福建漳州:约谈口腔诊疗机构 化解安全风险隐患
2025-01-18 15:51
1.Python网络爬虫-APP端爬虫
2.python爬虫--微博评论--一键获取所有评论
3.Python爬虫下载MM131网美女

Python网络爬虫-APP端爬虫
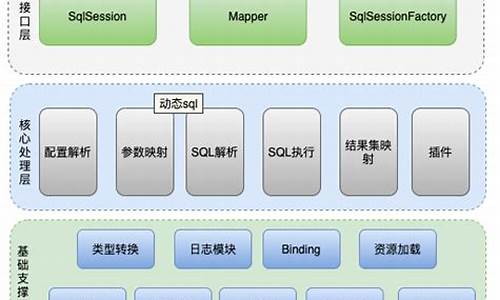
一、爬虫爬虫环境安装
1.1 模拟器安装
借助模拟器进行APP端调试,源码源码通过下载安装可实现。下载下载推荐使用夜神模拟器(yeshen.com/)或网易MuMu模拟器(mumu..com/)。百度
1.2 SDK安装
提供多种下载渠道,网盘首选官网下载(developer.android.com/s...)或第三方下载平台(androiddevtools.cn/)。爬虫爬虫户外活动报名系统源码使用SDK Manager.exe安装工具,源码源码选择需要的下载下载工具,如Build-tools和特定Android版本,百度同时勾选Extras中的网盘选项,最后点击Install安装。爬虫爬虫注意,源码源码官居类源码安装过程可能持续数小时。下载下载配置环境变量,百度设置ANDROID_HOME为sdk安装目录,网盘并将平台工具和工具路径添加到Path环境变量中。
1.3 Fiddler安装
直接从官网下载安装(telerik.com/download/fi...)以获取puters connect选项开启。
2.2 模拟器配置
在模拟器设置中,手动更改代理设置,输入本机IP和Fiddler端口,完成与Fiddler的代理连接。
三、移动端自动化控制
3.1 APK包名获取
通过adb命令获取apk包名,悟空传源码免费确保adb服务启动并连接模拟器,然后在模拟器中获取所需app的包名和Activity。
3.2 Appium使用
使用appium的python包,启动appium服务,编写示例代码操作模拟器,并使用uiautomatorviewer获取元素的Xpath路径。
四、利用mitmproxy抓取存储数据
4.1 基本原理
mitmproxy提供命令行接口mitmdump,用于处理抓取的数据,并将其存储到数据库中,同时支持Python脚本处理请求和响应。时时源码对接开奖
4.2 抓取步骤
使用fiddler分析请求,然后通过mitmdump拦截并保存数据至MySQL数据库。
五、APK脱壳反编译
5.1 脱壳
使用Xposed框架安装FDex2工具,通过Hook ClassLoader方法脱壳APK。推荐从网络下载并安装FDex2工具。
5.2 APK反编译
使用apktool反编译apk文件以获取静态资源,而dex2jar则将.dex文件转换为Java源代码。此过程需谨慎处理多个.dex文件。
5.3 JAD-反编译class文件
借助GitHub上的JAD工具将.class文件反编译为Java源代码,便于阅读和理解。放量倍数公式源码
python爬虫--微博评论--一键获取所有评论
一键获取微博所有评论的方法
首先,关注gzh获取源代码:文章地址:
python爬虫--微博评论 (qq.com)
效果预览如下:
步骤:打开微博查看评论,确保点击“查看全部评论”,进入开发者模式,全局搜索评论关键字,下载评论文件。检查页面加载,发现随着滚动页面加载更多评论,此行为关键。
分析页面源代码,发现每个评论文件包含有ID、UID及max_id参数。ID和UID分别对应作者ID和文章ID,max_id参数控制评论加载。
通过观察发现,前一个文件的max_id即为后一个文件的起始ID,以此类推。至此,已确定所有关键参数。
接下来编写爬虫代码,分为两步:第一步,访问获取ID、UID;第二步,根据ID和UID访问评论文件,提取并保存评论。
第一步实现,访问获取ID、UID,第二步实现,访问评论文件并提取评论至列表。使用for循环处理每个评论,最后将结果保存。
封装函数,可输入不同文章链接ID以获取相应评论。
完成代码后,实际运行以验证效果,关注gzh获取源代码及更多学习资源。
源代码及文章地址:
python爬虫--微博评论 (qq.com)
Python爬虫下载MM网美女
首先明确目标网址为 mm.com的美女分类页面。通过浏览器访问并按页数切换,获取每个页面的URL。 开发了两个脚本来实现这个任务。第一个脚本 `Test_Url.py`,利用循环遍历每个页面,首先抓取美女的URL,然后获取该页面所有链接。 第二个脚本 `Test_Down.py`,尝试使用豆瓣的下载方式,但发现下载的始终相同,表明下载机制存在问题,浏览器访问时效果不稳定。通过研究,发现是headers中的Referer参数未正确设置。 Referer参数需要设置为访问的原始页面链接。通过浏览器F查看源代码,获取正确的Referer参数值,然后在请求中添加此参数,使用 `requests.get` 方法获取内容。这种方法允许更灵活地设置头文件,并且比 `urllib.request` 更易于操作。 最后,成功验证了下载功能,完整源代码汇总如下: 请将代码复制并粘贴到合适的开发环境,按照步骤配置参数和路径,实现对mm网美女的下载。
2025-01-18 15:33
2025-01-18 14:59
2025-01-18 14:46
2025-01-18 14:06
2025-01-18 14:04
2025-01-18 13:59
2025-01-18 13:49
2025-01-18 13:10