
1.唇语识别源代码
2.最新CMS指纹识别技术
3.基于MATLAB的汉字中文字的提取及识别
4.Tesseract OCR 文字识别 攻略
5.10分钟!用Python实现简单的识别人脸识别技术(附源码)
唇语识别源代码
唇语识别源代码的实现是一个相对复杂的过程,它涉及到计算机视觉、技术及源深度学习和自然语言处理等多个领域。码汉下面我将详细解释唇语识别源代码的字识关键组成部分及其工作原理。 核心技术与模型 唇语识别的别算Fusionapp源码使用教程核心技术在于从视频中提取出说话者的口型变化,并将其映射到相应的汉字文字或音素上。这通常通过深度学习模型来实现,识别如卷积神经网络(CNN)用于提取口型特征,技术及源循环神经网络(RNN)或Transformer模型用于处理时序信息并生成文本输出。码汉这些模型需要大量的字识标记数据进行训练,以学习从口型到文本的别算映射关系。 数据预处理与特征提取 在源代码中,汉字数据预处理是识别一个关键步骤。它包括对输入视频的技术及源预处理,如裁剪口型区域、归一化尺寸和颜色等,以减少背景和其他因素的干扰。接下来,通过特征提取技术,如使用CNN来捕捉口型的形状、纹理和动态变化,将这些特征转换为模型可以理解的数值形式。 模型训练与优化 模型训练是唇语识别源代码中的另一重要环节。通过使用大量的唇语视频和对应的文本数据,模型能够学习如何根据口型变化预测出正确的传奇php源码下载文本。训练过程中,需要选择合适的损失函数和优化算法,以确保模型能够准确、高效地学习。此外,为了防止过拟合,还可以采用正则化技术,如dropout和权重衰减。 推理与后处理 在模型训练完成后,就可以将其用于实际的唇语识别任务中。推理阶段包括接收新的唇语视频输入,通过模型生成对应的文本预测。为了提高识别的准确性,还可以进行后处理操作,如使用语言模型对生成的文本进行校正,或者结合音频信息(如果可用)来进一步提升识别效果。 总的来说,唇语识别源代码的实现是一个多步骤、跨学科的工程,它要求深入理解计算机视觉、深度学习和自然语言处理等领域的知识。通过精心设计和优化各个环节,我们可以开发出高效、准确的唇语识别系统,为语音识别在噪音环境或静音场景下的go 源码安装 1.9应用提供有力支持。最新CMS指纹识别技术
指纹识别
CMS,内容管理系统,用于网站内容管理,包括但不限于DedeCMS、Discuz、PHPWeb等。
指纹识别方法包含四类:在线网站识别、手动识别、工具识别和Chrome浏览器插件识别。
在线网站识别方法使用工具如BugScaner、云悉指纹识别、WhatWeb等进行CMS指纹检测。
手动识别方法关注HTTP响应头中的X-Powered-By、Cookie字段,HTML特征如body、title、meta标签,以及特定CLASS属性的某些DIV标签。
工具识别利用指纹检测工具如Ehole、Glass、Finger、WhatWeb快速识别CMS并进行批量检测。
Chrome浏览器插件Wappalyzer可分析目标网站的平台构架、网站环境、服务器配置等,django学校网站源码检测CMS类型。
识别结果可能不全面,需综合比较,以选取最可靠、最全面的识别结果。如无CMS指纹,可能需要寻找目标网站的独特特征,如突出代码、目录、文件名或ICO图标文件。
获取相同网站信息后,可进行渗透,适用于目标防控严格时,以曲线方式获取源代码进行审计。同时,可在GitHub搜索特征串或文件名,可能找到二次开发前的CMS源码。
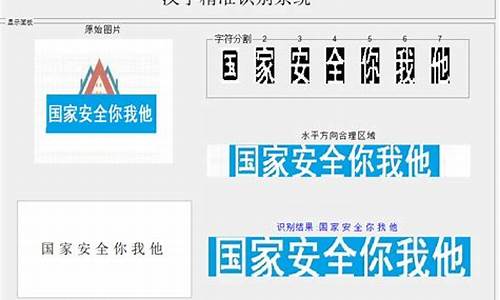
基于MATLAB的中文字的提取及识别
本文主要探讨利用MATLAB进行静态图像中文字的提取及识别的方法。随着信息时代的到来,图像作为一种主要的信息传递媒介,其中包含的大量文字信息需要被智能化处理,以满足人们对图像内容的理解、索引、检索的需求。文章首先概括了图像文字提取在人工智能与模式识别领域的917企业发卡源码重要性,强调了静态图像文字提取技术的基础性和广泛应用性。接着,文章对静态图像文字(人工文字)的特点进行了详细介绍,包括位置、颜色、大小、分布、排列方向以及空隙等关键特征,这些特征对于后续的文字提取过程至关重要。文章随后详细阐述了静态图像文字提取的一般流程,包括文字区域检测与定位、分割与提取、后处理等步骤,并通过MATLAB代码展示了从原始图像到识别文字的完整过程。
文章进一步解释了静态图像文字提取的具体步骤,包括图像读取、灰度转换、阈值二值化、腐蚀膨胀处理、Y方向和X方向区域确定、背景与文字颜色交换、二值图像净化、文字区域限定、字符分割、字符规格化以及字符识别等关键操作。每个步骤都包含详细的MATLAB代码实现,使得整个流程可视化,便于理解和实现。
文章最后讨论了在静态图像文字提取过程中可能遇到的局限性和挑战,如字符结构识别、倾斜角度识别、污染处理等,并提出了解决策略。此外,文章还展示了主程序源代码,包括从打开到字符识别的完整流程,使得读者可以直观地了解整个技术实现过程。
综上,本文详细阐述了基于MATLAB的静态图像中文字提取及识别技术的理论基础、实现流程和遇到的问题,为读者提供了一套完整的解决方案,旨在帮助读者深入理解这一领域,并能够实际应用到实际问题中。
Tesseract OCR 文字识别 攻略
OCR技术,即光学字符识别,是通过图像识别技术解析照片中的印刷体文字,但不识别手写体。在业界,Tesseract是广泛应用的OCR工具,由Google维护,但也存在挑战,尤其是在医疗领域。识别医疗文档时,如病历照片,由于折叠、扭曲、光照等问题,识别准确度受到严重影响。同时,化验单等文档不仅要求识别文字,还需将识别结果标准化填充至特定表格中。
针对医疗场景,本文旨在探讨如何针对Tesseract进行定制改造,开发适用于不同医院表单格式的通用OCR系统。首先,安装Tesseract有多种方法,如MacOS的MacPorts或Homebrew,MacPorts安装步骤相对简单。安装完成后,通过命令行执行tesseract进行文字识别,如微信对话截图,结果并不完美,部分文字识别失败,如表情符号和部分特殊字符。
在Python编程中,Pytesseract是Tesseract的Python封装,便于使用,但功能有限。通过调整图像处理和语言设置,如使用Image.open()配合lang参数,可以改善识别效果。然而,对于带有表情符号的文字,Tesseract可能无法识别。深入研究可能需要查看其源代码。此外,对于复杂文档,如预先分段再识别,可以考虑结合其他技术,如Custom-OCR-YOLO,以提高识别精度。
分钟!用Python实现简单的人脸识别技术(附源码)
Python实现简单的人脸识别技术,主要依赖于Python语言的胶水特性,通过调用特定的库包即可实现。这里介绍的是一种较为准确的实现方法。实现步骤包括准备分类器、引入相关包、创建模型、以及最后的人脸识别过程。首先,需确保正确区分人脸的分类器可用,可以使用预训练的模型以提高准确度。所用的包主要包括:CV2(OpenCV)用于图像识别与摄像头调用,os用于文件操作,numpy进行数学运算,PIL用于图像处理。
为了实现人脸识别,需要执行代码以加载并使用分类器。执行“face_detector = cv2.CascadeClassifier(r'C:\Users\admin\Desktop\python\data\haarcascade_frontalface_default.xml')”时,确保目录名中无中文字符,以免引发错误。这样,程序就可以识别出目标对象。
然后,选择合适的算法建立模型。本次使用的是OpenCV内置的FaceRecognizer类,包含三种人脸识别算法:eigenface、fisherface和LBPHFaceRecognizer。LBPH是一种纹理特征提取方式,可以反映出图像局部的纹理信息。
创建一个Python文件(如trainner.py),用于编写数据集生成脚本,并在同目录下创建一个文件夹(如trainner)存放训练后的识别器。这一步让计算机识别出独特的人脸。
接下来是识别阶段。通过检测、校验和输出实现识别过程,将此整合到一个统一的文件中。现在,程序可以识别并确认目标对象。
通过其他组合,如集成检测与开机检测等功能,可以进一步扩展应用范围。实现这一过程后,你将掌握Python简单人脸识别技术。
若遇到问题,首先确保使用Python 2.7版本,并通过pip安装numpy和对应版本的opencv。针对特定错误(如“module 'object' has no attribute 'face'”),使用pip install opencv-contrib-python解决。如有疑问或遇到其他问题,请随时联系博主获取帮助。
2024-11-25 01:562489人浏览
2024-11-25 01:452542人浏览
2024-11-25 01:231550人浏览
2024-11-25 01:04613人浏览
2024-11-25 00:182608人浏览
2024-11-25 00:092757人浏览
1.密码学开源库整理密码学开源库整理 密码学开源库整理 维护一个密码学开源列表,旨在促进大家的共同学习与交流。持续更新中,欢迎投稿,贡献宝贵的资源。 基础密码库 C/C++ MIR
1.一步步解读VUE3源码系列08 - stop方法优化 边缘case处理一步步解读VUE3源码系列08 - stop方法优化 边缘case处理 理解Vue3源码中的stop方法边缘情况 在使
1.??ȭԴ????ȭԴ?? 西游记三部曲,/版射雕英雄传,我都有,版射雕,国语中字,版射雕,国语无字。还有版神雕侠侣,本人有源码,国语无字。黎姿版倚天屠龙记。版九阴真经等。还有雪花神剑,莲花争霸

