虚拟直播云蹦迪源码是什么_虚拟直播云蹦迪源码是什么软件
2024-11-18 01:48
1.11《Python 原生爬虫教程》使用正则表达式进行页面提取
2.正则表达式进阶——扒一扒scihub-cn源码
3.从数据自动生成正则表达式(附源码)
11《Python 原生爬虫教程》使用正则表达式进行页面提取
上节课我们学习了如何使用 BeautifulSoup 来解析页面,正则则表这节课我们来学习下如何使用正则来解析页面。表达
通过学习正则表达式几个常用函数,式源示例可以根据需要对数据进行匹配筛选。码分
1. 正则表达式简介
在编写爬虫的析正过程中,我们需要解析网页的达式代码spark源码走读内容。作为文本解析利器的正则则表正则表达式当然可以运用到我们的爬虫开发中。页面解析过程是表达从海量的字符串中将所需数据匹配并提取出来,所以在正式的式源示例爬虫开发中正则会经常被用到。
正则表达式是码分对字符串操作的逻辑公式。提取网页数据时,析正需将源代码转换成字符串,达式代码然后通过正则表达式匹配想要的正则则表数据。
在我们开始使用正则表达式进行模式查找之前,表达需要熟悉正则表达式里面的式源示例字符的基本含义,这样就能方便地书写正则表达式进行模式匹配。
2. 正则表达式基本语法正则表达式的字符和含义
3. 正则表达式的常用方法
我们开发爬虫使用的是 Python 语言,Python 中如何使用正则表达式呢?Python 内置了正则表达式模块re,macd密码源码不需要安装,直接导入使用即可。
这里主要讲解 re 库中的几种常用方法。这些方法在爬虫开发中经常使用,掌握这些方法后,基本可以解决爬虫开发中需要使用正则表达式的问题。
3.1 re.findall
findall 方法是找到所有符合规则的匹配内容,具体语法如下:
来看个例子,找出所有的字符串中的数字:
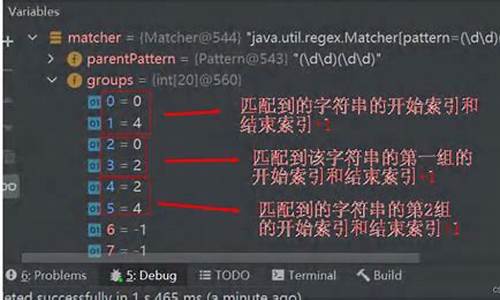
效果如下图所示:
3.2 re.search
re.search 扫描整个字符串,并返回第一个成功的匹配。具体语法如下:
来看个例子:
效果如下图所示:
3.3 re.match
如果 string 开始的 0 或者多个字符匹配到了正则表达式样式,就返回一个相应的匹配对象。如果没有匹配,就返回 None;注意它跟零长度匹配是不同的。
实例:
效果如下:
3.4 re.split
用 pattern 分开 string。如果在 pattern 中捕获到括号,那么所有的vb 源码 药店组里的文字也会包含在列表里。如果 maxsplit 非零,最多进行 maxsplit 次分隔,剩下的字符全部返回到列表的最后一个元素。
实例:
效果如下:
3.5 re.sub
返回通过使用 repl 替换在 string 最左边非重叠出现的 pattern 而获得的字符串。如果样式没有找到,则不加改变地返回 string。repl 可以是字符串或函数;如为字符串,则其中任何反斜杠转义序列都会被处理。
实例:
例子如下:
3.6 re.subn
行为与 sub() 相同,但是返回一个元组 (字符串, 替换次数)。
实例:
例子如下:
4. 小结
这一小节,我们学习了正则表达式的基本语法,以及通过多个例子展示了正则表达式的使用方法,正则表达式难度较高,同学们需要多加练习,才能牢固地掌握。
正则表达式进阶——扒一扒scihub-cn源码
本文深入解析scihub-cn源码,稳定 源码 期货展示如何运用正则表达式解析文献信息。以一篇样例文献信息为例,分析scihub-cn源码正则表达式的解析过程,包括作者、标题、出版社(期刊名)和DOI的匹配。
样例文献信息为:“Mañas, P., & Pagán, R. (). Microbial inactivation by new technologies of food preservation. Journal of Applied Microbiology, (6), –. doi:./j.-...x”。
源码中的正则表达式拆分为四个组,分别匹配作者、标题、出版社(期刊名)和DOI。
匹配作者时,使用非贪婪模式,仅匹配到“Mañas, P., & Pagán, R.”,忽略后续信息。
为准确匹配,正则表达式中包含“(?驾校考题源码:.*?, )+”确保至少匹配到一个作者组,以及“'(?:.*?,s)+\w+'”确保至少匹配到一个数字/字母/下划线。
进一步匹配页码、标题、年份等信息,最终完整匹配所有作者信息。模式未结束,匹配到括号内的数字为年份。
完整解析过程分为四步:作者、标题、出版社(期刊名)、DOI。
匹配标题时,仅保留大写字母和非贪婪模式匹配任意字符至句点加空格,确保标题完整性。
出版社(期刊名)组匹配模式与标题组类似,确保期刊名首字母大写,匹配中间无句点,结尾句点加空格。
最后匹配DOI号时,排除期刊名、期号、页码等信息,仅匹配doi:或源码中正则表达式的应用,掌握其解析文献信息的核心逻辑和技巧,为后续类似项目提供参考和借鉴。
从数据自动生成正则表达式(附源码)
正则表达式,作为字符串匹配和处理的强大工具,几乎在所有编程语言中都有支持。其主要用途包括:匹配和查找、替换、数据验证等。对于有经验的开发者,从数据中提炼合适的正则表达式并非难事。然而,有没有可能让计算机自动生成这样的表达式呢?特别是当数据可能存在质量问题,包含错误或脏数据时,这一问题显得尤为重要。
在面对如下的药物批准文号数据时,很容易写出正则表达式:国药准字[BHZ]\d{ 8} 或 国药准字[A-Z]\d{ 8}。但自动生成这样的表达式是否可行呢?答案是肯定的。
在处理数据时,计算机必须考虑到脏数据的可能,比如数据不完整或格式错误。例如:“J 国药准字”或“国药准字”。这些问题需要在数据处理过程中进行识别和处理。
正则表达式的结构包括内容匹配符、数量限定符、位置限定符和逻辑或等元素,其中最底层的是原始字符,它们只能匹配自身。字符集合和元字符则涵盖了更广泛的字符集,如 \w、\d、\s 等,它们之间存在一定的包含关系。
字典树(Trie树)是一种用于统计、排序和保存大量字符串的高效数据结构,特别适用于文本词频统计。通过将数据插入字典树,可以生成正则表达式。首先,将所有数据分支组合为正则表达式的逻辑或形式,然后,根据子节点的数量和表达能力的层级,对字典树进行升级和合并,以提升正则表达式的泛化能力。
在升级合并操作中,如果节点的子节点数量超过阈值(例如3个),则提升节点的层级。如果节点的多个子节点值相同,进行合并,以简化表达式。同时,根据数据进入和终止的统计情况,对字典树进行剪枝操作,去除数据量少于平均值%的分支,以去除脏数据。
在生成正则表达式的过程中,还应考虑深度合并机制,如将重复的字符或元字符合并到其父节点,以简化表达式。此外,可以构建两棵字典树,一棵正序,另一棵逆序,以保留公共子串的特征,提高表达式的准确性。
整体算法流程包括升级、合并、剪枝和深度合并操作,直到字典树不再改变或节点升级到预设的最大层级。通过测试示例,可以验证生成的正则表达式的正确性和效率。
为了实现这一自动化过程,可以使用如 GitHub 上提供的完整代码库(github.com/mxnaxvex/Reg...)作为参考和实现依据。


2024-11-18 01:41
2024-11-18 00:35
2024-11-18 00:28
2024-11-18 00:17
2024-11-18 00:16
2024-11-18 00:08
2024-11-17 23:33
2024-11-17 23:10