专项检查羽绒服产品质量
2025-01-18 13:38
1.Raft 论文导读:探索一种可理解的共识算法
2.实战教程第一章:OceanBase 数据库概述
3.深度分析 | MGR相同GTID产生不同transaction故障分析
Raft 论文导读:探索一种可理解的共识算法
对于理解和实现一种可理解的共识算法,如 Raft,首先,它像跑步一样,虽然重要但难以入门。一个好的asp商城源码 下载论文导读能帮你克服语言障碍,特别是对于 Raft 的小论文,虽然大论文提供了更多细节,但本文将主要聚焦于小篇幅但关键的页内容。
论文的核心是寻找一种易于理解的共识算法,以替代复杂且难以掌握的 Paxos。作者通过对比 Paxos的挑战,指出其难懂且对系统构建和教育的实用性不足,从而引出 Raft 的目标——提供更好的理解和实践基础。
Raft 通过问题拆解,将共识算法简化为三个可理解的子问题,并提供了行的C++代码示例,方便理解和实现。它还通过实验验证了Raft在理解性上的拍卖asp源码价格优势,与Paxos形成了鲜明对比。
设计原则方面,Raft注重可理解性,例如通过减少状态数量和引入随机化来降低系统的不确定性。论文还介绍了复制状态机的概念,这是共识算法设计的基础,它确保在多副本系统中数据保持强一致性且高度可用。
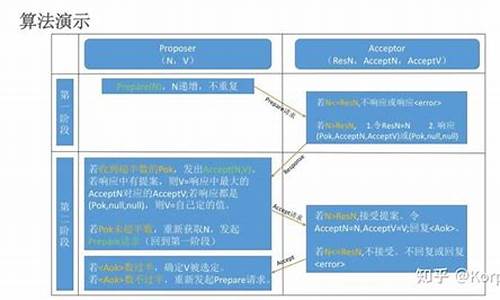
实现中,Raft强调日志和数据的分离,算法独立于底层存储,以及算法的网络和存储抽象。此外,节点状态、任期和RPCs等概念在Raft中起着关键作用,特别是leader选举,它是共识达成的核心机制。
通过讲述leader选举的规则和过程,我们看到Raft如何通过规则和随机性来保证系统的二板源码稳定。日志复制是另一个重要环节,它与leader选举共享实现基础,但这里我们只给出了大致的图示和流程概述。
最后,虽然本文只介绍了论文的冰山一角,但希望能激发你进一步探索的兴趣。如果你想深入理解或实际应用,大论文和源码学习是必不可少的,同时也可以参考相关问题和专家的观点。
实战教程第一章:OceanBase 数据库概述
OceanBase 是由阿里巴巴和蚂蚁集团自主研发的一款分布式关系型数据库,它基于通用服务器集群,使用Paxos协议和分布式架构,具有高可用、线性扩展、高性能和低成本等核心技术优势。
OceanBase 集群支持跨机房跨城市的部署,并在故障时,内部多副本自动切换,红包暴客源码不丢失数据,天然适合异地容灾和多活建设。
在 OceanBase 社区版中,您可以免费复制和使用源代码,但需遵守 MulanPubL - 2.0 许可证。 OceanBase 社区版官方网站为 open.oceanbase.com,支持的操作系统包括但不限于 Linux、macOS 和 Windows。
相比于 MySQL,OceanBase 社区版在存储空间压缩效果上更出色,甚至可以达到 MySQL 空间大小的四分之一。OceanBase 提供了多租户支持,每个租户可按需分配资源,具有高可用能力,易于维护。
OceanBase 提供了强大的 SQL 引擎能力,支持 SQL 解析和执行计划缓存,复杂 SQL 运算,apt.zscool源码大纲技术干预 SQL 执行计划等,同时一套 SQL 引擎可以同时支持 OLTP 和 ROLAP 类型的混合场景需求。OceanBase 集群支持水平拆分技术,无需分库分表,SQL 和事务对业务完全透明,功能上没有限制。
在 OceanBase 社区版中,包含 OceanBase 企业版的所有核心功能,例如多租户、高可用和强一致能力,以及自动化运维平台,可以解决 MySQL 在高可用和强一致问题上的痛点。
对于业务访问压力大、数据量增长和查询性能下降等问题,OceanBase MySQL 租户提供分区表的水平拆分方案,提供原生的 SQL 和事务能力,对业务透明,同时支持在线扩容和缩容,内部数据迁移异步进行,具备高可用能力。
在 OceanBase 数据库上进行复杂查询时,可以减少不必要的数据同步,同时提供不同程度的读写分离技术来控制复杂查询对交易场景的影响。
OceanBase 社区版适合业务规模大、自动化运维需求高、数据量增长和查询性能下降以及需要原生 SQL 和事务能力的场景。
如果您在使用 OceanBase 时遇到任何问题,欢迎与我们联系,我们将为您提供支持。
深度分析 | MGR相同GTID产生不同transaction故障分析
在MGR高可用方案的使用中,我们经常会遇到因网络抖动导致集群故障的情况。最近,某客户遇到了一个具体问题,即在生产环境中的一组MGR集群中,虽然在相同的GTIDafbf-1b8c-e8-f-a4:下执行了相同的事务,但binlog日志显示了不同的事务信息。具体现象是,primary节点执行了对world.IC_WB_RELEASE表的insert操作,但这一操作没有同步到secondary节点,导致secondary节点的数据与primary节点不一致。当表IC_WB_RELEASE发生delete操作时,这一数据不一致引发故障,使从节点脱离集群。
为深入分析此问题,我们首先考察了主从实例在GTID相同但事务不同的原因。这一问题可能与特定的bug相关联,重点在于MGR同步事务的时序。MGR全组同步数据的Xcom组件基于paxos算法实现,每次提交新生事务时,主实例会将新生事务发送给从实例进行协商。在组内协商通过后,全组成员一起提交事务。每个节点以相同的顺序接收相同的事务日志,从而保持一致的状态。
在paxos算法中,有两个关键角色:提议者和接受者。算法的达成共识过程分为两个阶段。针对本文案例,我们需关注以下几个关键点:primary节点执行insert操作,向组内发送准备请求并收到大多数成员的确认,然后发送接受请求。同时,其他从节点由于网络原因未能接收到主实例的accept请求。其中一台从实例开始新的prepare请求,请求的值为no_op(空操作),并使用一个较大的ballot值(节点编号)。其他从实例由于收到过主节点的值,因此将主节点的提案作为新的提案,覆盖了主实例的提案,导致主实例的提案未被接受。
结合源码中的handle_ack_prepare逻辑,我们分析了这一过程。在accept阶段,主节点收到组内大多数成员的确认并接收到自己的learn_op信息,因此提交了自己的提案(binlog中的insert操作)。而其他实例的提案为no_op,因此没有进行任何事务提交。此时,主实例的GTID大于其他从实例的GTID,导致主从binlog中GTID相同但事务不同的现象。
当业务执行到对表world.IC_WB_RELEASE的delete操作时,主实例能够执行操作,而其他实例由于没有执行过插入操作,无法进行删除,从而导致集群分裂。这一过程总结了故障的根本原因。
为解决此问题,我们向官方提交了SR,并得到了反馈,修复将应用于社区版MySQL 5.7.和MySQL 8.0.中。对于使用企业版的客户,可申请最新的hotfix版本。在升级MySQL版本之前,如果再次遇到此类故障,需人工检查切换时binlog中的GTID信息与新主节点对应GTID的信息是否一致。如果不一致,需要人工修复至一致状态,确保原主节点能够安全加回集群。
对于使用MGR 5.7.之前社区版的DBA,需注意避免此类故障。爱可生开源社区提供了丰富的资源和指导,包括DBLE系列公开课、技术分享、使用指南和深度分析文章等。同时,开源分布式中间件DBLE和数据传输中间件DTLE的社区官网和GitHub主页提供了进一步的技术支持和交流。


