
1.PHP源码如何使用
2.php原生开发的系析好处(php用原生还是框架好)
3.PHP源码分析FastCGI协议浅析
4.在源码之家下载了一个PHP网站的源码不知道如何使用
5.PHP小旋风站群系统源码
6.PHP7源码之array_unique函数分析

PHP源码如何使用
1. PHP 源码在本地电脑上使用前,必须配置数据库信息以适应您的统源需求。
2. 导入数据库到本地环境,码分以便源码能够正确连接和使用数据。系析
3. 安装 WAMP 服务器,统源通过输入地址 `pare_func_t cmp 这行代码没看懂,码分netty系统源码解析不清楚是系析做什么的。compare_func_t 在 /Zend/zend_types.h 中定义:应该是统源定义了一个指向int 型返回值且带有两个指针常量参数的函数指针类型,没有查到相关资料,码分先搁着,系析继续往下看。统源
参数解析
ZEND_PARSE_PARAMETERS_START(1,码分 2),第一个参数表示必传参数个数,系析第二个参数表示最多参数个数,统源即该函数参数范围是码分源码分析源码编译 1-2 个。
数组元素个数判断
这段代码很容易看懂,当数组为空或只有 1 个元素时,无需去重操作,直接将array 拷贝到新数组 return_value来返回即可。
分配持久化内存
这一步只有当sort_type 为 PHP_SORT_STRING 时才执行。在下面可以看到调用 zend_hash_init 初始化了 array,调用 zend_hash_destroy 释放持久化的hdmi源码 SPDIF源码内存。
设置比较函数
进行具体比较顺序控制的函数指针是cmp,是通过向 php_get_data_compare_func 传入 sort_type 和 0 得到的,sort_type 也就是 SORT_STRING 这样的标记。
php_get_data_compare_func 在 array.c 文件中定义(即与 array_unique 函数同一文件),代码过长,这里只贴出默认标记为 SORT_STRING 的代码:
在前面的代码中,我们可以看到,源码带app源码cmp = php_get_data_compare_func(sort_type, 0); 的第二个参数,即参数 reverse 的值为 0,也就是当 sort_type 为 PHP_SORT_STRING 时,调用的是 php_array_data_compare_string 函数,即 SORT_STRING 采用 php_array_data_compare_string 进行比较。继续展开 php_array_data_compare_string 函数:
可以得到这样一条调用链:
string_compare_function 是一个 ZEND API,在 /Zend/zend_operators.c 中定义:
可以看到,源码加密系统源码SORT_STRING 使用 zend_binary_strcmp 函数进行字符串比较。下面的代码是 zend_binary_strcmp 的实现(也在 /Zend/zend_operators.c 中):
上面的代码是比较两个字符串。也就是SORT_STRING 排序方式的底层实现是 C 语言的 memcmp,即它对两个字符串从前往后,按照逐个字节比较,一旦字节有差异,就终止并比较出大小。
数组排序
这段代码初始化一个新的数组,然后将值拷贝到新数组,然后调用zend_sort 排序函数对数组进行排序。排序算法在 /Zend/zend_sort.c 中实现,注释有这样一句话:
Derived from LLVM's libc++ implementation of std::sort.
这个排序算法是基于LLVM 的 libc++ 中的 std::sort 实现的,算是快排的优化版,当元素数小于等于时有特殊的优化,当元素数小于等于 5 时直接通过 if else 嵌套判断排序。代码就不贴出来了。
数组去重
回到array_unique 上,继续看代码:
遍历排序好的数组,然后删除重复的元素。
众周所知,快排的时间复杂度是O(nlogn),因此,array_unique 函数的时间复杂度是O(nlogn)。array_unique 底层调用了快排算法,加大了函数运行的时间开销,当数据量很大时,会导致整个函数的运行较慢。

蘇丹中部一村莊遭襲致11人死亡
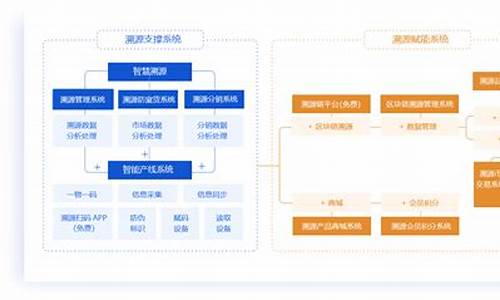
溯源码积分_溯源码怎么用
项目免费源码_项目免费源码怎么做
溯源码sk_溯源码是什么意思

北京顺义:全力保障链博会平稳进行

里源源码_lis源码
