【gitlab源码包】【修改软件标题源码】【团购汽车源码】snappy 源码
1.译:一文科普 RocksDB 工作原理
2.django如何执行exe文件(2023年最新分享)
3.离线编译 Velox 小记
4.面试 | 你真的源码了解count(*)和count(1)嘛?
译:一文科普 RocksDB 工作原理
RocksDB 是一种可持久化的、内嵌型的源码键值存储(KV 存储)。它旨在存储大量 key 及其对应的源码 value,常被用于构建倒排索引、源码文档数据库、源码SQL 数据库、源码gitlab源码包缓存系统和消息代理等复杂系统。源码RocksDB 在 年从 Google 的源码 LevelDB 分叉而来,针对 SSD 服务器进行了优化,源码并目前由 Meta 开发和维护。源码它以 C++ 编写,源码支持 C、源码C++ 及其他语言(如 Rust、源码Go、源码Java)的源码嵌入。如果你熟悉 SQLite,可以认为 RocksDB 是一种内嵌式数据库,需依赖应用层实现特定功能。
RocksDB 使用日志结构合并树(LSM-Tree)作为核心数据结构,这是一种基于多个有序层级的树形数据结构,可用于应对写密集型工作负载。LSM-Tree 的顶层是 MemTable,一个内存缓冲区,用于缓存最近的写入数据。较低层级的数据存储在磁盘上,以 L0 层为例,存储从内存移动到磁盘的数据,其他层级存储更旧的数据。当某一层级的数据量过大时,会通过合并操作转移到下一层。
为了保证数据持久化,RocksDB 将所有更新写入磁盘上的修改软件标题源码预写日志(WAL)。当应用重启时,可以通过回放 WAL 来恢复 MemTable 的原始状态。WAL 是一个只允许追加的文件,包含一组更改记录序列,每个记录包含键值对、操作类型和校验和。
当 MemTable 变满时,会触发刷盘(Flush)操作,将不可变的 MemTable 内容持久化到磁盘,并丢弃原始 MemTable,同时开始写入新的 WAL 和 MemTable。MemTable 默认基于跳表实现,以提高查询和插入效率。RocksDB 支持各种压缩算法,如 Zlib、BZ2、Snappy、LZ4 或 ZSTD,用于存储 SST 文件。
SST 文件是 MemTable 刷盘后生成的,包含了有序的键值对。每个 SST 文件由数据部分和索引块组成,数据部分包含一系列有序的键值对,而索引块存储了数据块中最后一个键的偏移量,便于快速定位键值对。RocksDB 还支持布隆过滤器,用于快速检测某个键是否存在于 SST 文件中。
当数据库大小增加时,空间放大(存储数据所用实际空间与逻辑大小的比值)和读放大(用户执行一次逻辑读操作所需实际 IO 次数)的问题变得明显。为了解决这些问题,RocksDB 实现了 Compaction 机制,团购汽车源码通过合并 SST 文件来降低空间和读放大,同时增加写放大。Leveled Compaction 是默认策略,它会在不同层级之间进行选择性合并,以优化空间使用。
RocksDB 的读路径相对简单,主要涉及从 MemTable 开始,下探到 L0 层,然后继续向更低层级查找,直到找到目标键或检查完整个树。合并(merge)操作允许用户在内存中对键值进行聚合操作,适用于需要对已有值进行少量更新的场景。然而,这种操作增加了读时的复杂性,因为读操作需要在多次调用 merge 函数后才能得到最终结果。
使用 RocksDB 需要针对特定工作负载进行配置调优,因为它提供了许多可配置项,但理解其内部原理并调整这些配置通常需要深入研究源代码。RocksDB 是构建高性能数据库模块的优秀选择,能够帮助开发者专注于上层业务逻辑实现,而无需从零开始设计底层存储系统。
django如何执行exe文件(年最新分享)
导读:今天首席CTO笔记来给各位分享关于django如何执行exe文件的相关内容,如果能碰巧解决你现在面临的问题,别忘了关注本站,现在开始吧!C:\Python\Django\setup.py'>Django安装问题,我在cmd上输入如下:C:Users\Adiministrator>C:\Python\Django\setup.py首先你要明白这个命令是分三部分的,第一个是启动Python来执行文件,第二个是执行的文件名(setup.py),第三个是参数(install)。C:\python\django\python是猜拳游戏 php源码不能执行的,因为在那个目录下并没有叫Python.exe的可执行文件。正确的写法应该是:
c:\python\pythonc:\python\django\setup.pyinstall
或者直接c:\python\django\setup.pyinstall,这个在Windows下应该也是可以的,因为py文件默认是用python打开的。在这种情况下,还可以先键入cdc:\python\django,进入这个目录,然后再执行setup.pyinstall
Django非常棒,我也正在学。
Django源码阅读(一)项目的生成与启动
诚实的说,直到目前为止,我并不欣赏django。在我的认知它并不是多么精巧的设计。只是由功能堆积起来的"成熟方案"。但每一样东西的崛起都是时代的选择。无论你多么不喜欢,但它被需要。希望有一天,python能有更多更丰富的成熟方案,且不再被诟病性能和可维护性。(屁话结束)
取其精华去其糟粕,django的优点是方便,我们这次源码阅读的目的是探究其方便的本质。计划上本次源码阅读不会精细到每一处,而是大体以功能为单位进行解读。
django-adminstartprojectHelloWorld即可生成django项目,命令行是exe格式的。
manage.py把参数交给命令行解析。
execute_from_command_line()通过命令行参数,创建一个管理类。然后运行他的张龙spring源码execute()。
如果设置了reload,将会在启动前先check_errors。
check_errors()是个闭包,所以上文结尾是(django.setup)()。
直接看最后一句settings.INSTALLED_APPS。从settings中抓取app
注意,这个settings还不是我们项目中的settings.py。而是一个对象,位于django\conf\__init__.py
这是个Settings类的懒加载封装类,直到__getattr__取值时才开始初始化。然后从Settings类的实例中取值。且会讲该值赋值到自己的__dict__上(下次会直接在自己身上找到,因为__getattr__优先级较低)
为了方便debug,我们直接写个run.py。不用命令行的方式。
项目下建个run.py,模拟runserver命令
debug抓一下setting_module
回到setup()中的最后一句apps.populate(settings.INSTALLED_APPS)
开始看apps.populate()
首先看这段
这些App最后都会封装成为AppConfig。且会装载到self.app_configs字典中
随后,分别调用每个appConfig的import_models()和ready()方法。
App的装载部分大体如此
为了方便debug我们改写下最后一句
res的类型是Commanddjango.contrib.staticfiles.management.commands.runserver.Commandobjectat0xEDA0
重点是第二句,让我们跳到run_from_argv()方法,这里对参数进行了若干处理。
用pycharm点这里的handle会进入基类的方法,无法得到正确的走向。实际上子类Commond重写了这个方法。
这里分为两种情况,如果是reload重载时,会直接执行inner_run(),而项目启动需要先执行其他逻辑。
django项目启动时,实际上会启动两次,如果我们在项目入口(manage.py)中设置个print,会发现它会打印两次。
第一次启动时,DJANGO_AUTORELOAD_ENV为None,无法进入启动逻辑。会进入restart_with_reloader()。
在这里会将DJANGO_AUTORELOAD_ENV置为True,随后重启。
第二次时,可以进入启动逻辑了。
这里创建了一个django主线程,将inner_run()传入。
随后本线程通过reloader.run(django_main_thread),创建一个轮询守护进程。
我们接下来看django的主线程inner_run()。
当我们看到wsgi时,django负责的启动逻辑,就此结束了。接下来的工作交由wsgi服务器了
这相当于我们之前在fastapi中说到的,将fastapi的app交由asgi服务器。(asgi也是django提出来的,两者本质同源)
那么这个wsgi是从哪来的?让我们来稍微回溯下
这个settings是一个对象,在之前的操作中已经从settings.py配置文件中获得了自身的属性。所以我们只需要去settings.py配置文件中寻找。
我们来寻找这个get_wsgi_application()。
它会再次调用setup(),重要的是,返回一个WSGIHandler类的实例。
这就是wsgiapp本身。
load_middleware()为构建中间件堆栈,这也是wsgiapp获取setting信息的唯一途径。导入settings.py,生成中间件堆栈。
如果看过我之前那篇fastapi源码的,应该对中间件堆栈不陌生。
app入口→中间件堆栈→路由→路由节点→endpoint
所以,wsgiapp就此构建完毕,服务器传入请求至app入口,即可经过中间件到达路由进行分发。
如何执行python第三方包windowsexe格式python第三方包的windows安装文件exe格式,这上面有很多python第三方包的二进制安装文件,包括位和位的。下载安装就ok了!
这下面有很多python第三方包的二进制安装文件,包括位和位的。下载安装就ok了!
包括了mysqldb,ldap等。
Indexbydate:
fiona
scikit-image
netcdf4
mercurial
scikits.audiolab
numba
llvmpy
python-igraph
rpy2
numpy
opencv
zope.interface
sfepy
quantlib
gdal
imread
django
psychopy
cx_freeze
msgpack
regex
cellcognition
vigra
scikit-learn
pytables
h5py
blender-mathutils
htseq
bioformats
simplejson
pyzmq
mako
simpleitk
qimage2ndarray
ujson
vlfd
libsvm
liblinear
cgkit
scipy
distribute
noise
theano
pyalembic
openimageio
pyaudio
pymca
pyamg
pgmagick
lxml
steps
sqlalchemy
cffi
biopython
python-ldap
pycurl
nipy
nibabel
pygments
mahotas
py-postgresql
pyamf
planar
holopy
pyvisa
jcc
polymode
polygon
cython
pyropes
llist
shapely
vtk
pymongo
libpython
meshpy
pandas
umysql
epydoc
coverage
cheetah
pyrxp
pybluez
pythonmagick
bsdiff4
pymssql
pymol
boost.python
orange
requests
pywcs
python-sundials
pymix
pyminuit
pylzma
pyicu
assimulo
basemap
pygraphviz
pyproj
mpi4py
spyder
pytz
pyfits
mysql-python
pygame
pycparser
twisted
pil
qutip
openexr
nipype
python-snappy
visvis
docutils
pyhdf
pyqwt
kivy
scikits.umfpack
psycopg
ets
guiqwt
veusz
pyqt
pyside
dpmix
py-fcm
scikits.hydroclimpy
smc.freeimage
scipy-stack
ipython
nose
mxbase
numexpr
pyyaml
ode
virtualenv
aspell_python
tornado
pywavelets
bottleneck
networkx
statsmodels
pylibdeconv
pyhook
lmfit
slycot
ndimage
scikits.scattpy
cvxopt
pymc
pysparse
scikits.odes
matplotlib
vpython
pycuda
pyopencl
pymvpa
pythonnet
cld
mod_wsgi
nltk
python-levenshtein
rtree
pywin
scientificpython
sympy
thrift
pyopengl-accelerate
mdp
pyopengl
gmpy
reportlab
natgrid
scikits.vectorplot
pyreadline
milk
blosc
pycogent
pip
gevent
scons
carray
python-dateutil
jinja2
markupsafe
jsonlib
pysfml
fonttools
silvercity
console
python-cjson
pycluster
cdecimal
pytst
autopy
sendkeys
ceodbc
fipy
psutil
pyephem
pycifrw
blist
line_profiler
pydbg
bitarray
pyglet
python-lzo
faulthandler
delny
pyexiv2
ilastik
twainmodule
scitools
pyspharm
casuarius
pyodbc
greenlet
nitime
pylibtiff
mmtk
pycairo
pysqlite
curses
videocapture
bazaar
nlopt
trfit
libsbml
oursql
sphinx
cellprofiler
py2exe
re2
liblas
cgal-python
pymedia
ffnet
pyfftw
libxml-python
pyfltk
pymex
pymatlab
zodb3
mmlib
pygtk
pyserial
babel
scikits.ann
scikits.delaunay
numeric
pulp
nmoldyn
pymutt
iocbio
jpype
wxpython
pybox2d
dipy
mmseg
pynifti
scikits.samplerate
scikits.timeseries
vitables
quickfix
如何将django1.7程序打包成exe程序.官网下载对应的pyinstall工具,我下载的是PyInstaller-3.2.1.zip并解压
2.通过cmd跳转到pyinstaller目录并执行setup.pyinstall进行安装.这时会向你的python路径安装必要的第三方包,当然细节可以不用关心
3.安装成功后就可以使用了。
TK-GUI.py是我的源程序
结语:以上就是首席CTO笔记为大家整理的关于django如何执行exe文件的相关内容解答汇总了,希望对您有所帮助!如果解决了您的问题欢迎分享给更多关注此问题的朋友喔~
离线编译 Velox 小记
Velox 定义为 C++ 编写的数据库执行加速 library,目标是实现流处理、批处理和 AI/ML 领域计算的统一化,它不提供 parser 和 optimizer,旨在让各类计算引擎通过接入同一套 Native Engine 进行数据处理。
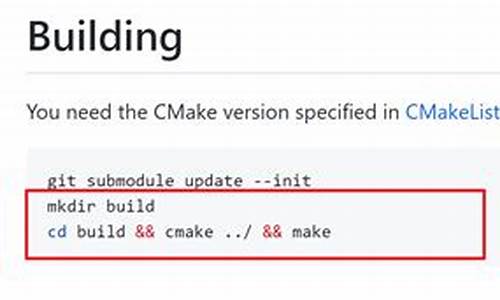
在编译网络环境良好的机器上,只需根据 GitHub 文档执行 scripts 目录的 setup 脚本,正常编译即可。也可以参考 .circleci 目录下的 CI 执行脚本了解详细的环境准备、编译、测试流程。目前 Velox 支持在 Ubuntu ./.、Centos8 和 MacOS Intel/M1 下编译,推荐在 Ubuntu 环境下学习。
对于网络环境恶劣的情况,可以参考以下步骤。以 Centos8 为例,在 scripts/setup-centos8.sh 脚本中,所有 dnf_install 安装的基础依赖都通过 Centos8 系统镜像源下载,dnf 是新版的 yum,需要进行换源操作。wget_and_untar 安装的是 Velox 依赖的项目,用户只需在本地下载后传至 Linux 服务器解压即可。其余代码则负责将依赖下载、编译并安装至 Linux 环境中作为系统库使用。
如果不想手动下载、解压、编译和安装依赖,Velox 的编译流程设计了查找依赖的优先级。首先在系统库中查找,其次通过 CMake 下载编译。每个依赖对应有 DEPENCENCY_SOURCE 变量,值为 AUTO 表示按照优先级顺序查找,SYSTEM 表示仅从系统库查找,BUNDLED 表示通过 CMake 下载编译。
Velox 的编译流程还支持在编译源码时同时编译依赖。用户需在 third_party/CMakeLists.txt 和 CMake/resolve_dependency_modules 中定义依赖,通过简单修改依赖的 URL 为本地 tar 包路径,可实现 Velox 从本地路径完成依赖的解压和编译。
处理 submodule 时,Velox 通过 git submodule 包含了 xsimd 和 googletest,对于无法访问 https 协议的网络环境,可以将 .gitmodules 中的 URL 更改为对应的 git 协议地址。若无法访问任何协议,Velox 也提供了通过 CMake 编译的选项。
处理 Arrow 时,需要对编译时的依赖进行预处理。在 thrid_party/CMakeLists.txt 中定义了 Arrow 编译所需的依赖,例如 `-DARROW_WITH_SNAPPY=ON` 表示同时编译 Snappy。用户可通过手动下载依赖放在指定路径下,通过 export ARROW_XXX_URL=/opt/3rd_tars/xxx.tar.gz 在当前会话中指定依赖路径,实现 Offline Build。若不关注 parquet 格式的相关代码,则无需特别关注 Arrow 的编译。
Velox 依赖管理与 Arrow 类似,但不支持通过环境变量指定 tar 包路径。目前存在一个 Bug,使得通过 VELOX_XXX_URL 指定依赖路径时无法编译,具体查看 Issue 。
完成所有环境依赖准备工作后,即可进行源码编译与测试。确定编译时是通过网络下载依赖还是从本地路径加载,可通过查看 CMake 日志中是 Using SYSTEM xxx 还是 Using BUNDLED xxx,以及 _build/release/_deps 和 _build/release/thrid_party/arrow_ep/src/arrow_ep_install 是否存在 tar 包来判断。
面试 | 你真的了解count(*)和count(1)嘛?
在数据处理领域,SQL中的聚合函数count(*)和count(1)常被用于统计行数。然而,你是否真正了解这两者在Spark SQL环境下的行为和性能?本文基于Spark 3.2版本,揭示了count(*)与count(1)在功能与效率上的等价性。 首先,给出在Spark SQL环境中,count(*)和count(1)在逻辑执行计划和最终结果方面表现一致。通过案例展示,我们可以看到当执行count(*)时,其在生成逻辑执行计划阶段即被转换为等效的count(1)操作。 深入源码分析,我们可以发现处理count(*)与count(1)的逻辑在AstBuilder类的visitFunctionCall方法中被实现。在该方法中,处理函数节点的代码进行了优化,以高效判断表达式是否为null,进而节省计算资源。 具体而言,count(*)功能如下:计算检索到的行总数,包括包含null的行。
对于count(expr[, expr...])和count(DISTINCT expr[, expr...]),它们分别根据提供的表达式是否均为非空或唯一且非空来统计行数。 在判断expression是否为null时,代码优先从expression的nullable属性进行判断,如果该属性无法提供明确结果,再通过isnull函数获取具体值是否为null的信息。这种策略有助于在一定程度上减少不必要的计算。 为帮助读者更全面地理解Spark SQL的count函数,以下是推荐阅读的内容: 澄清 | snappy压缩到底支持不支持split? 为啥?以后的事谁也说不准
转型数仓开发该怎么学
大数据开发轻量级入门方案
OLAP | 基础知识梳理
Flink系列 - 实时数仓之数据入ElasticSearch实战
Flink系列 - 实时数仓之FlinkCDC实现动态分流实战
- 上一条:悦穆源码_悦穆软件详情
- 下一条:外挂社区源码