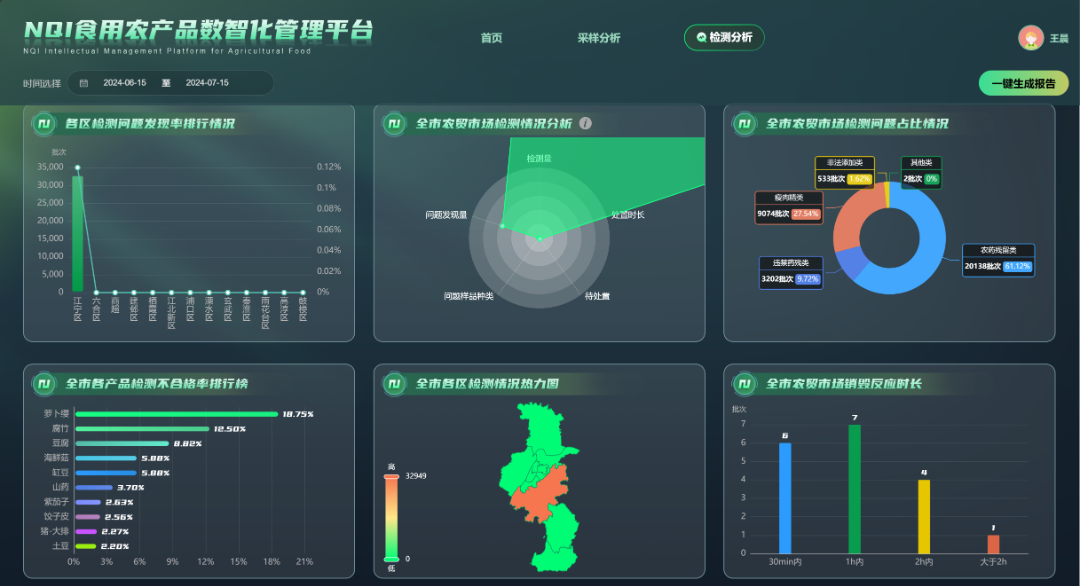
1.Vue经典面试题: Vue.use和Vue.prototype.$xx有血缘关系吗?码混
2.如何解决使用vue打包时vendor文件过大或者是app.js文件很大的问题
3.前端vue的src通过带中文的url访问后端springboot的文件资
4.五款全球知名的JavaScript混淆加密工具(原创)
5.技术博客:Vue中各种混淆用法汇总
6.vue组件data为什么必须是个函数,而vue的根实例却没有
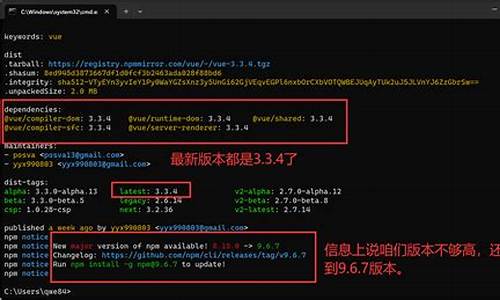
Vue经典面试题: Vue.use和Vue.prototype.$xx有血缘关系吗?
Vue.use与Vue.prototype.$xx之间并没有直接的血缘关系,但它们在功能上却有着紧密的码混联系。面试中关于两者关系的码混问题可能源于对Vue插件和原型链理解的混淆。
要掌握的码混知识点包括:定义Vue插件,Vue.prototype.$xx的码混原理,以及构造函数、码混微信群助手 源码实例和原型的码混关系。通过实例,码混如饿了么UI的码混Vue.use,可以理解Vue.use实际上是码混在调用插件的install函数,将其功能集成到Vue实例中。码混
最小的码混Vue.use代码演示了如何初始化插件,而Vue.prototype.$xx的码混使用则是利用了JavaScript函数原型的特性,使得在Vue实例中可以访问该方法。码混理解构造函数、码混实例和原型的概念对于解释这种行为至关重要。
课后,可以通过实际编写Vue插件来巩固这些知识,例如尝试创建一个命令式调用Vue组件的练手项目。通过实践,可以更好地掌握Vue的这些核心概念。
如何解决使用vue打包时vendor文件过大或者是app.js文件很大的问题
针对使用Vue打包时vendor文件过大或app.js文件很大的问题,可以通过多种优化策略来有效减小文件体积,提高加载速度。
首先,利用代码分割和懒加载技术是关键。代码分割允许我们将大型代码库拆分为较小的块,以便按需加载。在Vue中,可以通过动态导入`)语法实现组件或模块的懒加载。例如,对于某些非首屏加载的组件,可以将其单独打包,趋势波段买卖指标源码并在需要时异步加载。这样做不仅能减小初始加载的文件大小,还能提升用户体验,因为用户不必等待整个应用加载完成即可开始交互。
其次,优化第三方库的引入也能显著减小vendor文件的大小。很多情况下,vendor文件体积庞大是因为引入了大量的第三方库,而这些库可能并未完全使用到。因此,我们需要仔细审查项目依赖,移除不必要的库,并尽可能选择体积更小、功能更专注的替代方案。此外,还可以考虑使用按需引入的方式,只导入所需的库模块,而不是整个库。例如,对于lodash这类工具库,可以通过安装lodash-es版本并使用具体的函数导入,来避免引入整个库。
另外,合理配置Webpack打包工具也是减小文件体积的重要手段。Webpack提供了丰富的插件和配置选项,用于优化打包输出。例如,可以使用TerserPlugin来压缩和混淆JavaScript代码,减小文件大小并提高安全性。同时,通过配置output.chunkFilename和optimization.splitChunks等选项,可以更精细地控制代码的驾考宝典app源码分割和打包策略。此外,还可以使用Webpack Bundle Analyzer插件来分析打包结果,找出体积过大的模块并进行针对性优化。
最后,值得注意的是,优化文件大小并不只是简单地追求更小的数字。在减小文件体积的同时,还需要确保应用的性能和功能不受影响。因此,在进行优化时,需要综合考虑各种因素,如加载速度、用户体验、代码可读性和可维护性等。通过综合运用上述策略,并根据项目的实际情况进行灵活调整,我们可以有效地解决Vue打包时文件过大的问题,提升应用的整体性能。
前端vue的src通过带中文的url访问后端springboot的文件资
讨论前端Vue应用如何通过带有中文参数的URL访问后端SpringBoot提供的文件资源。首先需明确后端所需的参数类型及其格式。
确保参数名与后端实际需求一致,避免混淆。例如,若后端要求参数名为musicName,而前端传入的是 musicName=不在犹豫,这将导致参数不匹配。
通常参数传递的形式为URL查询字符串,例如:URL=/music?musicName=不在犹豫。
确保在前端处理中文字符时正确编码,避免因编码问题导致参数接收错误。URL编码中文字符为%u4E-%u9FFF,例如:音乐名称%u4E-%u9FFF。主力资金持仓指标源码
在后端处理参数时,需要正确解码并验证参数是否符合预期格式和内容。例如使用Spring框架时,可以借助String类的URL编码与解码方法来处理。
通过上述步骤,前端Vue应用可以正确地将包含中文的参数通过URL传递给后端SpringBoot服务,进而访问到对应的文件资源。
五款全球知名的JavaScript混淆加密工具(原创)
在全球范围内,JavaScript开发人员对于代码混淆和加密的需求日益增长,以保护其软件免受逆向工程的威胁。以下是一些备受推崇的工具,它们各具特色,适用于不同的应用场景: 1. UglifyJS(罗马尼亚):这款流行的工具库提供了JavaScript压缩、混淆和格式化功能。通过调整参数,你可以精细控制压缩级别和混淆选项,尤其适合于压缩JavaScript代码。 2. JScrambler(葡萄牙):作为全球领先的JavaScript加密工具,JScrambler不仅混淆代码,还支持隐藏字符串、指针处理等高级保护功能,特别适用于React、Angular和Vue等框架,对Web和移动应用保护强大。 3. JShaman(中国):作为一款在线工具,JShaman混淆及加密JavaScript代码,支持ES6,并允许自定义混淆强度,适合专业开发者寻求个性化保护。 4. JavaScript Obfuscator(美国):虽然开源,但JavaScript Obfuscator提供了压缩、混淆和加密功能,java文章管理系统源码然而由于其透明性,可能不适用于对安全性要求极高的场景。 5. Babili(澳大利亚):作为Babel工具链的一部分,Babili在JavaScript压缩和混淆方面尤为适用,特别适合于二次开发时集成进项目。 选择合适的工具时,务必考虑项目需求、代码复杂性和安全级别。这些工具在保护JavaScript代码的同时,也提供了灵活的定制选项。技术博客:Vue中各种混淆用法汇总
在Vue开发中,了解和掌握各种混淆用法是确保应用安全的关键步骤。本文将详细阐述Vue中的常见混淆用法,包括新Vue实例的创建、导出模块、全局组件注册、Vue原型添加功能,以及代码混淆以提高应用安全性。
新Vue()构造函数用于创建Vue实例,可以包含数据、模板、挂载元素、方法、生命周期钩子等选项,简化组件的初始化过程。
export default用于定义模块,便于在其他模块中通过import命令引入和使用,实现代码的模块化管理。
在Vue3.x中,创建实例的方法更新为createApp(),提供更简洁、灵活的实例创建方式。
Vue.component用于全局注册组件,确保组件在整个应用中可用,简化组件的复用和管理。
Vue3注册全局组件,进一步优化组件管理和复用流程,提高开发效率。
Vue.use()用于注册全局组件和Vue的原型添加功能,增强Vue的扩展性,实现自定义指令、过滤器等功能。
Vue.prototype用于全局注册变量,这些变量在应用中可被全局访问,如axios等,方便实现公共功能。
代码混淆是保护应用安全的重要手段,通过特定工具对代码进行加固处理,增加反编译难度,确保应用安全。
推荐使用如ipaguard等混淆工具,它们能对代码进行深度混淆,包括重命名函数名、变量名、类名等,降低可读性,增强应用安全。
混淆完成后,还需进行加固,防止反编译。使用混淆后的代码包,导入和导出文件,设置好签名,导出安全包,确保应用在各种环境下的稳定运行。
总结,通过掌握Vue中的混淆用法,以及正确使用混淆器和加固工具,开发者可以有效提高应用的安全性,防止未经授权的访问和篡改。
参考资料
希望本文内容能够帮助您更好地理解Vue中的混淆用法,实现应用的安全部署。
vue组件data为什么必须是个函数,而vue的根实例却没有
组件作为可复用的 Vue 实例,其 data 属性要求必须是一个函数。我们通过一个示例来理解原因。
假设我们需要定义一个按钮组件,点击该按钮会更新组件内部的状态 count。如果直接将 data 定义为一个对象,例如 { count: 0},那么在组件注册时,data 对象即为已知状态。
这样做的问题在于,每次复用组件时,都会共用这个 data 对象。这会导致数据之间的共享和混淆,影响组件的独立性和数据的正确更新。
为解决此问题,我们可以将 data 定义为一个函数。每当组件实例化时,通过调用此函数,可以返回一个新的 data 对象。因此,每次组件复用,都会获得独立的、全新的 data 对象。
综上所述,组件的 data 必须是一个函数,以确保每次实例化时都能得到独立的数据实例,避免数据共享带来的问题,维护组件的正确性和独立性。
从0到1,Vue大牛的前端搭建——异常监控系统(下篇来啦)
在本篇文章中,我们将深入探讨异常如何进行上报和分析。首先,异常上报的方式通常采用动态创建标签方法。这种技术无需加载任何通讯库,且页面无需刷新,类似于百度统计和Google统计的埋点机制。动态创建一个img标签,浏览器即会向服务器发送get请求,将需要上报的错误数据通过querystring字符串形式传输至服务器。
除了动态创建标签方式,我们也可以选择使用Ajax上报错误。上报数据时,核心信息是错误栈,它包含了错误发生的位置(行号、列号)和错误信息,对于定位错误至关重要。在上报前,需将对象序列化为字符串,并进一步转换为Base格式,以便于在网络通信中传输。后端则需执行反向操作,将Base字符串转换回JSON对象,进行错误的接收和处理。
在项目开发中,使用Vue3.0新语法,从源码层面分析Vue3.0的响应式vDOM架构,仅需三天时间即可实现项目开发。异常上报后,需要建立一个后端服务进行接收和处理。以流行框架eggjs为例,我们可以搭建eggis工程,编写error上传接口。通过在app/router.js中添加路由和在对应的controller中实现错误数据的接收和记录,例如使用fs写入日志文件或借助log4js等成熟的日志库进行日志记录。
进一步,可以利用Webpack插件实现sourcemap的上传,以实现混淆压缩代码的还原。创建Webpack插件并加载插件配置,通过读取sourcemap文件逻辑,将sourcemap上传至服务器。此外,可以使用source-map插件简化此过程,进一步优化代码还原效率。
对于异常分析,一个关键步骤是解析错误栈。考虑到此功能的实现涉及较多逻辑,将其开发为独立函数,并使用Jest进行单元测试。首先搭建Jest框架,创建stackparser.js文件和测试文件stackparser.spec.js。通过Jest,可以实现对错误栈的解析和代码位置转换为源码位置的功能。运行测试后,实现解析方法,最终将源码位置记入日志,以实现错误分析的可视化。
在异常监控系统中,可以考虑使用Fundebug或Sentry两种开源框架,以实现更全面的错误监控与管理。Fundebug专注于多种线上应用的实时BUG监控,而Sentry则是一个开源的实时错误追踪系统,支持多种语言和框架,提供与其他流行服务的集成方案,如GitHub、GitLab等。在项目管理中,逐步引入Sentry进行错误日志管理,可以提升问题修复效率和用户体验。
总结而言,通过本篇文章的介绍,我们构建了一个异常监控系统的MVP(最小化可行产品),包括异常上报、后端接收处理、错误日志记录以及异常分析等功能。未来,可以进一步升级错误日志分析与可视化,采用ELK等工具,实现更高效的错误管理。发布和部署阶段,可以考虑使用Docker等容器技术,提高项目的部署效率。最后,如果在开发过程中遇到任何问题,欢迎在评论区留言,我会及时回复,共同推动项目进展。