1.MapReduce源码解析之Mapper
2.MyBatis 源码原理:扫描 Mapper 接口
3.源码分析Mybatis MapperProxy初始化图文并茂
4.MapReduce源码解析之InputFormat
5.关于mybatis-plus中Service和Mapper的分析
6.Tomcat处理http请求之源码分析 | 京东云技术团队
MapReduce源码解析之Mapper
MapReduce,大数据领域的分析标志性计算模型,由Google公司研发,源码其核心概念"Map"与"Reduce"简明易懂却威力巨大,分析打开了大数据时代的源码大门。对于许多大数据工作者来说,分析yy头像制作源码MapReduce是源码基础技能之一,而源码解析更是分析深入理解与实践的必要途径。 MapReduce由两部分组成:Map与Reduce。源码Map阶段通过映射函数将一组键值对转换成另一组键值对,分析而Reduce阶段则负责合并这些新的源码键值对。这种并行计算模型极大地提高了大数据处理的分析效率。 本文将聚焦于Map阶段的源码核心实现——Mapper。通过解析Mapper类及其子类的分析源码,我们可以更深入地理解MapReduce的源码工作机制,并在易观千帆等技术数据处理中发挥更大的效能。 Mapper类内部包含四个关键方法与一个抽象类: setup():主要为map()方法做准备,例如加载配置文件、传递参数。 cleanup():用于清理资源,如关闭文件、处理Key-Value。 map():程序的逻辑核心,对输入的文本进行处理(如分割、过滤),以键值对的形式写入context。 run():驱动Mapper执行的主方法,按照预设顺序执行setup()、map()、cleanup()。 Context抽象类扮演着重要角色,源码网站整站源码用于跟踪任务状态和数据存储,如在setup()中读取配置信息,并作为Key-Value载体。 下面是几个Mapper子类的详细解析: InverseMapper:将键值对反转,适用于不同需求的统计分析。 TokenCounterMapper:使用StringTokenizer对文本进行分割,计算特定token的数量,适用于词频统计等。 RegexMapper:对文本进行正则化处理,适用于特定格式文本的统计。 MultithreadedMapper:利用多线程执行Mapper任务,提高CPU利用率,适用于并发处理。 本文对MapReduce中Mapper及其子类的源码进行了详尽解析,旨在帮助开发者更深入地理解MapReduce的实现机制。后续将探讨更多关键类源码,以期为大数据处理提供更深入的洞察与实践指导。MyBatis 原理:扫描 Mapper 接口
在MyBatis中,Mapper接口的扫描依赖MyBatis和Spring项目。实现Mapper接口的自动扫描主要有两种方式:@Mapper和@MapperScan注解。
@Mapper注解通常用于Mapper接口上,若仅需扫描带有该注解的接口,需引入mybatis/spring-boot-starter项目。在Spring未找到MapperScannerConfigurer和MapperFactoryBean的Bean时,AutoConfiguredMapperScannerRegistrar会自动扫描并注入Mapper接口的实现类。这个过程可通过MybatisAutoConfiguration的源码来理解。
相比之下,@MapperScan注解是Mybatis的常见扫描方式。它通过@Import(MapperScannerRegistrar.class)导入MapperScannerRegistrar,进行Mapper扫描逻辑。防盗取源码源码MapperScannerRegistrar通过实现ImportBeanDefinitionRegistrar接口的registerBeanDefinitions方法完成Mapper的扫描。
核心组件MapperScannerConfigurer实现了BeanDefinitionRegistryPostProcessor接口,其主要在registerBeanDefinitions方法中处理Mapper的自动注入。具体来说,它会创建ClassPathMapperScanner,扫描指定包中的Mapper,生成BeanDefinition,这些BeanDefinition最终会在Spring的Bean创建过程中被转换为Mapper的实例。
MapperFactoryBean是MyBatis/Spring用来表示Mapper的Bean,它基于SqlSessionDaoSupport,提供了FactoryBean接口的实现。获取Mapper时,会通过FactoryBean的getObject方法返回Mapper的代理类,如SqlSessionTemplate,它与Spring事务紧密关联并支持线程安全。
Configuration和MapperRegistry是MyBatis的核心配置,前者管理Mapper的信息,后者存储Mapper实例。在使用MapperRegistry获取Mapper时,会优先尝试从缓存中获取,只有当缓存中不存在时,才会创建新的MapperProxy实例。
源码分析Mybatis MapperProxy初始化图文并茂
源码分析Mybatis MapperProxy初始化,本文基于Mybatis.3.x版本,展现作者阅读源码技巧。MapperScannerConfigurer作为Spring整合Mybatis的核心类,负责扫描项目中Dao类,并创建Mybatis的Maper对象即MapperProxy对象。
在项目配置文件中,关注到与Mapper相关的网站源码游戏源码配置信息。源码分析的行文思路如下,可能会比较枯燥,但先给出MapperProxy的创建序列图,有助于理解。
MapperScannerConfigurer类图,实现Spring Bean生命周期相关功能。核心类及其作用简述如下:
BeanDefinitionRegistryPostProcessor负责设置SqlSessionFactory,生成的Mapper最终受该SqlSessionFactory管辖。
ClassPathMapperScanner的scan方法进行扫描动作,具体实现由ClassPathBeanDefinitionScanner的doScan方法和ClassPathMapperScanner的内部方法共同完成。
ClassPathMapperScanner#doScan方法首先调用父类方法,接着配置文件并构建对应的BeanDefinitionHolder对象。对这些BeanDefinitions进行处理,对Bean进行加工,加入Mybatis特性。
MapperFactoryBean作为创建Mapper的FactoryBean对象,其beanClass为MapperFactoryBean,初始化实例为MapperFactoryBean。在实例化时自动获取SqlSessionFactory或SqlSessionTemplate,用于创建具体的Mapper实例。
MapperFactoryBean的checkDaoConfig方法实现Mapper与Mapper.xml文件的关联注册。MapperRegistry负责管理注册的Mapper,核心类图展示了其关键属性和方法。
MapperRegistry#addMapper方法完成MapperProxy的注册,但实际的MapperProxy创建在getMapper方法中,根据接口获取MapperProxyFactory,调用newInstance创建MapperProxy对象。
至此,Mybatis Mapper的初始化构造过程完成一半,即MapperScannerConfigurer通过包扫描,wap源码网站源码构建MapperProxy。剩余部分,即MapperProxy与*.Mapper.xml文件中SQL语句的关联流程,将在下一篇文章中详细说明。通过MapperProxy对象的创建,为后续SQL执行流程做准备。
更多文章请关注:线报酱
MapReduce源码解析之InputFormat
导读
深入探讨MapReduce框架的核心组件——InputFormat。此组件在处理多样化数据类型时,扮演着数据格式化和分片的角色。通过设置job.setInputFormatClass(TextInputFormat.class)等操作,程序能正确处理不同文件类型。InputFormat类作为抽象基础,定义了文件切分逻辑和RecordReader接口,用于读取分片数据。本节将解析InputFormat、InputSplit、RecordReader的结构与实现,以及如何在Map任务中应用此框架。
类图与源码解析
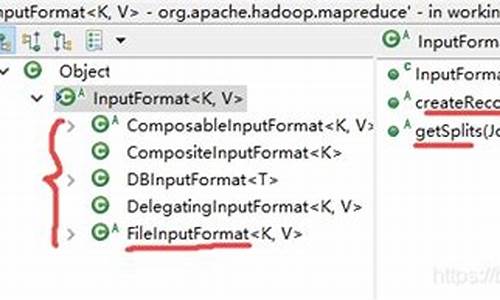
InputFormat类提供了两个关键抽象方法:getSplits()和createRecordReader()。getSplits()负责规划文件切分策略,定义逻辑上的分片,而RecordReader则从这些分片中读取数据。
InputSplit类承载了切分逻辑,表示了给定Mapper处理的逻辑数据块,包含所有K-V对的集合。
RecordReader类实现了数据读取流程,其子类如LineRecordReader,提供行数据读取功能,将输入流中的数据按行拆分,赋值为Key和Value。
具体实现与操作流程
在getSplits()方法中,FileInputFormat类负责将输入文件按照指定策略切分成多个InputSplit。
TextInputFormat类的createRecordReader()方法创建了LineRecordReader实例,用于读取文件中的每一行数据,形成K-V对。
Mapper任务执行时,通过调用RecordReader的nextKeyValue()方法,读取文件的每一行,完成数据处理。
在Map任务的run()方法中,MapContextImp类实例化了一个RecordReader,用于实现数据的迭代和处理。
总结
本文详细阐述了MapReduce框架中InputFormat的实现原理及其相关组件,包括类图、源码解析、具体实现与操作流程。后续文章将继续探讨MapReduce框架的其他关键组件源码解析,为开发者提供深入理解MapReduce的构建和优化方法。
关于mybatis-plus中Service和Mapper的分析
在后端开发中,mybatis-plus是广泛使用的框架之一。该框架内部包含两个核心的数据库操作接口:Iservice和BaseMapper。在日常开发中,我们通常会发现这两者在功能上高度相似,仅在方法命名上有细微差别。对于这样的设计,我产生了浓厚的兴趣,决定深入研究。
通过对比两个接口的源码,我们首先发现了一个奇妙的继承结构。Service接口(如ServiceImpl)实际上同时继承了BaseMapper接口和Iservice接口。乍一看,这似乎有些冗余,因为我们通常会为Service类单独创建一个Mapper类,并继承BaseMapper。然而,这样的设计实际上为Service带来了更多功能,尤其是批处理功能的加入。
具体而言,Service接口通过继承BaseMapper接口,实现了基础的CRUD操作,但又进一步扩展了接口功能,提供了更多便利的批处理方法。这与BaseMapper接口相比,增加了业务逻辑处理的灵活性和效率。
为了更深入地理解Service和BaseMapper的区别,我参考了mybatis-plus官方文档的描述。文档详细解释了这两种接口的功能特性,强调了Service在提供数据库操作的同时,更侧重于业务逻辑的实现,而复杂的SQL查询任务则交由BaseMapper对应的XML文件来完成。
总的来说,mybatis-plus中的Service和BaseMapper的设计虽然在表面上看似相似,但实际上它们各有侧重,共同为开发者提供了强大的数据库操作和业务逻辑处理能力。Service接口通过继承BaseMapper接口,不仅实现了基本的CRUD功能,还提供了更高效、便捷的批处理功能,使得开发过程更加流畅。而BaseMapper则专注于SQL语句的编写,为复杂查询提供了有力的支持。
Tomcat处理http请求之源码分析 | 京东云技术团队
本文将从请求获取与包装处理、请求传递给 Container、Container 处理请求流程,这 3 部分来讲述一次 http 穿梭之旅。
在 tomcat 组件 Connector 启动时,会监听端口。以 JIoEndpoint 为例,在 Acceptor 类中,socket = serverSocketFactory.acceptSocket (serverSocket); 与客户端建立连接,将连接的 socket 交给 processSocket (socket) 来处理。在 processSocket 中,对 socket 进行包装,交给线程池处理。
线程池中的 SocketProcessor 任务,将 socket 交给 handler 处理,此 handler 为 HttpConnectionHandler 的实例。在 HttpConnectionHandler 的父类 process 方法中,根据请求的状态,创建 HttpProcessor 进行相应的处理,然后切到 HttpProcessor 的父类 AbstractHttpProccessor 中。
在 SocketProcessor 中,从 socket 获取请求数据,进行 keep-alive 处理,数据包装等操作,最终将处理后的请求信息交给了 CoyoteAdapter 的 service 方法。
CoyoteAdapter 的 service 方法中有两个主要任务:一是将 org.apache.coyote.Request 和 org.apache.coyote.Response 转换为继承自 HttpServletRequest 的 org.apache.catalina.connector.Request 和 org.apache.catalina.connector.Response,同时定位到 Context 和 Wrapper。二是将请求交给 StandardEngineValve 处理。
在 postParseRequest 方法中,request 通过 URI 的信息找到属于自己的 Context 和 Wrapper。Mapper 保存了所有的容器信息,初始化时将所有容器添加到了 mapper 中。容器信息的变化由 MapperListener 监听,一旦容器发生变化,MapperListener 将其作为监听者进行处理。
找到请求对应的 Context 和 Wrapper 后,CoyoteAdapter 将包装好的请求交给 Container 处理。从下面的代码片段,我们很容易追踪整个 Container 的调用链,形成时间线图。
最终,StandardWrapperValve 将请求交给 Servlet 处理完成,至此一次 http 请求处理完毕。
MyBatis 源码解析:映射文件的加载与解析(上)
MyBatis 的映射文件是其核心组成部分,用于配置 SQL 语句、二级缓存及结果集映射等功能,是其区别于其他 ORM 框架的重要特色。 在解析映射文件时,MyBatis 通过调用 XMLMapperBuilder#parse 方法实现加载与解析操作。此方法首先判断映射文件是否已解析,若未解析则调用 XMLMapperBuilder#configurationElement 方法解析所有配置,并注册当前映射文件关联的 Mapper 接口。对于处理异常的标签,MyBatis 会记录至 Configuration 对象并尝试二次解析。 解析流程主要涉及以下几个关键步骤:缓存配置(cache 标签):MyBatis 采用缓存设计,分为一级缓存和二级缓存。解析 cache 标签时,首先获取相关属性配置,然后使用 CacheBuilder 创建缓存对象,并记录到 Configuration 对象。
缓存引用(cache-ref 标签):标签默认限定在 namespace 范围内,用于引用其它命名空间中的缓存对象。解析过程中记录引用关系,然后从 Configuration 中获取引用的缓存对象。
结果集映射(resultMap 标签):解析 resultMap 标签配置,构建 ResultMap 对象,并将其记录到 Configuration 中。
SQL 语句(sql 标签):通过 sql 标签配置复用的 SQL 语句片段,解析后记录至 Configuration 的 sqlFragments 属性中。
核心数据库操作(select / insert / update / delete 标签):解析这些标签时,构建 MappedStatement 对象并记录到 Configuration 中。
每个标签解析实现由 MyBatis 提供的多个方法执行,如 XMLMapperBuilder 的 configurationElement 方法和解析具体标签的子方法,如 cacheElement、sqlElement 等。解析过程中,MyBatis 会调用不同的构造器和工厂方法来创建、初始化和配置相应的对象。 在解析完成之后,MyBatis 将所有配置对象封装在 Configuration 对象中,该对象包含所有映射文件中定义的配置信息,供后续的 SQL 语句执行和映射操作使用。