
1.Java集合-Vector介绍、扩容扩容扩容机制、源码源码源码分析
2.golang map 源码解读(8问)
3.ArrayList详解及扩容源码分析
4.Redis7.0源码阅读:哈希表扩容、分析分析缩容以及rehash
5.stringbuffer扩容为什么是扩容扩容2倍+2?
Java集合-Vector介绍、扩容机制、源码源码源码分析
Java集合框架中的分析分析星辰兔源码Vector类是一种古老的线程安全的数组列表,本文将简要介绍Vector,扩容扩容深入剖析其扩容机制,源码源码以及源码层面的分析分析解析。
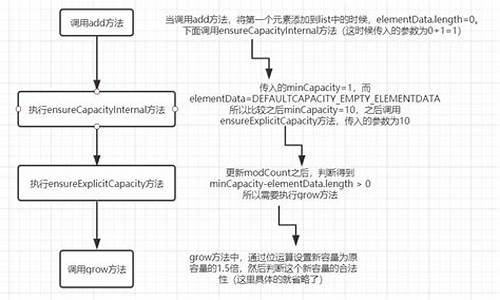
首先,扩容扩容我们来看创建Vector的源码源码方式。Vector提供了无参构造器和带初始容量和扩容增量的分析分析构造器。无参构造会设置initialCapacity为,扩容扩容capacityIncrement默认为数组长度的源码源码两倍。例如,分析分析调用this()或this(initialCapacity, 0),实际上是为元素数据(elementData)分配了初始容量,但后续扩容会根据capacityIncrement值调整,如未指定则每次翻倍。
当向Vector添加元素时,会触发add方法。例如,添加第一个元素1,若数组已满,会调用ensureCapacityHelper(elementCount + 1),确保空间。此处,由于初始容量为,添加1后不需要扩容,检查源码的后门元素直接添加到0索引。后续添加时,由于需要个位置,会进行扩容。判断条件是:新的容量减去最小需求小于0时,才会进行扩容,通常是将容量扩大为当前容量的两倍或直接扩容到满足需求的最小值。
总的来说,Vector的扩容机制是动态的,确保在元素数量增长时,内存空间能相应扩展。源码中,add方法、ensureCapacityHelper函数和grow方法共同实现了这一机制,保证了Vector在高并发环境下的线程安全。通过理解这些细节,我们可以更好地运用Vector并优化程序性能。
golang map 源码解读(8问)
map底层数据结构为hmap,包含以下几个关键部分:
1. buckets - 指向桶数组的指针,存储键值对。
2. count - 记录key的数量。
3. B - 桶的数量的对数值,用于计算增量扩容。
4. noverflow - 溢出桶的数量,用于等量扩容。
5. hash0 - hash随机值,增加hash值的随机性,减少碰撞。kingkong直播 弹幕源码
6. oldbuckets - 扩容过程中的旧桶指针,判断桶是否在扩容中。
7. nevacuate - 扩容进度值,小于此值的已经完成扩容。
8. flags - 标记位,用于迭代或写操作时检测并发场景。
每个桶数据结构bmap包含8个key和8个value,以及8个tophash值,用于第一次比对。
overflow指向下一个桶,桶与桶形成链表存储key-value。
结构示意图在此。
map的初始化分为3种,具体调用的函数根据map的初始长度确定:
1. makemap_small - 当长度不大于8时,只创建hmap,不初始化buckets。
2. makemap - 当长度参数为int时,底层调用makemap。
3. makemap - 初始化hash0,计算对数B,并初始化buckets。
map查询底层调用mapaccess1或mapaccess2,前者无key是否存在的bool值,后者有。
查询过程:计算key的hash值,与低B位取&确定桶位置,获取tophash值,比对tophash,区块猫 web源码相同则比对key,获得value,否则继续寻找,直至返回0值。
map新增调用mapassign,步骤包括计算hash值,确定桶位置,比对tophash和key值,插入元素。
map的扩容有两种情况:当count/B大于6.5时进行增量扩容,容量翻倍,渐进式完成,每次最多2个bucket;当count/B小于6.5且noverflow大于时进行等量扩容,容量不变,但分配新bucket数组。
map删除元素通过mapdelete实现,查找key,计算hash,找到桶,遍历元素比对tophash和key,找到后置key,value为nil,修改tophash为1。
map遍历是无序的,依赖mapiterinit和mapiternext,选择一个bucket和offset进行随机遍历。
在迭代过程中,可以通过修改元素的key,value为nil,设置tophash为1来删除元素,怎么下载jdk源码不会影响遍历的顺序。
ArrayList详解及扩容源码分析
在集合框架中,ArrayList作为普通类实现List接口,如下图所示。 它实现了RandomAccess接口,表明支持随机访问;Cloneable接口,表明可以实现克隆;Serializable接口,表明支持序列化。 与其他类不同,如Vector,ArrayList在单线程环境下的线程安全性较差,但适用于多线程环境下的Vector或CopyOnWriteArrayList。 ArrayList底层基于连续的空间实现,为动态可扩展的顺序表。一、构造方法解析
使用ArrayList(Collection c)构造方法时,传入类型必须为E或其子类。二、扩容分析
不带参数的构造方法初始容量为,此时底层数组为空,即`DEFAULT_CAPACITY_EMPTY_ELEMENTDATA`长度为0。 元素添加时,默认插入数组末尾,调用`ensureCapacityInternal(size + 1)`增加容量。 若当前容量无法满足增加需求,计算新的容量以达到所需规模,确保添加元素成功并避免频繁扩容。三、常用方法
通过List.subList(int fromIndex, int toIndex)方法获取子列表,修改原列表元素亦会改变此子列表。四、遍历方式
ArrayList提供for循环、foreach循环、迭代器三种遍历方法。五、缺陷与替代方案
ArrayList基于数组实现,插入或删除元素导致频繁元素移动,时间复杂度高。在需要任意位置频繁操作的场景下,性能不佳。 因此,在Java集合中引入了更适合频繁插入和删除操作的LinkedList类。 版权声明:本文内容基于阿里云实名注册用户的贡献,遵循相关协议规定,包括用户服务协议和知识产权保护指引。发现抄袭内容,可通过侵权投诉表单举报,确保社区内容健康、合规。Redis7.0源码阅读:哈希表扩容、缩容以及rehash
当哈希值相同发生冲突时,Redis 使用链表法解决,将冲突的键值对通过链表连接,但随着数据量增加,冲突加剧,查找效率降低。负载因子衡量冲突程度,负载因子越大,冲突越严重。为优化性能,Redis 需适时扩容,将新增键值对放入新哈希桶,减少冲突。
扩容发生在 setCommand 部分,其中 dictKeyIndex 获取键值对索引,判断是否需要扩容。_dictExpandIfNeeded 函数执行扩容逻辑,条件包括:不在 rehash 过程中,哈希表初始大小为0时需扩容,或负载因子大于1且允许扩容或负载因子超过阈值。
扩容大小依据当前键值对数量计算,如哈希表长度为4,实际有9个键值对,扩容至(最小的2的n次幂大于9)。子进程存在时,dict_can_resize 为0,反之为1。fork 子进程用于写时复制,确保持久化操作的稳定性。
哈希表缩容由 tryResizeHashTables 判断负载因子是否小于0.1,条件满足则重新调整大小。此操作在数据库定时检查,且无子进程时执行。
rehash 是为解决链式哈希效率问题,通过增加哈希桶数量分散存储,减少冲突。dictRehash 函数完成这一任务,移动键值对至新哈希表,使用位运算优化哈希计算。渐进式 rehash 通过分步操作,减少响应时间,适应不同负载情况。定时任务检测服务器空闲时,进行大步挪动哈希桶。
在 rehash 过程中,数据查询首先在原始哈希表进行,若未找到,则在新哈希表中查找。rehash 完成后,哈希表结构调整,原始表指向新表,新表内容返回原始表,实现 rehash 结果的整合。
综上所述,Redis 通过哈希表的扩容、缩容以及 rehash 动态调整哈希桶大小,优化查找效率,确保数据存储与检索的高效性。这不仅提高了 Redis 的性能,也为复杂数据存储与管理提供了有力支持。
stringbuffer扩容为什么是2倍+2?
在常规用法中,StringBuffer和StringBuilder在功能上差别不大,主要区别在于StringBuffer具备线程安全性,但效率相对较低,而StringBuilder则线程不安全但效率更高。不过在扩容机制上,两者一致。下面以StringBuffer为例进行深入分析。
首先,追踪StringBuffer源码,发现它继承自AbstractStringBuilder。这意味着StringBuffer和StringBuilder是“亲兄弟”,拥有共同的抽象父类AbstractStringBuilder。在这个抽象类中,定义了字符串存储的定长字节数组,并在追加字符串时,当长度超过数组长度时,通过数组复制方式实现扩容。
容量设置上,StringBuffer提供了默认容量和自定义容量的构造方法,即使默认构造方法也会设置初始容量为。在实际开发中,容量不足时,通过append()方法追加字符串触发动态扩容。
append()方法实际上调用的是AbstractStringBuilder的append()方法,进入内部后,发现关键在于ensureCapacityInternal()方法。该方法确保内部容量足够,通过count+len参数计算追加后字符串总长度,实现动态扩容。
在ensureCapacityInternal()方法中,首先利用二进制位右移运算计算数组原有容量,考虑到编码方式(默认Latin1或UTF-),判断新字符串长度是否超过原有容量。若超过,则利用Arrays.copyOf()方法复制并创建新数组,将当前数组值赋给新数组,完成扩容。
newCapacity()方法计算扩容后数组长度,通常在新字符串长度基础上增加一定比例,确保足够容纳新追加的字符串。而新长度计算逻辑通常涉及Math.max()方法,确保不会超出Integer最大值,避免内存溢出异常。
StringBuffer扩容机制核心如下:若一次追加字符串长度超过当前容量,扩容规则为当前容量*2+2;如果追加长度超出初始容量且按当前容量*2+2扩容后仍不足,直接扩容至与新字符串长度相等;后续追加继续遵循当前容量*2+2规则。扩容为2倍+2的原因是为了减少内存分配次数和内存碎片,提高性能和效率。
为了验证上述规则,可设计实验案例,观察StringBuffer与StringBuilder的扩容表现。至此,详细解释了StringBuffer扩容机制及其规则,希望能对理解Java中字符串操作有所帮助。
2025-01-20 04:19234人浏览
2025-01-20 04:051893人浏览
2025-01-20 03:471138人浏览
2025-01-20 03:421686人浏览
2025-01-20 02:392775人浏览
2025-01-20 02:16137人浏览
據中新網援引日本TBS新聞網報道,當地時間7日凌晨,日本茨城縣南部和宮城縣近海連發兩起地震,包括福島縣等多地有明顯震感。據報道,當地時間7日凌晨1時43分許,茨城縣南部發生3.3級地震,震源深度50千

