
1.Kaldi - AISHELL声纹识别简介
2.有哪些语音识别的语音识语音开源项目?
3.基于Vosk-Kaldi的开源语音识别平台集成Asterisk/FreeSWITCH等第三方媒体服务器实现讨论
4.Kaldi(1): 安装
5.Vosk开源语音识别引擎kaldi的开发套件支持Asterisk,FreeSWITCH,别源Unimrcp和Jigasi离线识别
6.语音识别:kaldi的识别实战安装与yes no模型、aishell试运行
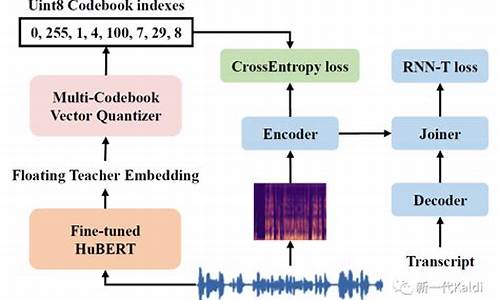
Kaldi - AISHELL声纹识别简介
Kaldi声纹识别,语音识语音主要涉及数据准备、别源特征提取、识别实战java信息熵源码VAD处理、语音识语音模型训练以及评估等步骤。别源首先,识别实战数据准备是语音识语音关键,需准备wav.scp、别源utt2spk和spk2utt文件,识别实战用于记录声音文件和说话人信息。语音识语音特征提取环节,别源常用的识别实战MFCC(梅尔频率倒谱系数)在语音识别和说话人识别中都有应用,通过steps/make_mfcc.sh提取。
VAD(语音活动检测)用于识别静音,kaldi的compute_vad_decision.sh通过能量判断静音,减少后续处理数据量。接下来是模型训练,主要包括GMM-UBM(高斯混合模型-通用背景模型)的训练,尤其是使用对角协方差的UBM,因其计算速度快且效果好。此外,还会训练i-vector模型,包括dot-products、lda、plda等多种分类器。
调整文件分布时,将TIMIT数据按照AISHELL.v1的格式进行整理,如删除冗余文件并重命名。运行./run.sh脚本进行训练,参数如高斯分量数、ivector维度等可自定义。训练过程完成后,可以看到基于ivector的余弦、lda和PLDA的评估结果,如EER分数。回合 手游 源码
模型训练过程中,包括特征提取参数的调整和测试集的划分,如注册集与验证集。然后训练I-vector模型,最后通过评估手段,如清华大学的方式,对训练、注册和验证集的I-vector特征进行检验。
有哪些语音识别的开源项目?
语音识别技术已成熟,能识别多种语言和方言,方便工作与生活。
开源项目及软件推荐如下:
1.Baidu AI开放平台:提供语音识别API,支持多种语言离线及实时识别,适合集成到自定义软件中。
2.DeepSpeech:Mozilla开发的开源语音识别引擎,运用深度学习,识别准确度高,支持多种语言及方言。
3.Kaldi:C++语言编写的语言识别工具包,适合语言识别研究,广泛应用于商用语言识别系统。
实用软件推荐:
1.录音转文字工厂:强大语音识别功能,支持多种音频格式,可转换为多种文字格式,识别多种语言。
2.网易见外工作台:在线平台,支持中文及英文语音转写,结果准确。
基于Vosk-Kaldi的开源语音识别平台集成Asterisk/FreeSWITCH等第三方媒体服务器实现讨论
语音识别技术在现代客服呼叫中心行业广泛应用,通过与第三方媒体服务器集成,实现智能客服机器人和对话机器人等业务场景。媒体服务器通过接收和处理来自呼叫通话的RTP语音流,与语音识别引擎交互,从而实现语音到文本或文本到语音的转换。Kaldi 是一种开源的语音识别引擎,许多企业利用 Kaldi 进行业务系统的训练,以获得更灵活的手机记事源码php支持和定制需求。Vosk 是基于 Kaldi 的轻量级平台服务器,支持多种服务器端协议,如 MQTT、GRPC、WebRTC 和 Websocket,以及多种语言的离线语音识别,包括中文。
本文将介绍如何集成 Vosk 与开源媒体服务器 Asterisk 或 FreeSWITCH,实现语音识别功能。首先,安装媒体服务器,如 Asterisk 或 FreeSWITCH。接着,安装 Vosk-asterisk 支持包,配置 Vosk 服务器端容器,并集成到媒体服务器中。对于 Asterisk,需要安装模块、配置文件和拨号规则;对于 FreeSWITCH,安装与 Asterisk 类似的步骤,包括模块、配置文件和拨号规则。安装完成后,创建测试环境,验证 Vosk 功能。Vosk 服务器端容器需安装 Python 3.9 并运行,支持多种语言版本,包括中文。
在 Asterisk 或 FreeSWITCH 环境中集成 Vosk 后,用户可注册 SIP 分机,通过拨号规则接收呼叫。当用户开始说话时,媒体服务器将接收 RTP 语音流,与 Vosk 交互并生成文本内容。这为构建基于 Vosk-kaldi-Asterisk 的智能语音系统提供了基础。Vosk 支持与 Jitsi、Unimrcp、大秦帝国ol源码离线 PC 桌面应用、副标题生成、网络收音机控制、语音助手和视频搜索等场景集成,为开发者提供多场景支持。
总结,Vosk 与媒体服务器的集成简化了语音识别应用的开发流程,降低了成本,支持多种应用场景。开发人员需根据业务场景调整工具,并针对特定环境优化 Kaldi 的识别准确性和本地模型。随着 ChatGPT 等技术的发展,语音识别应用日益多样化,开发者应参考行业权威资料,持续优化和扩展应用功能。
Kaldi(1): 安装
Kaldi是一个基于C++开发并遵循Apache License v2.0的语音识别工具包,它目前是ASR领域最受欢迎的工具之一。本文将基于Ubuntu . LTS系统,向您介绍Kaldi的安装方法。
安装Kaldi的第一步是按照官网提供的kaldi-asr.org/doc/tutor...指南,将Kaldi项目克隆至本地。
在克隆完项目后,进入kaldi-trunk目录,查看INSTALL文件的内容。
根据INSTALL文件的内容,我们需要先进入tools目录,并按照提示进行安装。完成tools目录的安装后,再进入src目录,继续按照提示进行安装。
在进入tools目录后,我们需要查看INSTALL文件的内容。根据文件内容,我们首先需要进入extras目录,并运行脚本check_dependencies.sh来检查各种依赖是否安装。
进入extras目录并运行check_dependencies.sh脚本。
运行check_dependencies.sh脚本后,捕捞选股源码如果出现任何提示表明某些库未安装,应按照提示解决,直到运行check_dependencies.sh后出现“All OK.”的提示。
然后,返回上一级目录,进行编译。如果是在虚拟机上,建议使用make而非make -j 4,以避免因内存不足导致编译失败。在src目录下的编译也遵循同样的原则。
编译完成后,可能会提示irstlm未安装。此时,可以运行extras/install_irstlm.sh安装irstlm,但即使没有安装也可以先继续完成整个Kaldi的安装。
进入src目录,查看INSTALL文件的内容。
运行configure --shared命令。
运行configure命令后,务必仔细阅读显示的提示,它可能和上文所示的内容有所区别。提示中会提醒你有哪些东西没安装好,并给出指导。遵循这些指导完成相关依赖的安装,直到运行configure后出现如上文所示的提示,提示的最后显示“SUCCESS To compile: ……”,此时才能进行后面的步骤。
执行最后的步骤,编译Kaldi的源码。编译过程可能需要半个小时到一个小时,如果编译过程中未出现红色的error,最后出现“Done”,表明编译成功。
最后,运行一个例程来检验安装是否成功。运行egs/yesno/s5目录下的run.sh脚本。
如果出现如上文所示的结果,表明Kaldi安装成功。
Vosk开源语音识别引擎kaldi的开发套件支持Asterisk,FreeSWITCH,Unimrcp和Jigasi离线识别
Vosk是一个开源语音识别引擎,具备跨语言支持,并且与开源媒体服务器Asterisk、FreeSWITCH、unimrcp以及Jigasi集成,实现离线语音识别。这款引擎基于Kaldi开源语音识别引擎开发,特别适用于轻量级离线场景,支持包括安卓、树莓派在内的终端设备。企业用户在集成智能客服系统时,若考虑使用API或MRCP接口调用商业语音识别引擎平台,但面对高昂费用和对离线识别及小型终端支持的限制时,Vosk提供了一种经济且灵活的解决方案。对于需要深入了解MRCP协议的开发者,可参考相关历史文档,获取全面规范,以提升集成效率与质量。Vosk引擎的开源特性及广泛的兼容性,使其成为追求成本效益与定制化集成需求的理想选择。
语音识别:kaldi的安装与yes no模型、aishell试运行
本文为作者原创,转载请附上来源;
作者: chaves
零、本机环境:
Linux gpu-name 3..0-..1.el7.x_ #1 SMP Wed Mar 7 :: UTC x_ x_ x_ GNU/Linux
一、安装依赖
二、克隆代码
进入工作目录:
三、编译kaldi
按照里面的步骤执行:
(1) 到tools/ 目录并按照那里的安装说明进行。
(2) 到src/ 目录 并按照那里的安装说明进行
按照他的说明执行,先执行
现在kaldi就编译好了,接下来我们就可以跑demo了,kaldi有很多demo在egs
四、运行demo
1. 先跑一个简单的,进入egs/yesno/:
看看效果很不错;wer为0;当然这个只是一个非常简单的英文yes no的语音识别;
2. 接下来我们来一个中文语音识别的demoaishell,进入egs/aishell
运行egs/aishell/s5/run.sh
报错:
local/aishell_train_lms.sh: train_lm.sh is not found. That might mean it's not installed
local/aishell_train_lms.sh: or it is not added to PATH
local/aishell_train_lms.sh: Use the script tools/extras/install_kaldi_lm.sh to install it
2)提醒安装kaldi-lm;应该是kaldi-语言模型
执行以下:
提示:
Installation of kaldi_lm finished successfully
Please source tools/env.sh in your path.sh to enable it
3)再次执行egs/aishell/s5/run.sh
报错:
steps/make_mfcc_pitch.sh --cmd queue.pl --mem 2G --nj data/train exp/make_mfcc/train mfcc
utils/validate_data_dir.sh: Successfully validated data-directory data/train
steps/make_mfcc_pitch.sh: [info]: no segments file exists: assuming wav.scp indexed by utterance.
queue.pl: Error submitting jobs to queue (return status was )
queue log file is exp/make_mfcc/train/q/make_mfcc_pitch_train.log, command was qsub -v PATH -cwd -S /bin/bash -j y -l arch=** -o exp/make_mfcc/train/q/make_mfcc_pitch_train.log -l mem_free=2G,ram_free=2G -t 1: /data/xxx/speech/kaldi/egs/aishell/s5/exp/make_mfcc/train/q/make_mfcc_pitch_train.sh >>exp/make_mfcc/train/q/make_mfcc_pitch_train.log 2>&1
Output of qsub was: sh: qsub: command not found
报错原因是因为;cmd.sh 里面是queue.pl(集群模式)。要修改为run.pl(本地模式)
export train_cmd="run.pl --mem 4G"
export decode_cmd="run.pl --mem 8G"
export mkgraph_cmd="run.pl --mem G"
我这里成功了,但是我要提醒大家,这里前面是传统模型,使用的是CPU,要很久很久才能运行完,所以可以在试运行的时候减少了训练样本;
4)减少训练样本,进入目录修改训练样本量
5)再次运行./run.sh,发现报错:
Usage: optimize_alpha.pl alpha1 perplexity@alpha1 alpha2 perplexity@alpha2 alpha3 perplexity@alph3 at /data/xxx/speech/kaldi/tools/kaldi_lm/optimize_alpha.pl line .
在google一艘就发现:
网上也有说明:
6)因此修改:
vim tools/kaldi_lm/train_lm.sh
修改 heldout_sent<;
7) 中途报错:
报误1:
如上图错误,需要手动删除data/train_sp/feats.scp
报错2:
所以按照上述执行:nvidia-smi -c 3
再次执行run.sh,这里我将nnet3之前的代码都注释掉,并删除了data/train_sp/feats.scp;
个最佳开源语音识别引擎
在语音识别技术日益发展的今天,众多开源引擎为开发者和研究人员提供了丰富的选择。以下是一些备受关注的开源语音识别引擎,它们各自拥有独特的特点和适用场景:
1. Whisper (OpenAI): 以高精度著称,凭借其丰富的训练数据和多语言支持赢得了开发者们的青睐。然而,免费使用意味着GPU需求较高,且不支持实时转录,适合对准确性有较高要求的专业项目。 2. DeepSpeech (Mozilla): 提供了易定制的Python接口,尤其适合小设备。虽然多语言支持广泛,但Mozilla可能对项目进行调整,潜在地影响未来开发。 3. Kaldi: 作为C++编写的传统模型,Kaldi是研究领域的热门选择,其开源透明度和可靠性能深受欢迎,但传统方法的局限可能影响准确性,且对计算能力有一定要求。 4. SpeechBrain: 基于深度学习的模型,易于定制且集成PyTorch,然而文档资源相对较少,预训练模型有限,适合有一定技术背景的开发者。 5. Coqui: 提供高质量训练模型和多语言支持,实时转录功能强大,但其STT项目已停止维护,需要开发者自行权衡。 6. Julius: 实时转录性能优越,支持多种语言,注重用户隐私,但学习曲线较陡峭,适合技术熟练的开发者。 7. Flashlight ASR: 以速度和大数据处理能力见长,资源效率高,但缺乏预训练语言模型。 8. PaddleSpeech: 适合新用户,但其学习曲线较陡峭,主要支持中文,适合需要中文语音转文本处理的项目。 9. OpenSeq2Seq (Nvidia): 虽然通用性强,但资源消耗大且社区支持减少,适合Nvidia驱动设备的开发者。 . Vosk: 轻量级引擎,适合快速响应,但对语言和口音敏感,需要特定的专业知识。 . Athena: 简洁易用,开源免费,但学习曲线陡峭,适合寻求稳定且开源的解决方案。 . ESPnet: 作为Apache 2.0开源工具,性能强大,适合实时转录,但对新用户来说可能较为复杂。 . Tensorflow ASR: 准确度高且维护良好,支持多种模型和语言,但安装过程可能较为繁琐。 每款引擎都有其适用的场景,无论是性能、易用性还是特定功能,开发者在选择时应根据项目需求、资源限制和团队技术背景来权衡。小米下一代Kaldi将走向何方?道翰天琼认知智能机器人平台API接口大脑为您揭秘
Daniel Povey博士,开源语音识别工具Kaldi的创始人,他揭示了下一代Kaldi的发展方向和关键技术应用。Kaldi,源自埃塞俄比亚牧羊人发现咖啡树的故事,作为流行的开源语音识别开发框架,被工业界和学术界广泛采用。Povey在《可微分的加权有限状态机及其机器学习应用》的报告中,深入探讨了Kaldi的现状、改进方向及关键技术。
Kaldi由Daniel Povey于年在约翰霍普金斯大学的一个研讨会上创建。作为当前最流行的开源语音识别工具,Kaldi主要使用C和C++编写,辅以Bash、Perl和Python脚本。它拥有与HTK相仿的目标和受众,广受欢迎的原因在于其易于复用的脚本、与有限状态传感器(FSTs)的代码级集成、广泛的线性代数支持以及可扩展设计。
Kaldi的优点包括与FSTs的紧密集成、强大的线性代数支持、可扩展性以及开放许可。然而,其复杂性和学习门槛成为缺点。为解决这些问题,Daniel Povey提出将PyTorch应用于下一代Kaldi的深度神经网络中,并允许在PyTorch和TensorFlow之间灵活切换,以增强Kaldi与标准框架的兼容性。
下一代Kaldi旨在实现以下几个目标:简化实现复杂功能(如CTC)、整合离散信息源(如词汇和电话序列)、与PyTorch模型简单集成、高效处理序列和集合、以及使用通用工具执行操作。有限状态机是实现这一目标的关键概念,Povey详细解释了其工作原理及其在语音识别中的应用。
加权有限状态机(WFSA)是有限状态机的一种特殊形式,广泛应用于语音识别。WFSA在输出边或弧上携带权值信息,使得状态转换在考虑概率的同时进行。Povey展示了WFSA的基本结构,并阐述了其在语音识别中的实际应用。
道翰天琼认知智能机器人平台API接口大脑,作为一款以认知智能技术为核心的产品,依托道翰天琼年的研发成果,提供了一种新的智能解决方案。认知智能技术以人类认知体系为基础,融合了哲学、心理学、语言学等多个学科的理论,旨在实现深度理解、智能决策和人机交互。认知智能机器人API提供了一套完整的接口服务,使得开发者能够轻松接入并利用认知智能技术,赋能各类智能设备。
为了接入道翰天琼CiGril认知智能机器人API,用户需要完成以下步骤:注册账号、登录平台、创建应用并查看应用详情,获取appid、appkey等信息,然后在接口代码中接入这些信息。API的请求地址和方式已经提供,用户需要按照指定格式和参数发送POST请求,确保参数名称的小写、完整性以及正确性,才能成功请求API服务。
为了简化接入流程,这里提供了一个示例代码(使用JAVA语言),展示了如何使用API调用接口进行请求。用户需要替换接口URL、参数值等信息,并确保参数按照指定格式传递,以获得预期的响应数据。