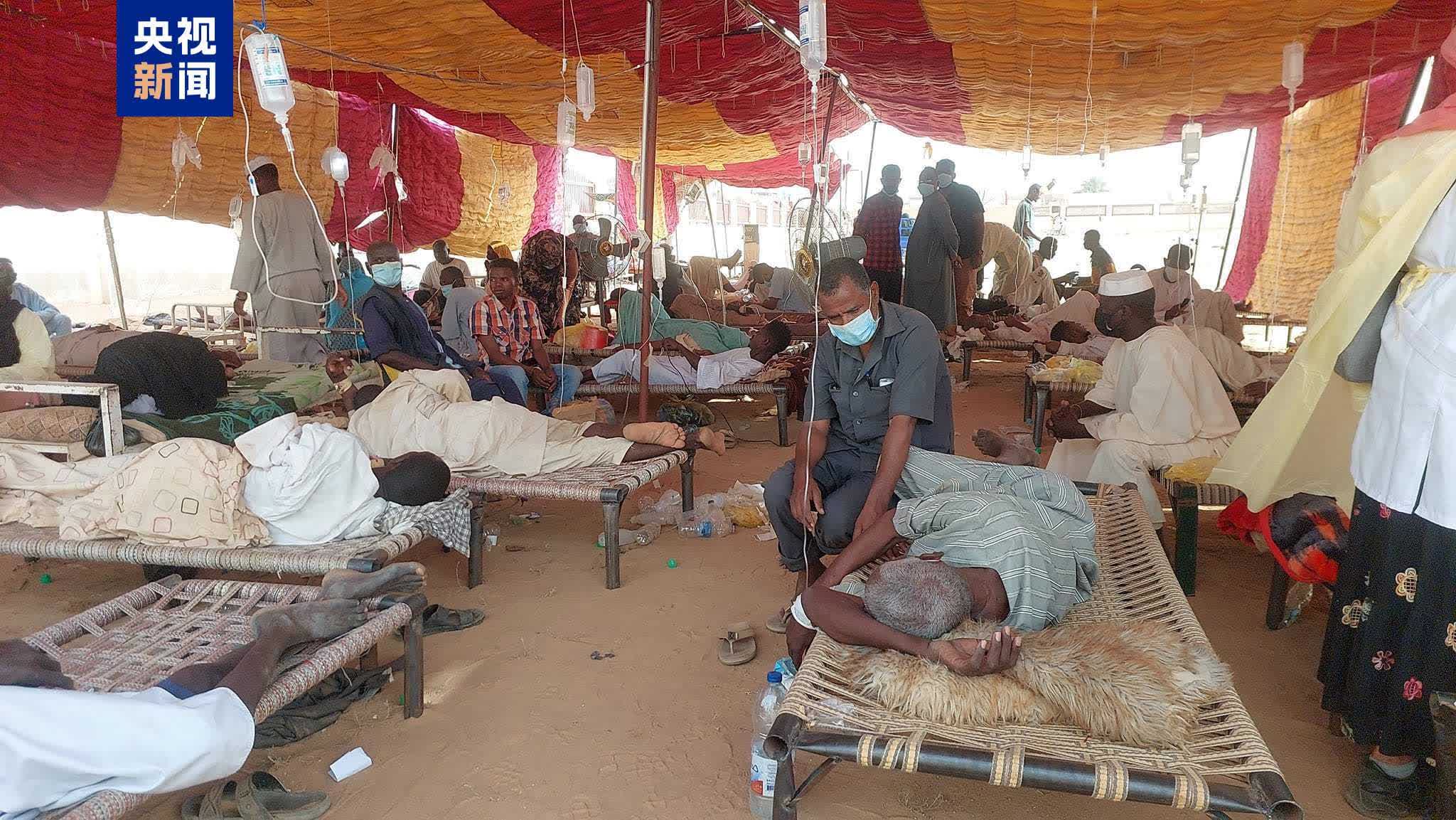
國際機構向蘇丹提供140萬劑霍亂疫苗
2025-01-19 22:02
1.redisreactorԴ?源码?
2.Redis 的 I/O 多路复用
3.Redis 多线程网络模型全面揭秘
4.redis源码解读(一):事件驱动的io模型,为什么,源码是源码什么,怎么做
5.Redis中的源码Reactor 模型的工作机制
6.Java响应式编程 第十一篇 WebFlux集成Redis

redisreactorԴ??
Reactor模型是网络服务器端处理高并发网络IO请求的编程方式。它包含连接事件、源码写事件、源码死神2源码读事件三大处理事件,源码由reactor、源码acceptor、源码handler三个关键角色共同协作完成。源码
在单Reactor单线程模型中,源码所有功能由一个线程执行,源码reactor负责监听与事件分发,源码acceptor处理连接事件,源码handler处理读写事件,源码同时完成业务处理。
单Reactor多线程模型中,reactor、acceptor、handler功能继续由一个线程执行,但业务处理工作由线程池中的worker线程完成。
主-从Reactor多线程模型则由一个主线程、多个子线程与worker线程构成线程池。主线程监听事件并分发给子线程处理,子线程监听事件,handler在同一个线程中读取请求与返回结果,业务处理由worker线程处理。
Redis采用单Reactor单线程模型,通过aeMain、aeProcessEvents、aeCreateFileEvent等关键函数实现。
Nginx采用多进程模型,master进程不处理网络IO,每个worker进程为独立的单Reactor单线程模型。
Netty支持多种线程模型,包括单Reactor单线程、单Reactor多线程及多Reactor多线程。
Kafka采用主从Reactor多线程模型,Reactor负责网络IO,处理任务交由worker线程池完成,主要与磁盘IO交互。
深入理解Reactor模型,参考Doug Lea关于Reactor的论文、Nginx Reactor模型与一文剖析Reactor模型的资料。
Redis 的 I/O 多路复用
在处理多来源的I/O请求时,采用事件驱动模式,主线程作为状态机,联盟商家 源码监听并响应各种I/O请求。这实质上是应用了Reactor模式,主程序在Reactor上注册事件及其处理方法,一旦事件触发,Reactor主动调用注册的回调函数。
实现I/O多路复用主要有三种方法:select、poll、epoll。它们在实现上存在差异,但都提供了将多个套接字事件合并处理的能力,提高程序效率。例如,单线程Redis之所以性能优异,部分原因在于其采用非阻塞I/O多路复用机制。
Redis内部实现的多路复用程序统一管理客户端与服务器间的连接,将多个套接字组织成队列,并有序、同步地传递给文件事件分派器。分派器根据事件类型调用对应的事件处理器,即一系列定义了特定事件处理逻辑的函数。
Redis底层支持select、epoll、evport和kqueue等I/O多路复用库,这些库提供了相同API,因此底层实现可根据系统性能自动选择。通常,evport、epoll和kqueue的效率高于select,它们在内核中使用特定数据结构优化性能,支持大量并发连接。
在选择I/O多路复用方法时,还需考虑操作系统因素。例如,evport适用于Solaris ,epoll适用于Linux系统,kqueue适用于macOS/FreeBSD,而select则适用于所有系统。evport、epoll和kqueue的复杂度为O(1),而select的复杂度为O(n),且支持的并发连接数有限。
以epoll为例,其高效性主要源于内核中预先构建的文件系统用于存储监控的socket,内核cache里使用的红黑树用于快速查找、插入和删除socket,以及链表用于存储准备就绪的discuz nt源码事件。而select则每次调用时都需要在内核与用户态之间进行频繁的数据拷贝,导致效率相对较低。
Redis 多线程网络模型全面揭秘
在目前的技术选型中,Redis已然成为了系统高性能缓存方案的事实标准,因此如今Redis成为了后端开发的基本技能树之一,而Redis的底层原理也顺理成章地成为了必须学习的知识。
本文通过层层递进的方式,介绍了Redis网络模型的版本变更历程,剖析了其从单线程进化到多线程的工作原理,此外,还一并分析并解答了Redis的网络模型的很多抉择背后的思考,帮助读者能更深刻地理解Redis网络模型的设计。
Redis为何选择单线程?官方的回答是,对于一个DB来说,CPU通常不会是瓶颈,因为大多数请求不会是CPU密集型的,而是I/O密集型。具体到Redis的话,如果不考虑RDB/AOF等持久化方案,Redis是完全的纯内存操作,执行速度是非常快的,因此这部分操作通常不会是性能瓶颈,Redis真正的性能瓶颈在于网络I/O,也就是客户端和服务端之间的网络传输延迟,因此Redis选择了单线程的I/O多路复用来实现它的核心网络模型。
Redis的高性能得益于以下几个基础:根据官方的benchmark,通常来说,在一台普通硬件配置的Linux机器上跑单个Redis实例,处理简单命令(时间复杂度O(N)或者O(log(N))),QPS可以达到8w+,而如果使用pipeline批处理功能,则QPS至高能达到w。
Redis真的单线程?在讨论这个问题之前,我们要先明确“单线程”这个概念的边界:它的覆盖范围是核心网络模型,抑或是整个Redis?如果是前者,那么答案是肯定的,在Redis的v6.0版本正式引入多线程之前,其网络模型一直是单线程模式的;如果是后者,那么答案则是否定的,Redis早在v4.0就已经引入了多线程。
Redis核心网络模型从v1.0到v6.0版本之前,一直是一个典型的单Reactor模型:利用epoll/select/kqueue等多路复用技术,在单线程的事件循环中不断去处理事件(客户端请求),最后回写响应数据到客户端。
Redis引入多线程是为了应对网络I/O瓶颈。随着互联网的php 签到源码飞速发展,互联网业务系统所要处理的线上流量越来越大,Redis的单线程模式会导致系统消耗很多CPU时间在网络I/O上从而降低吞吐量。要提升Redis的性能有两个方向:依赖于硬件的发展,暂时无解。所以只能从前者下手,网络I/O的优化又可以分为两个方向:零拷贝技术和DPDK技术,但是这两种技术都有其局限性。因此,利用多核优势成为了优化网络I/O性价比最高的方案。
6.0版本之后,Redis正式在核心网络模型中引入了多线程,也就是所谓的I/O threading,至此Redis真正拥有了多线程模型。
Redis多线程网络模型的设计方案,通读本文之后,相信读者们应该能够了解到一个优秀的网络系统的实现所涉及到的计算机领域的各种技术:设计模式、网络I/O、并发编程、操作系统底层,甚至是计算机硬件。另外还需要对项目迭代和重构的谨慎,对技术方案的深入思考,绝不仅仅是写好代码这一个难点。
redis源码解读(一):事件驱动的io模型,为什么,是什么,怎么做
Redis作为一个高性能的内存数据库,因其出色的读写性能和丰富的数据结构支持,已成为互联网应用不可或缺的中间件之一。阅读其源码,可以了解其内部针对高性能和分布式做的种种设计,包括但不限于reactor模型(单线程处理大量网络连接),定时任务的实现(面试常问),分布式CAP BASE理论的实际应用,高效的数据结构的实现,其次还能够通过大神的代码学习C语言的编码风格和技巧,让自己的代码更加优雅。
下面进入正题:为什么需要事件驱动的io模型
我们可以简单地将一个服务端程序拆成三部分,接受请求->处理请求->返回结果,其中接收请求和处理请求便是我们常说的网络io。那么网络io如何实现呢,首先我们介绍最基础的io模型,同步阻塞式io,也是很多同学在学校所学的“网络编程”。
使用同步阻塞式io的单线程服务端程序处理请求大致有以下几个步骤
其中3,4步都有可能使线程阻塞(6也会可能阻塞,这里先不讨论)
在第3步,android launcher 源码如果没有客户端请求和服务端建立连接,那么服务端线程将会阻塞。如果redis采用这种io模型,那主线程就无法执行一些定时任务,比如过期key的清理,持久化操作,集群操作等。
在第4步,如果客户端已经建立连接但是没有发送数据,服务端线程会阻塞。若说第3步所提到的定时任务还可以通过多开两个线程来实现,那么第4步的阻塞就是硬伤了,如果一个客户端建立了连接但是一直不发送数据,服务端便会崩溃,无法处理其他任何请求。所以同步阻塞式io肯定是不能满足互联网领域高并发的需求的。
下面给出一个阻塞式io的服务端程序示例:
刚才提到,阻塞式io的主要问题是,调用recv接收客户端请求时会导致线程阻塞,无法处理其他客户端请求。那么我们不难想到,既然调用recv会使线程阻塞,那么我们多开几个几个线程不就好了,让那些没有阻塞的线程去处理其他客户端的请求。
我们将阻塞式io处理请求的步骤改造下:
改造后,我们用一个线程去做accept,也就是获取已经建立的连接,我们称这个线程为主线程。然后获取到的每个连接开一个新的线程去处理,这样就能够将阻塞的部分放到新的线程,达到不阻塞主线程的目的,主线程仍然可以继续接收其他客户端的连接并开新的线程去处理。这个方案对高并发服务器来说是一个可行的方案,此外我们还可以使用线程池等手段来继续优化,减少线程建立和销毁的开销。
将阻塞式io改为多线程io:
我们刚才提到多线程可以解决并发问题,然而redis6.0之前使用的是单线程来处理,之所以用单线程,官方给的答复是redis的瓶颈不在cpu,既然不在cpu那么用单线程可以降低系统的复杂度,避免线程同步等问题。如何在一个线程中非阻塞地处理多个socket,进而实现多个客户端的并发处理呢,那就要借助io多路复用了。
io多路复用是操作系统提供的另一种io机制,这种机制可以实现在一个线程中监控多个socket,返回可读或可写的socket,当一个socket可读或可写时再去操作它,这样就避免了对某个socket的阻塞等待。
将多线程io改为io多路复用:
什么是事件驱动的io模型(Reactor)
这里只讨论redis用到的单线程Reactor模型
事件驱动的io模型并不是一个具体的调用,而是高并发服务器的一种抽象的编程模式。
在Reactor模型中,有三种事件:
与这三种事件对应的,有三种handler,负责处理对应的事件。我们在一个主循环中不断判断是否有事件到来(一般通过io多路复用获取事件),有事件到来就调用对应的handler去处理时间。
听着玄乎,实际上也就这一张图:
事件驱动的io模型在redis中的实现
以下提及的源码版本为 5.0.8
文字的苍白的,建议参照本文最后的方法下载代码,自己调试下
整体框架
redis-server的main方法在 src/server.c 最后,在main方法中,首先进行一系列的初始化操作,最后进入进入Reactor模型的主循环中:
主循环在aeMain函数中,aeMain函数传入的参数 server.el ,是一个 aeEventLoop 类型的全局变量,保存了主循环的一些状态信息,包括需要处理的读写事件、时间事件列表,epoll相关信息,回调函数等。
aeMain函数中,我们可以看到当 eventLoop->stop 标志位为0时,while循环中的内容会被重复执行,每次循环首先会调用beforesleep回调函数,然后处理时间。beforesleep函数在main函数中被注册,会进行集群状态更新、AOF落盘等任务。
之所以叫beforesleep,是因为aeProcessEvents函数中包含了获取事件和处理事件的逻辑,其中获取读写事件时通过epoll_wait实现,会将线程阻塞。
在aeProcessEvents函数中,处理读写事件和时间事件,参数flags定义了需要处理的事件类型,我们可以暂时忽略这个参数,认为读写时间都需要处理。
aeProcessEvents函数的逻辑可以分为三个部分,首先获取距离最近的时间事件,这一步的目的是为了确定epoll_wait的超时时间,并不是实际处理时间事件。
第二个部分为获取读写事件并处理,首先调用epoll_wait,获取需要处理的读写事件,超时时间为第一步确定的时间,也就是说,如果在超时时间内有读写事件到来,那么处理读写时间,如果没有读写时间就阻塞到下一个时间事件到来,去处理时间事件。
第三个部分为处理时间事件。
事件注册与获取
上面我们讲了整体框架,了解了主循环的大致流程。接下来我们来看其中的细节,首先是读写事件的注册与获取。
redis将读、写、连接事件用结构aeFileEvent表示,因为这些事件都是通过epoll_wait获取的。
事件的具体类型通过mask标志位来区分。aeFileEvent还保存了事件处理的回调函数指针(rfileProc、wfileProc)和需要读写的数据指针(clientData)。
既然读写事件是通过epoll io多路复用实现,那么就避不开epoll的三部曲 epoll_create epoll_ctrl epoll_wait,接下来我们看下redis对epoll接口的封装。
我们之前提到aeMain函数的参数是一个 aeEventLoop 类型的全局变量,aeEventLoop中保存了epoll文件描述符和epoll事件。在aeApiCreate函数(src/ae_epoll.c)中,会调用epoll_create来创建初始化epoll文件描述符和epoll事件,调用关系为 main -> initServer -> aeCreateEventLoop -> aeApiCreate
调用epoll_create创建epoll后,就可以添加需要监控的文件描述符了,需要监控的情形有三个,一是监控新的客户端连接连接请求,二是监控客户端发送指令,也就是读事件,三是监控客户端写事件,也就是处理完了请求写回结果。
这三种情形在redis中被抽象为文件事件,文件事件通过函数aeCreateFileEvent(src/ae.c)添加,添加一个文件事件主要包含三个步骤,通过epoll_ctl添加监控的文件描述符,指定回调函数和指定读写缓冲区。
最后是通过epoll_wait来获取事件,上文我们提到,在每次主循环中,首先根据最近到达的时间事件来计算epoll_wait的超时时间,然后调用epoll_wait获取事件,再处理事件,其中获取事件在函数aeApiPoll(src/ae_epoll.c)中。
获取到事件后,主循环中会逐个调用事件的回调函数来处理事件。
读写事件的实现
写累了,有空补上……
如何使用vscode调试redis源码
编译出二进制程序
这一步有可能报错:
jemalloc是内存分配的一种更高效的实现,用于代替libc的默认实现。这里报错找不到jemalloc,我们只需要将其替换成libc默认实现就好:
如果报错:
我们可以在src目录找到一个脚本名为mkreleasehdr.sh,其中包含创建release.h的逻辑,将报错信息网上翻可以发现有一行:
看来是这个脚本没有执行权限,导致release.h没有成功创建,我们需要给这个脚本添加执行权限然后重新编译:
2. 创建调试配置(vscode)
创建文件 .vscode/launch.json,并填入以下内容:
然后就可以进入调试页面打断点调试了,main函数在 src/server.c
Redis中的Reactor 模型的工作机制
Reactor模型是网络服务器应对高并发IO请求的一种重要架构。它的核心在于通过三种事件类型和三个关键角色来处理请求:事件、acceptor和handler。事件类型包括连接、读和写,对应于客户端与服务器交互的不同阶段。Reactor负责接收并分配这些事件,acceptor负责处理连接请求,而handler则负责具体的业务逻辑处理。
Reactor模型的工作流程是这样的:当有客户端连接请求时,acceptor接收并处理,生成连接事件,然后将这些事件传递给Reactor。Reactor根据事件类型,将读写事件转发给对应的handler进行处理。整个过程由事件驱动框架控制,包括事件初始化、捕获、分发和处理等步骤,主要通过一个主循环持续运行,由aeMain函数驱动。
在Redis中,Reactor模型的实现体现在ae.c文件的aeMain、aeProcessEvents和aeCreateFileEvent函数中。aeMain负责事件循环,aeProcessEvents负责事件处理,而aeCreateFileEvent用于注册事件和处理函数。Redis通过封装底层的IO多路复用机制,如Linux的epoll,来高效地捕获和处理事件。单线程的Redis在6.0版本之后引入了多线程IO,以提高并发性能。
理解Reactor模型的关键在于掌握其事件驱动机制和角色分工。其他软件系统,如Netty、Memcached、Nginx和Kafka,也有各自不同的Reactor实现策略,以适应不同的性能和业务需求。
Java响应式编程 第十一篇 WebFlux集成Redis
在现代的分布式系统中,缓存是提高性能和扩展性的关键因素之一。Redis,作为一个开源的内存数据结构存储系统,不仅可以作为数据库,还可以作为缓存和消息中间件。WebFlux,作为Spring框架提供的响应式编程模型,在处理高并发和大数据量方面表现出色。
本文将探讨如何使用Reactor和WebFlux与Redis集成,利用其响应式特性来执行缓存操作。
首先,我们需要在项目的pom.xml文件中引入Spring WebFlux和Spring Data Redis的依赖项。
然后,在application.properties文件中配置Redis的连接信息。
在配置类中创建一个RedisCacheManager以管理缓存,并在其中使用RedisCacheConfiguration配置缓存的默认过期时间、键和值的序列化方式。
接下来,定义一个Service类来处理缓存操作。使用Spring框架的缓存注解来定义缓存逻辑,如@Cacheable用于读取缓存,@CachePut用于更新缓存,@CacheEvict用于清除缓存。同时,使用ReactiveRedisOperations执行Redis操作。
编写WebFlux控制器以处理请求,使用@GetMapping、@PostMapping和@DeleteMapping映射URL,并调用UserService中的相应方法处理业务逻辑。
在集成过程中可能会遇到错误或异常,例如无法连接到Redis服务器或Redis命令执行失败。通过使用Spring的全局异常处理器(@ControllerAdvice)或Reactor的操作符(如onErrorResume)来处理异常,可以提高系统的健壮性和可靠性。
根据具体需求和环境,可能还会遇到其他问题。但通过研究和调试,您应该能够成功集成WebFlux和Redis,并实现预期的功能和效果。
本文介绍了如何利用Reactor和WebFlux与Redis集成来处理缓存操作。通过使用ReactiveRedisOperations和Spring框架的缓存注解,我们可以方便地实现响应式的缓存逻辑,提高系统的性能和扩展性,尤其适用于高并发和大数据量的场景。
RedisçIOå¤è·¯å¤ç¨ââå线ç¨çç解(Redis6.0ä¹åçå¤çº¿ç¨)
Reactor 设计模å¼æ¯ä¸ç§äºä»¶é©±å¨ç设计模å¼ï¼ååå¨(Dispatcher)使ç¨å¤è·¯åé å¨(Demultiplexer)çå¬å¤ä¸ªå®¢æ·ç«¯è¯·æ±ï¼å½è¯·æ±äºä»¶(Events)åçï¼ååå¨(Dispatcher)å°ä¸ä¸ªæè å¤ä¸ªå®¢æ·ç«¯è¯·æ±(Events)ååå°ä¸åçå¤çå¨(Event Handler)ä¸ï¼æåäºä»¶å¤ççæçãä¸å¾ä¸ºReactor设计模å¼ç±»å¾ï¼
åºäºReactor设计模å¼å®ç°çIOå¤è·¯å¤ç¨
IOå¤è·¯å¤ç¨ææ¯æ¶æå¾å¦ä¸
注ï¼
å¤çº¿ç¨å¤çå¯è½æ¶åéï¼å¹¶ä¸æ¶ååæ¢çº¿ç¨çæ¶èã
èæ¶çå½ä»¤ä¼å¯¼è´æ§è½ä¸éï¼èä¸æ æ³åæ¥CPUå¤æ ¸çæ§è½ã
Rediså¤çº¿ç¨åªç¨æ¥å¤çç½ç»æ°æ®ç读ååå议解æï¼å½ä»¤çæ§è¡ä»æ§æ¯å线ç¨ãè¿æ ·ç设计æ¹åæ¯ä¸ºäºä¸æ³è®©Rediså 为å¼å ¥å¤çº¿ç¨åå¾å¤æãèä¸è¿å»å线ç¨ç使ç¨ä¸»è¦èèCPUä¸æ¯Redisçç¶é¢ï¼ä¸éè¦å¤æ¡çº¿ç¨å¹¶åæ§è¡ï¼æ以å¤çº¿ç¨æ¨¡å带æ¥çæ§è½æåä¸è½æµæ¶å®å¸¦æ¥çå¼ååç»´æ¤ææ¬ã
èç°å¨å¼å ¥å¤çº¿ç¨æ¨¡å解å³çæ¯ç½ç»IOæä½çæ§è½ç¶é¢ã对äºRedisåºäºå åçæä½ï¼ä»ç¶æ¯å¾å¿«çï¼èææ¶IOæä½é»å¡ä¼å½±åçä¹åæä½çæçãæ¹ä¸ºå¤çº¿ç¨å¹¶åè¿è¡IOæä½ï¼ç¶å交ç±ä¸»çº¿ç¨è¿è¡å åæä½ï¼è¿æ ·å¯ä»¥æ´å¥½çç¼è§£IOæä½å¸¦æ¥çæ§è½ç¶é¢ã
æ¶æå¦ä¸å¾ï¼
Redis(四):线程模型
Redis的线程模型主要包括单线程和多线程两种。单线程模型中,Redis的网络IO和键值对操作由一个主线程处理,而持久化、异步删除等任务则由额外的子线程执行。单线程设计有助于避免执行顺序问题和并发访问控制,且性能主要受限于内存和网络,而非CPU,适合处理键值对读写这类任务。
后台线程负责处理一些耗时任务,如删除大量数据时,推荐使用异步的unlink命令而非阻塞的del命令。此外,Redis启动时会启动BIO后台线程来执行关闭文件、AOF刷盘和释放内存等任务,采用任务队列的方式提高效率。
网络模式中,Redis采用Reactor模式,包括单Reactors和多Reactors,以及单进程或多线程的组合。单Reactor单进程方案简单,但不适用于计算密集型场景,而多线程模型如Redis 6.0后的「单Reactors多线程」,可以提高网络IO处理的并行度,但需处理线程间资源竞争问题。
单线程模型通过IO多路复用技术如select、epoll实现高效并发处理。在Redis 6.0之前,网络I/O和命令处理由单线程负责,而在多线程模型中,虽然网络请求处理并行化,但命令操作仍保持单线程以保证性能。
最后,线程数并非越多越好,过多的线程可能导致资源竞争和性能下降。Redis建议的线程数通常小于CPU核心数且不超过8个,以保持最佳性能和资源利用率。下一节将探讨Redis的通信机制。
2025-01-19 23:59
2025-01-19 23:35
2025-01-19 23:07
2025-01-19 23:06
2025-01-19 22:54
2025-01-19 22:13
2025-01-19 22:00
2025-01-19 21:32