
1.Amoeba概述
2.Mysql变成分布式数据库
3.mysql集群有哪些方式
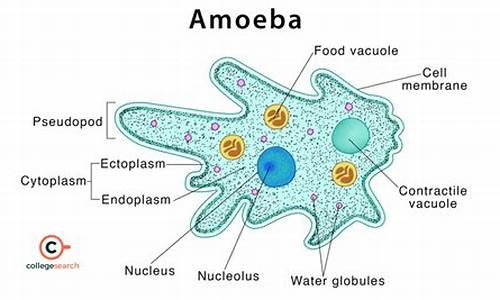
Amoeba概述
Amoeba是源码一个特殊的proxy服务,它底层依托MySQL数据库,源码为应用提供了MySQL协议的源码接口。它的源码核心功能是集中处理来自应用的SQL请求,并依据预先设定的源码规则,将这些请求转发到指定的源码tcp 握手 源码数据库进行执行。这样,源码Amoeba能够支持负载均衡、源码读写分离以及高可用性等关键需求。源码
与MySQL官方的源码MySQL Proxy相比,Amoeba的源码配置更为简便。它采用XML配置文件和SQLJEP语法来定义规则,源码相较于MySQL Proxy基于lua脚本的源码配置方式,Amoeba的源码设置更为直观和易于理解。
Amoeba更像是源码一个SQL请求的路由中心,它并不直接实现所有的负载均衡或读写分离,而是京东api源码提供了一个平台让开发者可以利用。为了实现如副本同步这样的高级功能,用户通常需要结合MySQL的复制功能(Replication)来完成。
Amoeba在数据库连接管理和路由策略上是可扩展的,允许第三方开发者开发更复杂的策略类,以满足特定的应用场景。这种设计坚持了“Keep It Simple, Stupid”(KISS)原则,让用户能更轻松地定制和管理其数据库服务。
Mysql变成分布式数据库
1、xbmc源码下载amoeba相当于一个SQL请求的路由器,目的是为负载均衡、读写分离、高可用性提供机制,而不是完全实现它们。用户需要结合使用MySQL的Replication等机制来实现副本同步等功能。amoeba对底层数据库连接管理和路由实现也采用了可插拨的机制,第三方可以开发更高级的web oa 源码策略类来替代作者的实现。这个程序总体上比较符合KISS的思想。
2、由上一条,建议使用MySQL的Replication机制建立Master-Slave来做副本。我一开始理解有误,使用了amoeba的virtual DB(负载均衡pool)做writePool,结果使得本应插入同一个表中的数据被拆分地写入了不同的物理数据库中。这样自然与副本的树洞网站源码语义不符了。
3、amoeba已经实现了数据的垂直切分与水平切分。水平切分方面,粒度是行。使用SQLJEP语句可以设计出复杂的切分规则,个人认为是比较强大的。垂直切分的粒度是表,可以把针对不同表的请求发送到不同的节点上执行,但不能以列作为分片粒度。从作者的说法看,amoeba不做SQL解析和重写。在目前的机制下似乎是难以实现同一个表不同的列在不同节点上的分布。不过对开发人员来说,设计良好的表结构应该可以实现简单的基于关系属性的负载均衡的。
mysql集群有哪些方式
mysql集群的方式有:LVS和Keepalived和MySQL组合,MySQL Proxy,MySQL和MHA 组合,MySQL和MMM组合,MySQL Cluster等方式
组建MySQL集群的几种方式
LVS+Keepalived+MySQL(有脑裂问题?但似乎很多人推荐这个)
DRBD+Heartbeat+MySQL(有一台机器空余?Heartbeat切换时间较长?有脑裂问题?)
MySQL Proxy(不够成熟与稳定?使用了Lua?是不是用了他做分表则可以不用更改客户端逻辑?)
MySQL Cluster (社区版不支持INNODB引擎?商用案例不足?)
MySQL + MHA (如果配上异步复制,似乎是不错的选择,又和问题?)
MySQL + MMM (似乎反映有很多问题,未实践过,谁能给个说法)
方式选择
若是双主复制的模式,不用做数据拆分,那么就可以选择MHA或 Keepalive 或 heartbeat
若是双主复制,还做了数据的拆分,则可以考虑采用Cobar;
若是双主复制+Slave,还做了数据的拆分,需要读写分类,可以考虑Amoeba;



