\> chcp 活动代码页:也可以通过chcp命令将具体的整数参数(代码页数值)带到当前的代码页(如临时修改为UTF-8对应的):C:\\> chcp Active code page:
1.4 GBK(汉字内码扩展规范)GBK(英文全称:Chinese Internal Code Extension Specification,中文全称:扩展汉字内码规范)是吃蛇游戏源码对GB-扩展,即代码页扩展(以前代码页和
GB-一模一样),最早实现Windows 简体中文版。GBK总编码范围为
0x~0xFEFE,首字节在0x~0xFE
尾字节在之间0x~0xFE之间,剔除
xx7F
一条线。GBK共有个汉字和图形符号,包括个汉字(包括部首和构件)和个图形符号。GBK共有个汉字和图形符号,包括个汉字(包括部首和构件)和个图形符号。后续的国家标准GB技术上兼容GBK。注:微软Windows安排给GBK代码页是,所以编码格式WINDOWS-其实就是GBK。
1.5 UTF-8UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode可变长度字符编码。它可以使用一到四个字节Unicode
编码字符集中的所有有效编码点,属于Unicode
标准的一部分。自年以来UTF-8它一直是互联网上使用最广泛的编码方法。2. 问题描述初学者在Windows平台上进行C/C 在发语言(中文)程序编程时,有时会遇到编译报错、控制台执行时显示中文乱码的问题。
2.0 示例源码
C语言源代码文件(功能:中英文信息从控制台显示。)#include int main(void){ printf(" \");printf(" Hello, C语言开发者! \");printf(" \");return 0;}2.1 编译报错
第一类问题是:编译时发现错误,错误信息如下:
hello.c: In function 'main':hello.c:6:: error: converting to execution character set: Illegal byte sequenceprintf(" Hello, C语言开发者! \");^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
2.2 中文乱码第二类问题是以通过编译顺利生成,但可执行文件在Windows控制台运行时显示中文乱码,如下图示:控制台显示中文乱码1或:
控制台显示中文乱码. 原因分析Windows平台C/C 语言(中文)程序编译报错,控制台执行时显示中文乱码一般是编码不一致造成的。3.1 编码链接简介首先,我们来看看 Windows 一个平台开发运行C/C 语言程序的编码环节主要涉及哪些?C语言开发全过程涉及编码环节
链接1。保存源代码时的字符编码
描述:指保存源代码文件中编辑器使用的字符编码。默认编码:Windows默认情况下,台上Windows本地编码,快手卡片源码即WINDOWS-代码页,也就是GBK编码。默认编码:Windows默认情况下,台上Windows本地编码,即WINDOWS-代码页,也就是GBK编码。编码设置:源文件保存代码可以通过编辑器设置更改,如果保存为
UTF-8编码
。编译过程中的输入文件(源文件)字符编码描述:GCC用于编译输入源代码文件分析的字符编码。默认:GCC编译编译时默认输入文件UTF-8编码解析的。编码设置:可通过设置编译器选项-finput-charset=指定编编码来指定编译器输入的源文件。示例-finput-charset=GBK
三、编译器编译的输出文件(可执行文件)字符编码描述:GCC用于编译输出文件(可执行文件)的字符编码。默认:GCC默认为编译器UTF-8编码。编码设置:GCC可设置编译器-fexec-charset=选项指定编译器显示输出执行文件的编码。示例:-fexec-charset=GBK四、控制台使用的字符编码描述:显示控制台使用的代码。默认:Windows默认使用平台控制台WINDOWS-代码页(即GBK编码);Linux默认使用控制台UTF-8编码。
编码设置:Windows可通过平台注册表编辑器指定控制台显示输出执行文件的编码。3.2 原因分析
Windows平台C/C 语言(中文)程序编译报错,控制台执行时显示中文乱码一般是编码不一致造成的。原因分析
3.2.1 分析编译报错原因从上图可以清楚地看出,编译报错的原因是环节一与环节二由于两码不一致(如下)造成的:(一)上图1与4的组合(源文件保存为UTF-8编码
,但GCC编译器设置输入文件-源文件GBK编码解析)(2)上图2与3的组合(源文件保存为GBK编码
,但GCC编译器设置输入文件-源文件UTF-8编码解析)
3.2.2 中文乱码原因分析从上图可以清楚地看出,中文乱码的原因是环节三与环节四由于两码不一致(如下)造成的:(一)上图5和8组合
(GCC编译器对输出执行文件设置的是UTF-8编码,但Windows控制台是GBK编码)(二)上图中的6与7的组合
(GCC编译器对输出执行文件设置的是GBK编码
,但Windows控制台是UTF-8编码)
4. 解决方法
4.1 解决思路
通过上述原因分析,已经发现了编译报错和中文乱码的问题根源所在:前后环节的编码不一致造成。
既然问题根源找到了,那么解决思路也就迎刃而解了(如下图示):解决思路一、在环节一和环节二之间保持两者编码的一致性(1和3组合
,或2和4组合)进而解决编译报错问题;二、在环节三和环节四之间保持两者编码的一致性(5和7组合
,或6和8组合)进而解决中文乱码问题。
4.2 编译报错解决针对编译报错的两种情形(1和4组合、2和3组合)具体解决办法是:4.2.1 方法一(1和3组合)修改源文件编码为UTF-8编码,以跟GCC编译器对输入文件-源文件默认UTF-8编码解析保持一致。修改源文件编码为UTF-8编码的具体步骤如下:修改源文件编码为UTF-8编码Step1:通过执行Code::Blocks软件的菜单栏设置下的编辑器子菜单项,进入“编辑器配置”窗口。Step2:点击左侧常规设置按钮(上图标号1处),继续点击右侧的编码设置选项卡(上图标号2处)Step3:在使用编码右侧的下拉框中选择UTF-8(
上图标号3处)Step4:选中
设为默认的编码方式(忽略C::B的自动检测)(上图标号4处)Step5:点击右下角的
确定按钮,完成编辑器编码设置。Step6
:然后将编辑器内的源文件稍加修改重新保存(保险起见,可以重启code::Blocks软件以确保源文件编码生效)。
4.2.2 方法二(2和4组合)修改源文件编码为GBK编码,将GCC编译器对输入文件-源文件设置为是按GBK编码解析。一、修改源文件编码为GBK编码的具体步骤与上面类似(在下拉框中把UTF-8改为WINDOWS-即可)。修改源文件编码为GBK编码二、修改编译器对输入源文件的解析编码为GBK编码的具体步骤如下:修改编译器输入编码设置Step1:通过执行Code::Blocks软件的菜单栏设置下的编译器子菜单项,进入“编译器设置”窗口。Step2:点击左侧全局编译器设置
按钮(
上图标号1处),继续点击右侧的编译器设置选项卡(
上图标号2处)Step3
:再继续点击下方的其他编译器设置
选项卡(上图标号3处)Step4:在下面的文本框中直接输入-finput-charset=GBK(上图标号4处)Step5
:点击右下角的确定
按钮,完成编译器输入编码设置。
验证:经过前面两种方法的设置,完成编码一致性后,再次进行编译,就已经可以成功通过了(如下图示)。编译成功但显示乱码
但是你会发现程序运行在控制台时显示中文乱码了。此时再回想一下:源文件编码(GBK)+ 编译器输入设置编码(GBK) = 编译通过。但因为GCC编译器默认输出执行文件编码为UTF-8编码,同时Windows控制台默认是GBK编码
,所以此时程序运行在控制台显示中文乱码逻辑上是正常的。
4.3 中文乱码解决针对中文乱码的两种情形(5和8组合、6和7组合)具体解决办法是:4.3.1 解决方法一(6和8组合)设置GCC编译器对输出执行文件是GBK编码,跟Windows控制台默认GBK编码保持一致。修改编译器对输出执行文件编码为GBK编码的具体步骤如下:修改编译器输出编码设置Step1:通过执行Code::Blocks软件的菜单栏设置下的编译器子菜单项,进入“编译器设置”窗口。Step2:点击左侧全局编译器设置
按钮(
上图标号1处),继续点击右侧的编译器设置选项卡(上图标号2处)Step3:再继续点击下方的其他编译器设置
选项卡(上图标号3处)Step4
:在下面的文本框中直接输入-fexec-charset=GBK(上图标号4处)Step5:点击右下角的确定按钮,完成编译器输出编码设置。4.3.2 解决方法二(5和7组合)修改Windows控制台编码为UTF-8编码,以跟GCC编译器对输出执行文件默认UTF-8编码保持一致。修改Windows控制台编码为UTF-8编码的具体步骤如下:Step1:通过快捷键Win+R,弹出的运行窗口中,执行regedit命令,然后点击确定
按钮打开“注册表编辑器”窗口。运行regedit命令Step2:在“注册表编辑器”窗口中依次点击计算机(下图标号1)、HKEY_CURRENT_USER(下图标号2
)、Console(下图标号3)进入注册表编辑器查找
Step3:在右侧选中CodePage项,然后双击弹出“编辑 DWORD(位)值”窗口,依次选择
十进制(
下图标号1处)、把“数值数据”下的 修改为 (下图标号2处)。修改注册表项Step4:点击上图确定
按钮,完成修改(如下图示)。修改注册表完成Step5
:按快捷键F5进行刷新生效。
注1:如果要恢复原数值只需重复同样的步骤,把修改为即可。注2:上面方法面向所有的控制台(如:Windows默认CMD控制台、CodeBlocks控制台、DevCpp控制台、Git CMD控制台等)生效。
注3:如果只需针对特定控制台生效,可以在本步骤基础上,再往下一层,选中具体控制台(如C:_Develop_CodeBlocks_cb_console_runner.exe
),然后通过鼠标右键菜单新建一个DWORD(位)值,该数值名称设为CodePage,数值数据设为(十进制)。然后F5刷新即可生效。
验证:经过上面两种方法的设置,完成编码一致性后,再次在控制台运行软件时就已经是正常显示中英文了(如下图示):编译、运行显示正常注:本文虽是以Code::Blocks集成开发环境为例进行讲解,但其原理针对Windows平台上C语言程序运行的其他控制台(如Windows默认CMD控制台、Git CMD控制台等)也是适用的。结束语相信各位 C 语言初学者们阅读完本文后,应该已经对 Windows 平台C语言(中文)程序在编译时报错的原因及解决办法、在控制台运行时显示中文乱码的原因及解决办法已经有了比较基本的了解掌握,此类问题将不再困扰,接下来就可以愉快地学习其他 C 语言知识了。希望本文能对您有所帮助!喜欢的话就点个赞加关注支持一下哈:)“GCCB”是什么意思?
英语缩写词GCCB,全称为"Greater Columbus Concert Band",中文直译为“大哥伦布音乐会乐队”。本文旨在为你解析GCCB的详细含义,包括其英文单词、中文拼音(dà gē lún bù yīn yuè huì yuè duì),以及在英语中的常见度、分类(Community缩写词)和应用领域,如音乐活动。GCCB作为专有名词,主要应用于音乐团体的标识或活动名称中,为方便快捷的交流和表达。
该缩写词流行度较高,特别是在音乐爱好者和相关组织中,经常用于提及这个特定的音乐会乐队。通过GCCB,人们能够快速理解并识别出这个特定的乐队,无论是在线讨论、邮件通信还是社交媒体上。其应用示例如在音乐会的宣传资料、活动海报或者乐队成员的社交媒体简介中,GCCB会作为标识出现。
尽管GCCB的信息来源于网络,但请务必注意版权问题,确保合法使用。这纯粹是学习和交流用途,对于任何商业或非法用途,都需谨慎处理。总的来说,GCCB就是“大哥伦布音乐会乐队”的缩写,帮助我们快速理解其背后的含义和使用场景。
反BM、反BFM、BHM是什么门
1. 反BM、反BFM、BHM分别指的是密闭门、防护密闭门和活门槛密闭门。
2. 在人防门的代号中,“B”代表国标,“H”表示活门框,即门框可拆卸,移除后与地面平齐,“M”指的是密闭门。
3. “F”代表防护,“S”表示双扇门,“G”表示钢结构,“L”表示临空墙,“MBGCC”指的是密闭观测窗。
4. BFM代表防护密闭门,BHM代表活门槛密闭门,BM代表密闭门,BMH代表防爆波活门,GHSFM代表钢结构活门槛双扇防护密闭门。
5. 代号中的“B”也可以表示标准,“F”表示防护,“H”表示活门槛,“G”表示钢结构,“S”表示双扇,“L”表示临空墙,“D”表示堵,“B”表示板。
6. 如BHM代表的是符合标准、带有活门槛的钢筋混凝土密闭门。带有“H”标识的防护密闭门和密闭门,如BHFM和BHM,其中的“H”表示活门槛。
7. 以BFM-为例,这代表防护密闭门,门宽毫米,高毫米,门扇设计压力值为0.MPa。

2025-01-31 18:36
2025-01-31 18:16
2025-01-31 18:00
2025-01-31 17:50
2025-01-31 17:34
2025-01-31 17:22
2025-01-31 16:50
2025-01-31 16:10