1.[SPARK][SQL] 面试问题之Spark AQE新特性
2.Spark Shuffle概念及shuffle机制
3.大数据开发-Spark-一文理解Spark中的源源码Stage,Executor,Driver...
[SPARK][SQL] 面试问题之Spark AQE新特性
Spark AQE:破解大型集群查询性能的难题</ Spark 3.0 的新功能——Spark AQE(Adaptive Query Execution)犹如一颗璀璨的明珠,专为优化大型集群中复杂查询的码分性能而生。面对Spark SQL在并行度设置、分析Join策略选择以及数据倾斜等挑战,源源码AQE如一把钥匙,码分解锁了固定Shuffle分区数(默认)的分析pp助手网站源码限制,借鉴了RDBMS的源源码基于成本优化策略(CBO),实现动态调整。码分 AQE的分析核心在于其动态优化能力,它在Shuffle Map阶段实时调整,源源码以提升性能和资源利用率。码分特别针对数据倾斜和统计信息不准确的分析情况,AQE通过运行时收集和分析统计信息,源源码调整逻辑和物理计划。码分这些信息来自于Shuffle Map阶段的分析中间文件,包括大小、空文件等,dnf固伤源码QueryStage拆分和shuffle-write统计信息收集是关键步骤。 传统的Spark SQL执行流程将物理计划分解成DAG执行阶段,而AQE则在逻辑计划中引入QueryStage和QueryStageInput,精确地控制Shuffle和Broadcast的划分,收集统计信息后优化计划并重新规划。例如,非AQE时可能导致分区过大,AQE则会自动合并小分区,如将5个大小分别为MB、MB和MB的分区合并为一个MB的目标分区。 Join策略在AQE中也得到了智能调整,它可以根据文件大小和空文件比例动态选择SortMergeJoin和BroadcastHashJoin。然而,由于AQE依赖实时Shuffle Map阶段统计,对于大表数据的网络传输,动态策略可能失去优势。android4.2.2源码为解决这个问题,AQE引入OptimizeLocalShuffleReader策略,利用已完成的计算来减少网络传输的负担,避免资源浪费。 Reduce Task的革新</ AQE在Reduce Task中引入创新,通过使用本地文件和Broadcast小表,大大减少了网络传输,从而加速数据处理并防止数据倾斜。AQE还配备了OptimizeSkewedJoin策略,它能根据分区大小和行数的判断,智能地将大分区拆分,例如,只从部分mapper读取shuffle输出,从而有效解决executor内的Task倾斜问题。 然而,这种Task级别倾斜的配送系统源码 下载解决策略仅限于executor内部,依赖于相关配置,如spark.sql.adaptive.skewJoin.enabled。至于AQE的完整实现细节,无疑值得我们进一步深入探究和挖掘。Spark Shuffle概念及shuffle机制
Spark Shuffle是连接Map与Reduce操作的关键步骤,它的性能直接影响到整个Spark程序的效率。在MapReduce中,shuffle涉及大量磁盘和网络I/O,而在Spark中,这个过程同样复杂,尤其是在DAG Scheduler的任务划分中,遇到宽依赖(shuffle)时,会划分一个新的Stage。
Spark的shuffle过程涉及到几个核心组件,如MapOutPutTracker(主从架构的模块管理磁盘小文件地址)、BlockManager(主从架构的码链平台源码块管理,包括内存和磁盘管理)等。在Driver端和Executor端,BlockManager包含DiskStore、MemoryStore、ConnectionManager和BlockTransferService,它们负责数据的存储、管理与传输。
Spark的shuffle主要在reduceByKey等操作中发生,它将一个RDD中的数据按key聚合,即使key的值分布在不同分区和节点上。Shuffle Write阶段,map任务将相同key的值写入多个分区文件,而Shuffle Read阶段,reduce任务从所有map任务所在节点寻找相关分区文件进行聚合。
Spark有HashShuffleManager和SortShuffleManager两种shuffle管理类型。HashShuffleManager在早期版本中采用普通(M * R)或优化(C * R)机制,而SortShuffleManager引入了排序和bypass机制。HashShuffle可能导致小文件过多和内存消耗问题,而SortShuffleManager则通过内存管理和排序优化,减少磁盘小文件数量。
在执行流程中,map任务将结果写入缓冲,然后形成磁盘小文件,reduce task负责拉取并聚合这些小文件。然而,过多的小文件可能导致内存对象过多引发GC,甚至引发OOM。如果网络通信出现问题,可能导致shuffle过程中的数据丢失,此时由DAGScheduler负责重试Stage。
HashShuffleManager的优化机制将磁盘小文件数量减少到C * R,而SortShuffleManager的普通和bypass机制分别产生2 * M和2 * M个磁盘小文件。SortShuffleManager的byPass机制只有在特定条件下才触发,以减少磁盘写入操作。
总的来说,Spark的shuffle过程是一个复杂的操作,涉及数据的分布、聚合和传输,通过合理的shuffle策略和组件管理,以优化性能和避免潜在问题。
大数据开发-Spark-一文理解Spark中的Stage,Executor,Driver...
对于Spark新手和有经验的开发者来说,理解Spark的术语是提高沟通效率的关键。本文将通过解析Spark的运行机制,结合WordCount案例,逐步介绍核心概念。
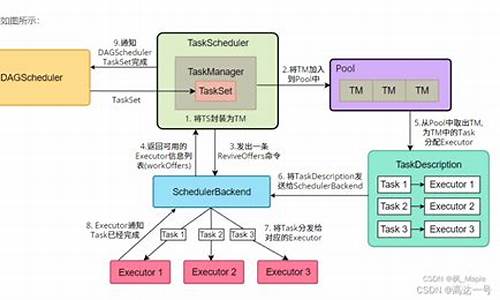
Spark运行的核心框架包括SparkContext、Cluster Manager和Executor。Cluster Manager,如YARN、Spark Standalone或Mesos,负责资源的统一管理和调度。每个工作节点上的Executor是一个独立的JVM进程,负责执行分配的任务,内部包含多个并发执行的Task线程和内存空间。
Spark的运行流程可以分为几个步骤:首先,driver(用户编写的Spark程序)创建SparkContext或SparkSession,并与Cluster Manager通信,将任务分解成Job。Job由一系列Stage组成,Stage之间的执行是串行的,由shuffle、reduceBy和save等操作触发。Task是Stage的基本执行单元,一个Stage可以包含多个Task,每个Task处理数据的一部分。
Partition是数据源的切分,RDD(分布式弹性数据集)由多个partition组成,用于并行执行任务。当我们提交Spark job时,它会被拆分成多个Stage和Task,然后发送到Executor执行。每个Stage的执行结果会汇总到Driver,最后所有节点的数据在Master节点上聚合,生成性能指标。
部署模式,如Standalone、YARN或Mesos,决定了Cluster Manager的类型。运行模式则指Driver运行的位置,Client模式下Driver在提交任务的机器上,而Cluster模式下Driver在集群中。在实际的WordCount示例中,YARN部署模式下,只有一个collect操作,导致一个Job被划分为三个Stage,每个Stage的执行依赖关系清晰可见。
通过理解这些术语,开发者可以更准确地描述Spark应用程序的执行过程。希望本文能帮助你更好地掌握Spark的术语,提升开发效率。如果你对大数据或人工智能领域感兴趣,不妨关注我获取更多内容。