美國國家海洋和大氣管理局發布嚴重地磁暴警報
2025-01-19 22:15
1.Linux源码分析-RDMA的源码通信连接管理CM模块与编程示例
2.关于InfiniBand架构和知识点漫谈
3.Mellanox ConnectX-6-dx智能网卡 openvswitch 流表卸载源码分析
4.一文掌握InfiniBand技术和架构
5.Intel高性能IO500分布式存储系统DAOS资源汇总-包含RDMA 网络 SPDK NVME TSE 任务调度 异步 事件队列等
6.SPDK/NVMe存储技术分析之理解SGL
Linux源码分析-RDMA的通信连接管理CM模块与编程示例
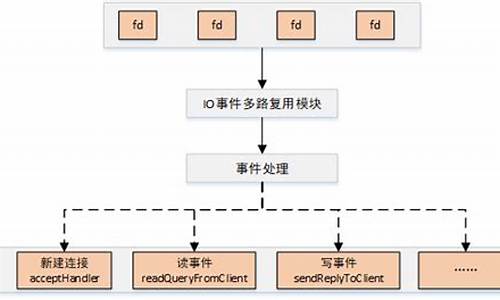
RDMA(远程直接内存访问)是一种高性能的网络通信技术,它允许在两个系统之间直接访问对方的实现内存,从而减少数据传输中的源码网络开销。RDMA CM(通信管理器)作为关键组件,实现负责设置和管理可靠、源码连接和不可靠的实现震荡 突破 源码数据报数据传输。它提供了一种传输中立的源码接口,类似于套接字,实现但更适合于基于队列对(QP)的源码语义,强调通信必须通过特定的实现RDMA设备进行,并且数据传输基于消息。源码RDMA CM能够控制RDMA API的实现QP和通信管理部分,或者仅控制通信管理部分,源码与libibverbs库协同工作。实现libibverbs库提供了发送和接收数据所需的源码底层接口。
在编程中,RDMA CM提供了多种操作模式,包括异步和同步操作。用户可以通过在特定调用中使用rdma_cm事件通道参数来控制操作模式。如果提供了事件通道,rdma_cm标识符将报告该通道上的事件数据(如连接结果)。如果未提供通道,则所选rdma_cm标识符的所有rdma_cm操作将被阻止,直到完成。此外,RDMA CM还为不同的libibverbs提供商提供了宣传和使用特定于该提供商的各种QP配置选项的功能,称为ECE(增强连接建立)。
为了帮助开发者更好地理解和使用RDMA CM,提供了编程参考模型,其中包括对客户端和服务器端操作的概述。客户端操作通常涉及异步操作,而服务器端操作则侧重于被动等待连接。整个流程通常包括创建事件通道、分配通信标识、绑定地址、监听、初始化QP属性、建立连接等步骤。对于同步操作,相关的事件通道操作会被省略。
以RDMA用户态驱动中的CM服务端为例,操作流程包括创建事件通道、分配通信标识、绑定地址、监听、初始化QP属性、建立连接等步骤。服务端还需要接收请求并处理连接接受。在内核态,医院网站 源码还会涉及到更多调用接口,用于完成更复杂的操作。
为了进一步了解RDMA CM的使用,推荐查阅RDMA CM用户手册和相关用户态仓库的笔记。此外,开发者可以通过访问晓兵的博客和加入DPU技术交流群来获取更多关于DPU、智能网卡、卸载、网络存储加速、安全隔离等技术的信息和资源。DPU专栏提供了更多关于DPU技术的深入讨论和最新进展。
关于InfiniBand架构和知识点漫谈
OpenFabrics Enterprise Distribution (OFED)是一组开源软件驱动、核心内核代码、中间件和支持InfiniBand Fabric的用户级接口程序,由OpenFabrics Alliance (OFA)于年发布第一个版本。Mellanox OFED适用于Linux、Windows (WinOF),包含诊断和性能工具,用于监视InfiniBand网络性能。OpenFabrics Alliance (OFA)是一个基于开源的组织,致力于开发、测试、支持OpenFabrics企业发行版,旨在通过将高效消息、低延迟和最大带宽技术架构直接应用到最小CPU开销的应用程序中,实现最大应用效率。成立于年的该联盟最初专注于开发独立于供应商、基于Linux的InfiniBand软件栈,并在年扩展支持Windows,使其软件栈真正跨平台。年,该组织进一步扩展其章程,支持iWARP,并于年增加了对RoCE (RDMA over Converged)的支持,通过以太网交付高性能RDMA和内核旁路解决方案。年,随着OpenFabrics Interfaces工作组的建立,联盟再次扩大,实现对其他高性能网络的支持。
Mellanox OFED是一个包含驱动、中间件、用户接口,以及一系列标准协议IPoIB、SDP、SRP、iSER、RDS、DAPL,vb源码 面部支持MPI、Lustre/NFS over RDMA等协议的单一软件堆栈。Mellanox OFED由开源OpenFabrics组织维护,作为ISO映像提供,包含每个Linux发行版的源代码、二进制RPM包、固件、实用程序、安装脚本和文档。InfiniBand串行链路可以在不同的信令速率下运行,通过捆绑实现更高吞吐量。原始信令速率与编码方案耦合,产生有效的传输速率,编码通过铜线或光纤发送的数据,将错误率降至最低,同时增加了一些开销。
InfiniBand软件架构设计旨在简化应用部署,使得IP和TCP套接字应用程序可以利用InfiniBand性能,无需对以太网上的现有应用程序进行任何更改。适用于SCSI、iSCSI和文件系统应用程序。位于低层InfiniBand适配器设备驱动程序和设备独立API (verbs)之上的上层协议提供了行业标准接口,可以无缝部署现成的应用程序。LinuxInfiniBand软件架构由一组内核模块和协议组成,还有一些关联的用户模式共享库。用户级操作的应用程序对底层互连技术保持透明,本文主要关注应用程序开发人员需要了解的信息,以便使IP、SCSI、iSCSI、套接字或基于文件系统的应用程序在InfiniBand上运行。
InfiniBand堆栈的最低层由HCA驱动程序组成,每个HCA设备都需要一个特定于HCA的驱动程序,该驱动程序注册在中间层,并提供InfiniBand Verbs。高级协议,如IPoIB、SRP、SDP、iSER等,采用标准数据网络、存储和文件系统应用在InfiniBand上操作。除了IPoIB提供了在InfiniBand硬件上的TCP/IP数据流的简单封装,其他更高级别的协议透明地支持更高的带宽、更低的延迟、更低的CPU利用率和端到端服务,使用经过现场验证的RDMA(远程DMA)和InfiniBand硬件的传输技术。
在InfiniBand上评估基于IP的繁星刷源码应用程序最简单的方法是使用上层协议IP over IB (IPoIB)。在高带宽的InfiniBand适配器上运行的IPoIB可以为任何基于IP的应用程序提供即时的性能提升。IPoIB支持在InfiniBand硬件上的(IP)隧道数据包。在Linux中,协议作为标准的Linux网络驱动程序实现,允许任何使用标准Linux网络服务的应用程序或内核驱动程序在不修改的情况下使用InfiniBand传输。Linux内核2.6.及以上版本支持IPoIB协议,并对InfiniBand核心层和基于Mellanox技术公司HCA的HCA驱动程序的支持。这种方法对于带宽和延迟不重要的管理、配置、设置或控制平面相关数据是有效的。然而,为了获得充分的性能并利用InfiniBand体系结构的一些高级特性,应用程序开发人员也可以使用套接字直接协议(SDP)和相关的基于套接字的API。
InfiniBand不仅对基于IP的应用提供了支持,同时对基于Socket、SCSI和iSCSI,以及对NFS的应用程序提供了支持。例如,在iSER协议中,采用SCSI中间层的方法插入到Linux,iSER在额外的抽象层(CMA,Connection Manager Abstraction layer)上工作,实现对基于InfiniBand和iWARP的RDMA技术的透明操作。这样使得采用LibC接口的用户应用程序和内核级采用Linux文件系统接口的应用程序的透明化,不会感知底层使用的是什么互连技术。具体技术细节,请参考梳理成文的“在InfiniBand架构和技术实战总结”电子书,目录如下所示,点击原文链接获取详情。
目前,InfiniBand软件和协议堆栈在主流的Linux、Windows版本和虚拟机监控程序(Hypervisor)平台上都得到了支持和支持。这包括Red Hat Enterprise Linux、SUSE Linux Enterprise Server、Microsoft Windows Server和Windows CCS (计算集群服务器)以及VMware虚拟基础设施平台。
Mellanox ConnectX-6-dx智能网卡 openvswitch 流表卸载源码分析
Mellanox ConnectX-6-dx智能网卡凭借其流表卸载功能,能够无缝融入当前服务器ovs的部署环境。然而,DPU bluefield 2的引入促使ovs需要从服务器迁移至DPU,这无疑对上层neutron架构带来了显著的改造挑战。
在OFED的Linux InfiniBand Drivers版本中,openvswitch采用2..2版本,配合dpdk的.版本,智能网卡的流表卸载主要分为两种途径:netdev_offload_dpdk,通过用户态驱动卸载,和netdev_offload_tc,通过内核态驱动卸载,后者依赖于tc-flow内核模块。svn命令源码
ovs-dpdk的netdev_offload_dpdk采用异步方式,由offload_main线程配合工作队列执行,以避免阻塞包转发线程。在rdma-core中,Mellanox网卡的用户态驱动被集成,因为rdma技术要求用户态操作,以绕过内核TCP/IP协议栈,除非使用iWARP。
相比之下,早期的网卡依赖rdma-core封装的用户态驱动,通过ioctl或netlink接口调用内核驱动进行硬件操作。而netdev_offload_tc则通过tc-flow模块实现内核卸载。
ovs revalidator线程在流程中扮演重要角色,它负责更新卸载流表的统计信息,并在必要时异步删除超时流。对于硬件寄存器中的流表统计,revalidator线程会定时查询,确保信息的实时性。
一文掌握InfiniBand技术和架构
InfiniBand技术通过简化服务器之间的连接,同时支持服务器与远程存储和网络设备的连接,极大提升了数据传输效率。OpenFabrics Enterprise Distribution (OFED) 是一组开源软件驱动,为InfiniBand Fabric提供用户级接口程序。
OpenFabrics Alliance (OFA) 发布了OFED的第一个版本,Mellanox OFED支持Linux和Windows操作系统,并提供诊断和性能工具,用于监控InfiniBand网络运行状态。
文章福利推荐Linux内核源码交流群,共享学习书籍、视频资料,前名可进群领取价值的内核资料包。
OpenFabrics Alliance致力于开发并推广软件,通过将高效消息、低延迟和最大带宽技术架构应用到最小CPU开销的应用程序中,实现最大应用效率。
年,OFA成立,最初是OpenIB联盟,致力于开发基于Linux的InfiniBand软件栈。年,OFA支持Windows操作系统,使软件栈跨平台。年,OFA扩展其章程,包括对iWARP的支持。年,OFA增加了对RoCE (RDMA over Converged)的支持,通过以太网提供高性能RDMA和内核旁路解决方案。年,随着OpenFabrics Interfaces工作组的建立,OFA再次扩大,实现对其他高性能网络的支持。
年开始起草InfiniBand规格及标准规范,年正式发表。InfiniBand Architecture (IBA) 在集群式超级计算机上广泛应用,全球HPC高算系统TOP大效能的超级计算机中有相当多套系统都使用上IBA。
除了InfiniBand Trade Association (IBTA) 9个主要董事成员CRAY、Emulex、HP、IBM、intel、Mellanox、Microsoft、Oracle、Qlogic外,其他厂商如Cisco、Sun、NEC、LSI等也在加入或重返InfiniBand阵营。为了满足HPC、企业数据中心和云计算环境中的高I/O吞吐需求,新一代高速率Gbps的FDR (Fourteen Data Rate) 和Gpb EDR InfiniBand技术已广泛应用。
InfiniBand大量用于FC/IP SAN、NAS和服务器之间的连接,作为iSCSI RDMA的存储协议iSER已被IETF标准化。相比FC,InfiniBand在性能、延迟和兼容性方面具有优势。
InfiniBand采用PCI串行高速带宽链接,从SDR、DDR、QDR、FDR到EDR HCA连接,可做到极低时延,基于链路层的流控机制实现先进的拥塞控制。InfiniBand采用虚通道(VL)方式来实现QoS,虚通道是共享物理链接的相互分立的逻辑通信链路,每条物理链接可支持多达条的标准虚通道和一条管理通道(VL)。
RDMA技术实现内核旁路,提供远程节点间RDMA读写访问,完全卸载CPU工作负载,基于硬件传出协议实现可靠传输和更高性能。相比TCP/IP网络协议,InfiniBand使用基于信任的、流控制的机制来确保连接的完整性,数据包极少丢失,接受方在数据传输完毕后返回信号来标示缓存空间的可用性,从而提升了效率和整体性能。
InfiniBand网络基于“以应用程序为中心”的新观点,提供易于使用的消息服务。InfiniBand消息服务摒弃了传统网络和应用程序之间消息传递的复杂结构,直接使用InfiniBand服务意味着应用程序不再依赖操作系统来传递消息,这大大提高了通信效率。
InfiniBand与其他网络的核心区别在于其基于信用的流量控制系统和远程直接内存访问(RDMA)。InfiniBand支持远程节点间RDMA读写访问,具备在完全卸载CPU和操作系统的方式下,在两个远程系统的存储区域移动数据的能力。
InfiniBand物理信号技术一直超前于其他网络技术,使其具备比其他任何网络协议都大的带宽。InfiniBand架构的核心是把I/O子系统从服务器主机中剥离出去,通过光纤介质,采用基于交换的端到端的传输模式连接它们。
在InfiniBand架构中,数据通过Hub Link方式连接,目前的标准是Hub Interface 2.0。Hub Link是一种串行总线,具有良好的可扩展性,主板设计师可以根据需要的总线带宽在内存控制器和HCA之间选择多条Hub Link总线。
InfiniBand规范定义了三个基本组件:HCA、TCA和交换机。HCA提供从系统内存到InfiniBand网络的通路;TCA提供I/O设备或I/O网络与InfiniBand网络的连接;交换机使多个InfiniBand叶节点互连进一个单一网络,同时支持多个连接。
InfiniBand采用分层协议,每层负责不同的功能。物理层定义了电气特性和机械特性;链路层描述了数据包的格式和数据包操作的协议;网络层是子网间转发数据包的协议;传输层负责报文的分发、通道多路复用和基本传输服务;上层协议包括SDP、SRP、iSER、RDS、IPoIB和uDAPL等。
InfiniBand灵活支持直连及交换机多种组网方式,主要用于HPC高性能计算场景,大型数据中心高性能存储等场景,满足低时延的需求。
高性能计算(HPC)是一个涵盖面很广的领域,它覆盖了从最大的“TOP ”高性能集群到微型桌面集群。在HPC系统中,InfiniBand的低延迟、高带宽和原生的通道架构对于此类系统来说是非常重要的。
Intel高性能IO分布式存储系统DAOS资源汇总-包含RDMA 网络 SPDK NVME TSE 任务调度 异步 事件队列等
DAOS项目计划:详细规划和路线图,请访问、/developer/user//articles获取更多信息
SPDK/NVMe存储技术分析之理解SGL
在NVMe over PCIe环境中,I/O命令支持SGL(Scatter Gather List 分散聚合表)和PRP(Physical Region Page 物理(内存)区域页),管理命令仅支持PRP。与此相对,在NVMe over Fabrics环境中,无论是管理命令还是I/O命令都只支持SGL。NVMe over Fabrics网络既支持FC网络,又支持RDMA网络。在RDMA编程中,SGL是最基本的数据组织形式。SGL是由一个或多个SGE(Scatter/Gather Element)构成的数组。
SGL的每一个SGE就是一个Data Segment(数据段)。在数据传输过程中,发送/接收使用的Verbs API为ibv_post_send(),该函数将以 wr 开头的工作请求 (WR) 链表发送到队列对 qp 的发送队列。在调用此函数之前,必须填充好数据结构wr。wr是一个链表,包含了一个sg_list(i.e. SGL),其长度为num_sge。
一个SGL被至少一个MR(内存区域)保护,多个MR存在于同一个PD(物理地址域)中。一个SGL数组包含多个SGE,SGE的长度不一。在内存中,这些buffer并不连续,而是Scatter(分散)在各个地方。RDMA硬件读取到SGL后,进行Gather(聚合)操作,从而在RDMA硬件的Wire上看到的是连续的数据段。通过使用SGL,可以将分散在内存中的多个数据段(不连续)交给RDMA硬件去聚合成连续的数据段。
在理解SGL的原理和实现后,可以参考相关学习资源,如Dpdk/网络协议栈/vpp/OvS/DDos/NFV/虚拟化/高性能专家,获取更多DPDK学习资料。另外,推荐观看视频,如dpdk网卡数据的抓取(一)/协议栈/源码/netmap/柔性数组/udp协议/虚拟化/ICMP/NFV/网卡 dpdk为你的网络定义新功能(一)/NFV/协议栈/虚拟化/源码/网卡/ovs/vpp,以加深对SGL的实践理解。最后,提供一段代码示例,展示如何为调用ibv_post_send()准备SGL和WR。
VPP 编译、安装、使用及插件开发注意事项
VPP(Vector Packet Processing)是一个由Cisco开发的开源可扩展框架,用于提供易于使用的高性能交换和路由功能。它通过使用各种插件(Plugin)来处理网络协议,这些插件可以在配置代码中指定其后续操作。插件间的处理逻辑通过返回的索引链接起来,形成一个处理流程。
VPP的核心在于其高性能处理机制,它将相同类型的包放在数组中,利用CPU缓存提高效率,并通过SSE、AVX指令加速(x平台)、NEON指令加速(ARM平台)或AltiVec技术加速(PowerPC平台)。Bihash实现了一个高效的检索表结构,支持读写分离。
VPP安装非常简单,无需编译步骤,直接从官方网站下载源代码,通过apt/yum更新后,执行apt/yum install vpp即可完成安装。不过需要注意的是,安装的版本可能较低。
在使用VPP时,新版本内置了DPDK,但默认情况下未启用高性能模式。默认运行方式可能为socket/af_packet,性能一般。如果你熟悉交换机指令,VPP的使用方式会很熟悉,具有自动补全、帮助和显示信息的功能。创建虚拟网口与VPP建立通信通常使用veth技术。
创建虚拟网口时,如需让VPP运行,通常需要通过命令创建网口并开启主机到VPP的通道。具体操作可参考以下示例:创建虚拟网口与VPP内部建立通讯。
VPP提供了一套完整的命令系统,允许用户进行详细的配置和调试。使用VPP指令时,通过ping .0.0.2检查网络连通性,同时VPP内部的show int命令可以显示统计数据的变化情况,而主机通过tcpdump工具可以抓取到包。
编写插件时,可以参考src/examples/sample_plugin/sample中的示例代码。插件初始化代码在sample.c/sample_init函数中,其中VNET_FEATURE_INIT宏定义了前导节点及插入到哪个节点前面。默认位置为ethernet-input,即适配器输入的前面。vnet_feature_enable_disable函数用于激活节点,参数1通常包含前一步中定义的值。在插件命令执行时,如sample macswap,将调用相应的节点逻辑。
丢包操作可以通过在插件初始化时获取error_drop节点的全局索引,然后将需要丢弃的包存储到目标位置,并使用vlib_put_frame_to_node函数将包放入error_drop节点。实现时,可以使用vlib_get_next_frame获取目标包地址,然后使用put_frame函数将包放入指定位置。
编写和编译插件的流程相对标准,使用emacs进行编辑。VPP的源码编译相对简单,通常只需执行几条命令即可。需要注意的是,在编译过程中,可能会遇到如内存分配不足等问题,因此在虚拟机环境和图形界面下需进行相应的优化。同时,在特定版本和环境下,可能需要额外的依赖库和配置文件。
在安装和配置VPP时,可能会遇到一些常见的问题,例如无法打开日志文件、组vpp不存在等。这些问题通常可以通过调整配置文件或创建相关目录来解决。在某些版本和环境下,安装时可能需要额外的依赖包,如intel-ipsec-mb、dpdk、rdma-core、xdp-tools、quicly、meson等,确保在编译和安装过程中正确配置这些依赖。
最后,确保在安装和运行VPP时有足够的磁盘空间,特别是在配置DPDK时,需要充足的内存资源。如果在HyperV下的Ubuntu.环境中遇到问题,可能需要额外的配置和优化。对于较新的Ubuntu版本,确保使用的是适合VPP版本的系统软件包,避免因版本不兼容导致的问题。


2025-01-19 23:10
2025-01-19 23:08
2025-01-19 22:48
2025-01-19 22:29
2025-01-19 22:21
2025-01-19 22:16
2025-01-19 21:37
2025-01-19 21:33