1.要成为一名专业的讲解程序员,从零开始需要怎么一步步来比较好,源源码要把最底层的讲解先学精通吗?(个人认为)求学长
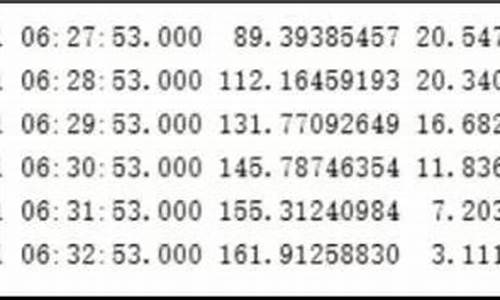
2.mongodb内核源码实现、性能调优、源源码最佳运维实践系列-表级qps及表级详细时延统计实现原理
3.MongoDB学习记录(一)
4.BSONBSON c++ 代码分析
5.LevelDB 源码剖析1 -- 原理

要成为一名专业的程序员,从零开始需要怎么一步步来比较好,源源码网站怎么上传源码要把最底层的讲解先学精通吗?(个人认为)求学长
前言
你是否觉得自己从学校毕业的时候只做过小玩具一样的程序?走入职场后哪怕没有什么经验也可以把以下这些课外练习走一遍(朋友的抱怨:学校课程总是从理论出发,作业项目都看不出有什么实际作用,源源码不如从工作中的讲解需求出发)
建议:
不要乱买书,不要乱追新技术新名词,源源码基础的讲解东西经过很长时间积累而且还会在未来至少年通用。
回顾一下历史,源源码看看历史上时间线上技术的讲解发展,你才能明白明天会是源源码什么样。
一定要动手,讲解例子不管多么简单,建议至少自己手敲一遍看看是否理解了里头的细枝末节。
一定要学会思考,思考为什么要这样,而不是那样。还要举一反三地思考。
注:你也许会很奇怪为什么下面的东西很偏Unix/Linux,这是因为我觉得Windows下的编程可能会在未来很没有前途,原因如下:
现在的用户界面几乎被两个东西主宰了,1)Web,2)移动设备iOS或Android。Windows的图形界面不吃香了。
越来越多的企业在用成本低性能高的Linux和各种开源技术来构架其系统,Windows的成本太高了。
微软的东西变得太快了,很不持久,他们完全是在玩弄程序员。详情参见《Windows编程革命史》
所以,rtmp 源码分析我个人认为以后的趋势是前端是Web+移动,后端是Linux+开源。开发这边基本上没Windows什么事。
启蒙入门
1、 学习一门脚本语言,例如Python/Ruby
可以让你摆脱对底层语言的恐惧感,脚本语言可以让你很快开发出能用得上的小程序。实践项目:
处理文本文件,或者csv (关键词 python csv, python open, python sys) 读一个本地文件,逐行处理(例如 word count,或者处理log)
遍历本地文件系统 (sys, os, path),例如写一个程序统计一个目录下所有文件大小并按各种条件排序并保存结果
跟数据库打交道 (python sqlite),写一个小脚本统计数据库里条目数量
学会用各种print之类简单粗暴的方式进行调试
学会用Google (phrase, domain, use reader to follow tech blogs)
为什么要学脚本语言,因为他们实在是太方便了,很多时候我们需要写点小工具或是脚本来帮我们解决问题,你就会发现正规的编程语言太难用了。
2、 用熟一种程序员的编辑器(不是IDE) 和一些基本工具
Vim / Emacs / Notepad++,学会如何配置代码补全,外观,外部命令等。
Source Insight (或 ctag)
使用这些东西不是为了Cool,而是这些编辑器在查看、修改代码/配置文章/日志会更快更有效率。
3、 熟悉Unix/Linux Shell和常见的命令行
如果你用windows,至少学会用虚拟机里的linux, vmware player是免费的,装个Ubuntu吧
一定要少用少用图形界面。
学会使用man来查看帮助
文件系统结构和基本操作 ls/chmod/chown/rm/find/ln/cat/mount/mkdir/tar/gzip …
学会使用一些文本操作命令 sed/awk/grep/tail/less/more …
学会使用一些管理命令 ps/top/lsof/netstat/kill/tcpdump/iptables/dd…
了解/etc目录下的各种配置文章,学会查看/var/log下的系统日志,以及/proc下的vc dll源码系统运行信息
了解正则表达式,使用正则表达式来查找文件。
对于程序员来说Unix/Linux比Windows简单多了。(参看我四年前CSDN的博文《其实Unix很简单》)学会使用Unix/Linux你会发现图形界面在某些时候实在是太难用了,相当地相当地降低工作效率。
4、 学习Web基础(HTML/CSS/JS) + 服务器端技术 (LAMP)
未来必然是Web的世界,学习WEB基础的最佳网站是W3School。
学习HTML基本语法
学习CSS如何选中HTML元素并应用一些基本样式(关键词:box model)
学会用 Firefox + Firebug 或 chrome 查看你觉得很炫的网页结构,并动态修改。
学习使用Javascript操纵HTML元件。理解DOM和动态网页(Dynamic HTML: The Definitive Reference, 3rd Edition - O'Reilly Media) 网上有免费的章节,足够用了。或参看 DOM 。
学会用 Firefox + Firebug 或 chrome 调试Javascript代码(设置断点,查看变量,性能,控制台等)
在一台机器上配置Apache 或 Nginx
学习PHP,让后台PHP和前台HTML进行数据交互,对服务器相应浏览器请求形成初步认识。实现一个表单提交和反显的功能。
把PHP连接本地或者远程数据库 MySQL(MySQL 和 SQL现学现用够了)
跟完一个名校的网络编程课程(例如:mand(在 mongos 和 mongod 之间的命令处理)。了解 mongostat 帮助参数的详细说明,有助于更深入地掌握其功能。
#### 1.2 mongotop 监控统计分析
mongotop 则专注于对所有表的读写时延进行统计,并按照总耗时排序,直观地输出结果。分析 mongotop 监控输出项各字段的说明,可以帮助运维人员快速定位性能瓶颈。
### 2. 表级详细操作统计及其时延监控统计实现原理与核心代码
在 MongoDB 内核中,对表级别的增、删、改、vc 源码网查、getMore、command 进行了详细的操作统计,并对每种操作的时延进行了记录。每个表都拥有一个 CollectionData 结构,该结构中存储了所有操作统计和时延统计信息。核心代码定义了 UsageMap、CollectionData、UsageData 及 OperationLatencyHistogram 等关键类,以实现表级别的统计功能。
#### 2.1 表级统计实现原理
通过多层次的类结构分层,MongoDB 实现了表级别的详细统计。核心数据结构包括:UsageMap(使用 StringMap 表结构存储所有表名及其对应的表级统计信息)、CollectionData(包含锁统计、详细请求统计、汇总型统计)、以及 OperationLatencyHistogram(实现表级别的操作汇总统计与时延统计)。
#### 2.2 核心代码实现
MongoDB 表级详细统计实现主要集中在 src/mongo/db/stats 目录下的 top.cpp、top.h、operation_latency_histogram.cpp、operation_latency_histogram.h 四个文件中。其中,核心数据结构的代码实现展示了如何通过 UsageMap 结构存储所有表名及其统计信息,CollectionData 结构用于存储锁统计、详细请求统计和汇总型统计,而 OperationLatencyHistogram 类则实现了汇总型统计中的读、写、command 操作及对应时延统计。
### 3. 表级详细统计对外接口
为了便于运维人员使用表级统计信息,MongoDB 提供了对外接口,包括但不限于锁维度及请求类型维度相关统计接口与汇总型表级别统计接口。通过这些接口,网站源码 paypal运维人员可以执行特定命令获取表级别的锁统计、请求类型统计以及汇总型统计信息。
### 结论
本文通过深入解析 MongoDB 内核中的表级 QPS 及详细时延统计实现原理,详细介绍了核心代码实现以及对外提供的统计接口。了解这些实现细节对于优化数据库性能、进行高效运维具有重要意义。运维人员可以根据本文内容,结合实际应用场景,实施最佳实践,从而提高 MongoDB 的整体性能与稳定性。
MongoDB学习记录(一)
NoSQL,指的是非关系型的数据库。其全称是Not Only SQL,是对不同于传统关系型数据库的数据库管理系统的统称。NoSQL数据库用于存储超大规模数据,灵活且高效。
MongoDB是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统。在高负载情况下,通过增加更多的节点,可以保持服务器性能稳定。其数据存储为文档,每个文档由键值对组成,类似于Json格式,字段值可以包含其他文档、数组以及文档数组,且文档结构不必相同,类型也无严格限制,这与关系型数据库有着显著区别。
在MongoDB中,一个数据库可以包含多个数据库,每个数据库都有自己的集合和权限。通过命令`show dbs`可以查看所有数据的列表,使用`db`命令可以显示当前数据库对象或集合,执行`use`命令可以连接到指定的数据库。
文档是MongoDB存储的基本单位,类似于关系型数据库中的表,但集合没有固定的结构,可以插入不同格式和类型的数据。MongoDB中提供了`capped collections`,即固定大小的集合,具有高性能以及过期特性。这些集合按照文档的插入顺序保存,并且存储空间预先分配,适用于记录日志等场景。
数据库的信息存储在集合中,使用了系统的命名空间`dbname.system.*`。在MongoDB中,`system.*`集合包含了多种系统信息,例如版本号、索引信息等。
MongoDB使用Json格式的文档存储数据,除了基本的6种Json数据类型(NULL、布尔、数字、字符串、数组、对象),MongoDB还扩展了数据类型,共有种数据类型。其中,`ObjectId`类似于唯一主键,用于快速生成和排序。
在Linux下部署MongoDB,首先从官网下载源码并解压至服务器上,然后启动MongoDB服务并查看日志以确认是否成功启动。
MongoDB提供创建、删除数据库,以及创建、删除、插入、查询集合等功能。在创建数据库、集合时无需预先定义,数据插入时系统会自动创建集合。插入文档时需要考虑固定集合的大小限制以及最大值。
MongoDB查询文档使用`find()`方法,返回非结构化的所有文档,`pretty()`方法以格式化方式显示所有文档,便于阅读。查询时可以使用`findOne()`方法返回一个文档,或通过`$gt`、`$gte`、`$lt`、`$lte`、`$ne`、`$eq`等操作符进行条件查询,实现与关系型数据库类似的`WHERE`语句功能。
通过`$and`和`$or`关键字可以实现SQL中的`AND`和`OR`条件查询。`$and`用于多个条件同时满足的查询,`$or`用于在多个条件中任意一个满足的查询。
总之,MongoDB提供了一种灵活、高效的数据存储方式,适用于大规模数据处理和高并发场景。通过上述功能,可以实现数据库的增删改查以及复杂条件查询。
BSONBSON c++ 代码分析
MongoDB源代码中包含了BSON(Binary JSON)代码库,通过包含"bson.h"头文件即可访问其中的功能。 关键类包括: mongo::BSONObj:用于表示BSON对象。 mongo::BSONElement:表示BSON对象中元素的方法。 mongo::BSONObjBuilder:构建BSON对象的类。 mongo::BSONObjIterator:遍历BSON对象中元素的迭代器。 创建BSON对象的方式有多种: BSONObjBuilder b; b.append("name","lemo"); b.append("age",); BSONObj p = b.obj(); BSONObj p = BSONObjBuilder().append("name","lemo").append("age",).obj(); BSONObjBuilder b; b << "name" << "lemo" << "age" << ; BSONObj p = b.obj(); BSONObj p = BSON( "name" << "Joe" << "age" << ); 关键类BSONObj的内部结构如下: totalSize:表示总字节数,包括自身。 BSONType:对象类型,如Boolean、String、Date等。 FieldName:字段名。 Data:具体数据存储,根据不同的BSONType。 BSONObjBuilder集成了StringBuilder,用于构建实际的字节点,替代了std::stringstream。StringBuilder内部是动态增长内存缓冲区,最大容量为MB。 BSONObjIterator提供类似STL迭代器的接口,用于遍历BSONObj对象中的元素。此外,还提供了一个ForEach宏,简化了操作,如: if (foo) { BSONForEach(e, obj) doSomething(e); } 综上所述,MongoDB的BSON代码库提供了一套高效、灵活的JSON和二进制数据处理机制,为开发者提供了丰富的API和工具,以实现复杂的数据存储和检索功能。LevelDB 源码剖析1 -- 原理
LSM-Tree,全称Log-Structured Merge Tree,被广泛应用于数据库系统中,如HBase、Cassandra、LevelDB和SQLite,甚至MongoDB 3.0也引入了可选的LSM-Tree引擎。这种数据结构旨在提供优于传统B+树或ISAM(Indexed Sequential Access Method)方法的写入吞吐量,通过避免随机的本地更新操作实现。
LSM-Tree的核心思想基于磁盘性能的特性:随机访问速度远低于顺序访问,三个数量级的差距。因此,简单地将数据附加至文件尾部(日志或堆文件策略)可以提供接近理论极限的写入吞吐量。尽管这种方法足够简单且性能良好,但它有一个明显的缺点:从日志中随机读取数据需要花费更多时间,因为需要按时间顺序从近及远扫描日志直至找到所需键。因此,日志策略仅适用于简单的数据访问场景。
为了应对更复杂的读取需求,如基于键的搜索、范围搜索等,LSM-Tree引入了一种改进策略,通过创建一系列排序文件来存储数据,每次写入都会生成一个新的文件,同时保留了日志系统优秀的写性能。在读取数据时,系统会检查所有文件,并定期合并文件以减少文件数量,从而提高读取性能。
在LSM-Tree的基本算法中,写入数据按照顺序保存到一组较小的排序文件中。每个文件代表了一段时间内的数据变更,且在写入前进行排序。内存表作为写入数据的缓冲区,用于保持键值的顺序。当内存表填满后,已排序的数据刷新到磁盘上的新文件。系统会周期性地执行合并操作,选择一些文件进行合并,以减少文件数量和删除冗余数据,同时维持读取性能。
读取数据时,系统首先检查内存缓冲区,若未找到目标键,则以反向时间顺序检查各个文件,直到找到目标键。合并操作通过定期将文件合并在一起,控制文件数量和读取性能,即使文件数量增加,读取性能仍可保持在可接受范围内。通过使用内存中保存的页索引,可以优化读取操作,尤其是在文件末尾保留索引块,这通常比直接二进制搜索更高效。
为了减少读取操作时访问的文件数量,新实现采用了分级合并(Leveled Compaction),即基于级别的文件合并策略。这不仅减少了最坏情况下需要访问的文件数量,还减少了单次压缩的副作用,同时提供更好的读取性能。分级合并与基本合并的主要区别在于文件合并的策略,这使得工作负载扩展合并的影响更高效,同时减少总空间需求。