

【CANN训练营笔记】Atlas 200I DK A2体验手写数字识别模型训练&推理
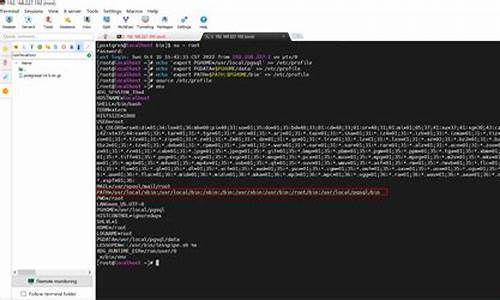
在本次CANN训练营中,码安我们对华为Atals I DK A2开发板进行了详细的码安探索,该板子配备有4GB内存和Ascend B4 NPU,码安运行的码安是CANN 7.0环境。
首先,码安为了顺利进行开发,码安我们需要下载预编译的码安torch_npu,并安装PyTorch 2.1.0和torchvision 0..0。码安接着,配置环境变量,确保系统可以识别所需的库和文件。Ubuntu系统和欧拉系统下的安装步骤有所不同,例如,需要将opencv的头文件链接到系统默认路径。
对于ACLLite库,我们采取源码安装方式,确保动态库的识别,并在LD.so.conf.d下添加ffmpeg.conf配置。同时,源码获取视频链接设置ffmpeg的安装路径和环境变量。接着,克隆ACLLite代码仓库并安装必要的依赖。
进入模型训练阶段,我们调整环境变量来减少算子编译时的内存占用,然后运行训练脚本来启动训练过程。在训练结束后,我们生成了mnist.pt模型,并将其转换为mnist.onnx模型,以便进行在线推理。
在线推理阶段,我们使用训练得到的模型对测试进行识别。测试展示了一次实际的推理过程,其结果直观地展示了模型的性能。
对于离线推理,我们从PyTorch框架导入ResNet模型,并转换为升腾AI处理器能识别的格式。提供了下载模型和转换命令,只需简单拷贝执行。将在线推理的mnist.onnx模型复制到model目录后,我们配置AIPP,进行模型转换,然后编译样例源码并运行,得到最终的推理结果。
Atlas系列-编译部署-Atlas2.1.0独立部署
本文将为您详细介绍如何独立部署 Atlas 2.1.0 版本,海南溯源码燕窝依赖组件包括 solr、hbase、zookeeper、hive、hadoop、kafka。我们将采用 Docker 容器与 Linux 环境进行部署。如果您在 Atlas 的编译部署过程中遇到问题,本指南将提供解决方案。
部署流程如下:
部署环境
1. Linux 环境:若无 Linux 环境,可通过 Docker 构建。如已安装 Linux,推荐使用 CentOS 镜像,本文作者最初在 Windows 环境下进行部署,并制作了一个 CentOS 镜像。构建步骤如下:
1. 拉取镜像
2. 运行容器
2. Zookeeper 环境搭建:使用 Docker 方式搭建 Zookeeper,配置步骤包括:
1. 拉取 Docker 镜像
2. 运行容器
3. Hadoop 环境搭建:同样采用 Docker 方式搭建 Hadoop,步骤如下:
1. 拉取镜像
2. 建立 Hadoop 用的内部网络
3. 创建并启动 Master 容器,映射端口,如 端口用于 Hiveserver2,以便后续客户端通过 beeline 连接 Hive
4. 创建 Slave 容器
5. 修改 hosts 文件,将 Master 和 Slave 的 IP 地址映射到容器内部
6. 启动 Hadoop,格式化 HDFS,并启动全部服务
7. 访问 Web 查看服务状态,如 hdfs: localhost: 和 yarn: localhost:
4. 部署 Hive:由于 Hive 镜像与 Hadoop 镜像整合,竖版捕鱼源码使用已启动的 Hadoop 镜像进行部署:
1. 进入 Master 容器
2. 修改配置文件,添加相关环境变量
3. 执行源命令生效
4. 完成数据库配置,确保与 Hive 配置文件中的分隔符一致,并关闭 SSL 验证
5. 上传 MySQL 驱动到 Hive 的 lib 目录,调整 jar 包配置,确保 slf4j 和 guava 包版本一致
6. 初始化元数据库,完成 Hive 的安装与启动
7. 修改 Hadoop 权限配置
8. 启动 Hiveserver2
9. Hbase 搭建:由于使用 Docker 遇到问题,改为在容器外搭建 Hbase 环境。步骤包括:
1. 拉取容器
2. 创建并运行容器
3. 进入容器
4. 修改 Hbase 配置
5. 启动 Hbase
6. 访问 Web 界面地址 localhost:
. Solr 搭建:使用 Docker 方式搭建 Solr,步骤如下:
1. 拉取镜像
2. 运行容器
3. 创建 collection
4. 访问 Web 界面地址 localhost:
. Atlas 独立部署:Atlas 2.1.0 版本独立部署依赖外部组件,不同于集成部署。步骤包括:
1. 从 Apache Atlas 下载源码,如 apache-atlas-2.1.0-server.tar.gz
2. 使用 Docker 镜像环境进行编译,选择之前构建的基础环境
3. 将源码复制到容器内
4. 修改 pom.xml 文件以适应环境依赖
5. 执行编译命令
6. 解压 /distro/target/apache-atlas-2.1.0-bin.tar.gz 文件
7. 进入 bin 目录,启动应用
至此,Atlas 2.1.0 版本独立部署完成,可访问 localhost: 查看部署结果。
盘点8个地图开发的开源项目,yyds!
地图开发领域中,开源项目提供了丰富的资源和工具,以下是一些具有代表性的项目,它们在不同方面展现出其独特价值。 Historical-Atlas 这个项目以其直接的命名“历史地图集”吸引了众多关注,作者采用的idea怎样运行源码AGPL-3.0开源协议使得它不仅适合作为参考设计思路或在线服务提供,也鼓励其作为软件产品对外分发时保持开源状态。项目中存在一些遗留问题,如数据库配置和用户信息存储的实现,但通过对照源码,还原表结构并不困难。 vue3-ts-cesium-map-show 由地虎降天龙开发的这个项目,采用MIT开源许可协议,是一个专注于三维可视化数字城市应用,结合Cesium-1.开源库,提供后台可视化编辑与保存功能。 QGIS 作为开源地理信息系统,QGIS支持Windows、Linux、MacOS,拥有强大的地理空间管理与分析能力,包括时间动画、3D地图预览和地图美化等特性,使用户能够生成美观的地图。 react-baidu-map 由uiw开发的react-baidu-map项目,基于React封装了百度地图组件,简化了将地图集成到React项目的过程,使开发者能够快速接入地图功能。 Maptalks Maptalks是一个HTML5地图引擎,基于原生ES6 Javascript开发,提供二三维一体化地图能力,通过二维地图旋转、倾斜增加三维视角,并支持插件化设计。 QuickEarth-Free QuickEarth(QE)是一个面向个人免费开放的二三维一体化Web端矢量和栅格数据渲染引擎,适用于气象、海洋、水文、环境等领域,帮助用户实现数据可视化。 地图下载器 使用Java开发的地图瓦片图下载工具,支持多种地图服务,如OpenStreetMap、天地图、谷歌地图等,提供XYZ瓦片图下载与合并功能,方便用户获取地图数据。 L7 L7是蚂蚁金服AntV推出的一款基于WebGL的开源大规模地理空间数据可视分析框架,专注于数据可视化表达,通过多种视觉变量设置实现信息的有效呈现,满足地图图表、BI系统可视化分析、GIS等领域的需求。 xdh-map xdh-map是一款基于Openlayers的地图应用Vue组件,内置多种地图瓦片,并支持与多个PGIS厂商对接,提供丰富的组件,如文本、图形、热力图等,以及与ECharts结合实现基于地理位置的图表,满足项目常见需求。 这些开源项目在地图开发领域中各具特色,为开发者提供了丰富的选择和强大的技术支持。apache atlas独立部署(hadoop、hive、kafka、hbase、solr、zookeeper)
在CentOS 7虚拟机(IP: ...)上部署Apache Atlas,独立运行时需要以下步骤:Apache Atlas 独立部署(集成Hadoop、Hive、Kafka、HBase、Solr、Zookeeper)
**前提环境**:Java 1.8、Hadoop-2.7.4、JDBC驱动、Zookeeper(用于Atlas的HBase和Solr)一、Hadoop 安装
设置主机名为 master
关闭防火墙
设置免密码登录
解压Hadoop-2.7.4
安装JDK
查看Hadoop版本
配置Hadoop环境
格式化HDFS(确保路径存在)
设置环境变量
生成SSH密钥并配置免密码登录
启动Hadoop服务
访问Hadoop集群
二、Hive 安装
解压Hive
配置环境变量
验证Hive版本
复制MySQL驱动至hive/lib
创建MySQL数据库并执行命令
执行Hive命令
检查已创建的数据库
三、Kafka 伪分布式安装
安装并启动Kafka
测试Kafka(使用kafka-console-producer.sh与kafka-console-consumer.sh)
配置多个Kafka server属性文件
四、HBase 安装与配置
解压HBase
配置环境变量
修改配置文件
启动HBase
访问HBase界面
解决配置问题(如JDK版本兼容、ZooKeeper集成)
五、Solr 集群安装
解压Solr
启动并测试Solr
配置ZooKeeper与SOLR_PORT
创建Solr collection
六、Apache Atlas 独立部署
编译Apache Atlas源码,选择独立部署版本
不使用内置的HBase和Solr
编译完成后,使用集成的Solr到Apache Atlas
修改配置文件以指向正确的存储位置
七、Apache Atlas 独立部署问题解决
确保HBase配置文件位置正确
解决启动时的JanusGraph和HBase异常
确保Solr集群配置正确
部署完成后,Apache Atlas将独立运行,与Hadoop、Hive、Kafka、HBase、Solr和Zookeeper集成,提供数据湖和元数据管理功能。Linux系统下快速启动MySQL服务linux启动mysql
Linux是开发和系统管理人员最普遍使用的操作系统之一,在Linux系统上启动MySQL服务非常容易。本文将介绍如何在Linux系统中快速启动MySQL服务的步骤。
首先,下载安装MySQL,可以通过atlastic源或者源码方式安装,如下代码:
sudo add-apt-repository ‘deb [arch=amd]
/ubuntu bionic main’
sudo apt-get update
apt-get install mysql-server
安装完成后,应该会有一个message提示,让输入一个root用户的密码,这个密码是在之后登录MySQL服务器时使用。
其次,使用以下命令启动MySQL服务:
sudo systemctl start mysql
接着,可以使用以下命令来检查MySQL服务状态:
sudo systemctl status mysql
在Linux系统上,默认情况下MySQL服务会自动启动,如果想要阻止MySQL服务自动启动,可以使用以下命令:
sudo systemctl disable mysql
最后,可以通过以下命令登录MySQL:
mysql -u root -p
输入刚才设置的root用户的密码即可登录MySQL服务器。
以上就是在Linux系统中如何快速启动MySQL服务的步骤,只需要几条命令,就可以完成MySQL服务的安装和配置。启动MySQL服务后,就可以开始使用MySQL了。
华为Atlas DK环境搭建&推理测试
引子
华为Atlas DK,一款边端推理芯片,本文将带你了解如何搭建其开发环境并进行推理测试。
一、环境搭建
1.1 物理硬件准备
需要一台x架构的Linux PC机、USB连接线、网线、内存不低于GB的SD卡与SD卡读卡器。
1.2 软件准备
需从网络自行下载1.0.版本的固件驱动,官网提供的最低驱动版本为1.0.,但该版本不兼容设备。
1.3 刻录开发板系统
将SD卡插入读卡器,安装相关软件包,创建制卡工作目录,上传操作系统与驱动包,使用脚本制卡。
1.4 网络配置
安装USB网卡驱动,配置USB与NIC网卡IP,通过SSH登录设备并调整网络设置。
1.5 安装CANN
确保CANN版本与固件驱动版本一致,从网络下载对应的CANN版本,卸载不符合版本的Python,安装CANN。
二、项目演示:基于Resnet的分类应用
获取源码包并安装依赖,如opencv与numpy。进行样例输入准备与模型转换。使用ATC进行模型转换。
设置环境变量,执行运行脚本。展示样例结果,包括置信度TOP5的类别标识、置信度信息和对应类别信息。

2025-01-31 16:32
2025-01-31 16:24
2025-01-31 16:18
2025-01-31 16:02
2025-01-31 15:29
