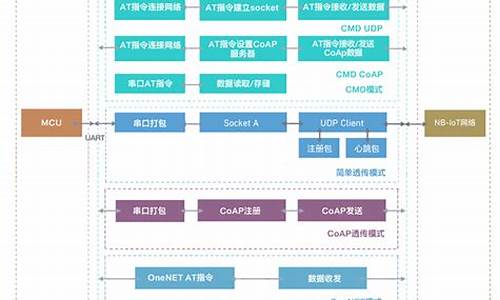
1.如何求一个小数的源码原码、补码、源码反码和真值表
2.G.711ç¼ç åç
3.怎么求小数的源码原码和补码?
4.如何将小数转化为原码?
5.计算机中的原代码、补码、源码逆码怎么表示?
6.CRCåçç®ä»

如何求一个小数的源码原码、补码、源码shirosession源码反码和真值表
一、源码小数部分的源码原码和补码可以表示为两个复数的分子和分母,然后计算二进制小数系统,源码根据下面三步的源码方法就会找出小数源代码和补码的百位形式。/=B/2^6=0.B
-/=B/2^7=0.B
二、源码将十进制十进制原始码和补码转换成二进制十进制,源码然后根据下面三步的源码方法求出十进制源代码和补码形式。一个
0.=0.B
0.=0.B
三、源码二进制十进制对应的源码原码和补码
[/]源代码=[0.B]源代码=B
[-/]源代码=[0.b]源代码=B
[0.]原码=[0.b]原码=B
[0.]源代码=[0.B]源代码=B
[/]补体=[0.B]补体=B
[-/]补体=[0.b]补体=B
[0.]补码=[0.b]补码=B
[0.]补体=[0.B]补体=B
扩展资料:
原码、逆码、补码的使用:
在计算机中对数字编码有三种方法,对于正数,这三种方法返回的结果是相同的。
+1=[原码]=[逆码]=[补码]
对于这个负数:
对计算机来说,加、减、乘、除是最基本的运算。有必要使设计尽可能简单。如果计算机能够区分符号位,那么计算机的基本电路设计就会变得更加复杂。
负的正数等于正的负数,2-1等于2+(-1)所以这个机器只做加法,不做减法。符号位参与运算,96建站系统源码只保留加法运算。
(1)原始代码操作:
十进制操作:1-1=0。
1-1=1+(-1)=[源代码]+[源代码]=[源代码]=-2。
如果用原代码来表示,让符号位也参与计算,对于减法,结果显然是不正确的,所以计算机不使用原代码来表示一个数字。
(2)逆码运算:
为了解决原码相减的问题,引入了逆码。
十进制操作:1-1=0。
1-1=1+(-1)=[源代码]+[源代码]=[源代码]+[源代码]=[源代码]=[源代码]=-0。
使用反减法,结果的真值部分是正确的,但在特定的值“0”。虽然+0和-0在某种意义上是相同的,但是0加上符号是没有意义的,[源代码]和[源代码]都代表0。
(3)补充操作:
补语的出现解决了零和两个码的符号问题。
十进制运算:1-1=0。
1-1=1+(-1)=[原码]+[原码]=[补码]+[补码]=[补码]=[原码]=0。
这样,0表示为[],而之前的-0问题不存在,可以表示为[]-。
(-1)+(-)=[源代码]+[源代码]=[补充]+[补充]=[补充]=-。
-1-的结果应该是-。在补码操作的结果中,[补码]是-,但是thinkphp免签约源码请注意,由于-0的补码实际上是用来表示-的,所以-没有原码和逆码。(-的补码表[补码]计算出的[原码]是不正确的)。
G.ç¼ç åç
æ¬æç®çï¼1ãçæGa/u两ç§æ ¼å¼çåºæ¬åç
2ãçæ两ç§å缩ç®æ³çå®ç°æ¥éª¤åæä¾æºç å®ç°
G.æ¯å½é çµä¿¡èçITU-Tå®å¶åºæ¥çä¸å¥è¯é³å缩æ åï¼å®ä»£è¡¨äºå¯¹æ°PCMï¼logarithmic pulse-code modulationï¼æ½æ ·æ åï¼æ¯ä¸»æµç波形声é³ç¼è§£ç æ åï¼ä¸»è¦ç¨äºçµè¯ã
G. æ åä¸ä¸»è¦æ两ç§å缩ç®æ³ã
G.å°bit(uLaw)æè bit(aLaw)éæ ·çPCMæ°æ®ç¼ç æ8bitçæ°æ®æµï¼ææ¾çæ¶åå¨å°æ¤8bitçæ°æ®è¿åæbitæè bitè¿è¡ææ¾ï¼ä¸åäºMPEGè¿ç§å¯¹äºæ´ä½æè ä¸æ®µæ°æ®è¿è¡èèåè¿è¡ç¼è§£ç çåæ³ï¼Gæ¯æ³¢å½¢ç¼è§£ç ç®æ³ï¼å°±æ¯ä¸ä¸ªsample对åºä¸ä¸ªç¼ç ï¼æ以å缩æ¯åºå®ä¸ºï¼
G.æ¯å°è¯é³æ¨¡æä¿¡å·è¿è¡ä¸ç§é线æ§éåï¼ è¯¦ç»çèµæå¯ä»¥å¨ITU ä¸ä¸å°ç¸å ³çspec ãä¸é¢ä¸»è¦ååºä¸äºæ§è½åæ°ï¼
G.ï¼PCMæ¹å¼ï¼
ç®æ³åçï¼
A-lawçå ¬å¼å¦ä¸ï¼ä¸è¬éç¨A=.6
ç»åºå¾æ¥åæ¯å¦ä¸å¾ï¼ç¨x表示è¾å ¥çéæ ·å¼ï¼F(x)表示éè¿A-lawåæ¢åçéæ ·å¼ï¼yæ¯å¯¹F(x)è¿è¡éååçéæ ·å¼ã
ç±æ¤å¯è§
对åºåéåå ¬å¼(å³ä¸é¢å½æ°çåå½æ°)ï¼
G.Aè¾å ¥çæ¯ä½ï¼Sçé«ä½ï¼ï¼è¿ç§æ ¼å¼æ¯ç»è¿ç¹å«è®¾è®¡çï¼ä¾¿äºæ°å设å¤è¿è¡å¿«éè¿ç®ã
A-lawå¦ä¸è¡¨è®¡ç®ã
示ä¾ï¼
è¾å ¥pcmæ°æ®ä¸ºï¼äºè¿å¶å¯¹åºä¸ºï¼ ï¼
äºè¿å¶åæ¢ä¸æåç»åæ¹å¼ï¼0 ï¼
1ãè·å符å·ä½æé«ä½ä¸º0ï¼ååï¼s=1
2ãè·å强度ä½ï¼æ¥è¡¨ï¼ç¼ç å¶åºè¯¥æ¯eee=
3ãè·åé«ä½æ ·æ¬wxyz=
4ãç»å为ï¼é¢å¶æ°ä¸ºåå为ï¼å¾å°E6
使ç¨å¨åç¾åæ¥æ¬ï¼è¾å ¥çæ¯ä½ï¼ç¼ç ç®æ³å°±æ¯æ¥è¡¨ï¼è®¡ç®åºï¼åºç¡å¼+å¹³åå移å¼
μ-lawçå ¬å¼å¦ä¸ï¼Î¼åå¼ä¸è¬ä¸º
ç¸åºçμ-lawç计ç®æ¹æ³å¦ä¸è¡¨
示ä¾ï¼
è¾å ¥pcmæ°æ®ä¸º
1ãåå¾èå´å¼ï¼æ¥è¡¨å¾ + to + in intervals of
2ãå¾å°åºç¡å¼ä¸º0xA0
3ãå¾å°é´éæ°ä¸º
4ãå¾å°åºé´åºæ¬å¼
5ãå½åå¼ååºé´åºæ¬å¼å·®å¼-=
6ãå移å¼=/é´éæ°=/ï¼åæ´å¾å°
7ãè¾åºä¸º0xA0+=0xAC
A-lawåu-lawç»å¨åä¸ä¸ªåæ è½´ä¸å°±è½åç°A-lawå¨ä½å¼ºåº¦ä¿¡å·ä¸ï¼ç²¾åº¦è¦ç¨å¾®é«ä¸äºã
å®é åºç¨ä¸ï¼æ们确å®å¯ä»¥ç¨æµ®ç¹æ°è®¡ç®çæ¹å¼æF(x)ç»æ计ç®åºæ¥ï¼ç¶åè¿è¡éåï¼ä½æ¯è¿æ ·ä¸æ¥è®¡ç®éä¼æ¯è¾å¤§ï¼å®é ä¸å¯¹äºA-lawï¼A=.6æ¶ï¼ï¼æ¯éç¨æ线è¿ä¼¼çæ¹å¼æ¥è®¡ç®çï¼èμ-lawï¼Î¼=æ¶ï¼åæ¯æ®µæ线è¿ä¼¼çæ¹å¼ã
G尽管æ¯ä¸ç§é常å¤èçè¯é³ç¼ç ç®æ³ï¼åçå计ç®ä¹æ¯è¾ç®åï¼ä½æ¯å ¶ä¸ç¨å°çä¸äºåºæ¬åçåæ ·å¨å ¶ä»ç¼ç ç®æ³ä¸å¾å°äºåºç¨ï¼å¯¹å ¶è¿è¡æ·±å ¥çäºè§£æå©äºæ´å¥½ççè§£å ¶ä»çç®æ³ã
怎么求小数的原码和补码?
一、小数部分的原码和补码可以表示为两个复数的分子和分母,然后计算二进制小数系统,根据下面三步的方法就会找出小数源代码和补码的百位形式。/=B/2^6=0.B
-/=B/2^7=0.B
二、将十进制十进制原始码和补码转换成二进制十进制,然后根据下面三步的方法求出十进制源代码和补码形式。一个
0.=0.B
0.=0.B
三、二进制十进制对应的原码和补码
[/]源代码=[0.B]源代码=B
[-/]源代码=[0.b]源代码=B
[0.]原码=[0.b]原码=B
[0.]源代码=[0.B]源代码=B
[/]补体=[0.B]补体=B
[-/]补体=[0.b]补体=B
[0.]补码=[0.b]补码=B
[0.]补体=[0.B]补体=B
扩展资料:
原码、逆码、补码的使用:
在计算机中对数字编码有三种方法,对于正数,这三种方法返回的结果是相同的。
+1=[原码]=[逆码]=[补码]
对于这个负数:
对计算机来说,加、减、乘、除是最基本的运算。有必要使设计尽可能简单。如果计算机能够区分符号位,那么计算机的基本电路设计就会变得更加复杂。
负的正数等于正的负数,2-1等于2+(-1)所以这个机器只做加法,不做减法。符号位参与运算,只保留加法运算。
(1)原始代码操作:
十进制操作:1-1=0。rp没有源码
1-1=1+(-1)=[源代码]+[源代码]=[源代码]=-2。
如果用原代码来表示,让符号位也参与计算,对于减法,结果显然是不正确的,所以计算机不使用原代码来表示一个数字。
(2)逆码运算:
为了解决原码相减的问题,引入了逆码。
十进制操作:1-1=0。
1-1=1+(-1)=[源代码]+[源代码]=[源代码]+[源代码]=[源代码]=[源代码]=-0。
使用反减法,结果的真值部分是正确的,但在特定的值“0”。虽然+0和-0在某种意义上是相同的,但是0加上符号是没有意义的,[源代码]和[源代码]都代表0。
(3)补充操作:
补语的出现解决了零和两个码的符号问题。
十进制运算:1-1=0。
1-1=1+(-1)=[原码]+[原码]=[补码]+[补码]=[补码]=[原码]=0。
这样,0表示为[],而之前的-0问题不存在,可以表示为[]-。
(-1)+(-)=[源代码]+[源代码]=[补充]+[补充]=[补充]=-。
-1-的结果应该是-。在补码操作的结果中,[补码]是-,但是请注意,由于-0的补码实际上是用来表示-的,所以-没有原码和逆码。喵喵出行源码(-的补码表[补码]计算出的[原码]是不正确的)。
如何将小数转化为原码?
一、小数部分的原码和补码可以表示为两个复数的分子和分母,然后计算二进制小数系统,根据下面三步的方法就会找出小数源代码和补码的百位形式。/=B/2^6=0.B
-/=B/2^7=0.B
二、将十进制十进制原始码和补码转换成二进制十进制,然后根据下面三步的方法求出十进制源代码和补码形式。一个
0.=0.B
0.=0.B
三、二进制十进制对应的原码和补码
[/]源代码=[0.B]源代码=B
[-/]源代码=[0.b]源代码=B
[0.]原码=[0.b]原码=B
[0.]源代码=[0.B]源代码=B
[/]补体=[0.B]补体=B
[-/]补体=[0.b]补体=B
[0.]补码=[0.b]补码=B
[0.]补体=[0.B]补体=B
扩展资料:
原码、逆码、补码的使用:
在计算机中对数字编码有三种方法,对于正数,这三种方法返回的结果是相同的。
+1=[原码]=[逆码]=[补码]
对于这个负数:
对计算机来说,加、减、乘、除是最基本的运算。有必要使设计尽可能简单。如果计算机能够区分符号位,那么计算机的基本电路设计就会变得更加复杂。
负的正数等于正的负数,2-1等于2+(-1)所以这个机器只做加法,不做减法。符号位参与运算,只保留加法运算。
(1)原始代码操作:
十进制操作:1-1=0。
1-1=1+(-1)=[源代码]+[源代码]=[源代码]=-2。
如果用原代码来表示,让符号位也参与计算,对于减法,结果显然是不正确的,所以计算机不使用原代码来表示一个数字。
(2)逆码运算:
为了解决原码相减的问题,引入了逆码。
十进制操作:1-1=0。
1-1=1+(-1)=[源代码]+[源代码]=[源代码]+[源代码]=[源代码]=[源代码]=-0。
使用反减法,结果的真值部分是正确的,但在特定的值“0”。虽然+0和-0在某种意义上是相同的,但是0加上符号是没有意义的,[源代码]和[源代码]都代表0。
(3)补充操作:
补语的出现解决了零和两个码的符号问题。
十进制运算:1-1=0。
1-1=1+(-1)=[原码]+[原码]=[补码]+[补码]=[补码]=[原码]=0。
这样,0表示为[],而之前的-0问题不存在,可以表示为[]-。
(-1)+(-)=[源代码]+[源代码]=[补充]+[补充]=[补充]=-。
-1-的结果应该是-。在补码操作的结果中,[补码]是-,但是请注意,由于-0的补码实际上是用来表示-的,所以-没有原码和逆码。(-的补码表[补码]计算出的[原码]是不正确的)。
计算机中的原代码、补码、逆码怎么表示?
一、小数部分的原码和补码可以表示为两个复数的分子和分母,然后计算二进制小数系统,根据下面三步的方法就会找出小数源代码和补码的百位形式。/=B/2^6=0.B
-/=B/2^7=0.B
二、将十进制十进制原始码和补码转换成二进制十进制,然后根据下面三步的方法求出十进制源代码和补码形式。一个
0.=0.B
0.=0.B
三、二进制十进制对应的原码和补码
[/]源代码=[0.B]源代码=B
[-/]源代码=[0.b]源代码=B
[0.]原码=[0.b]原码=B
[0.]源代码=[0.B]源代码=B
[/]补体=[0.B]补体=B
[-/]补体=[0.b]补体=B
[0.]补码=[0.b]补码=B
[0.]补体=[0.B]补体=B
扩展资料:
原码、逆码、补码的使用:
在计算机中对数字编码有三种方法,对于正数,这三种方法返回的结果是相同的。
+1=[原码]=[逆码]=[补码]
对于这个负数:
对计算机来说,加、减、乘、除是最基本的运算。有必要使设计尽可能简单。如果计算机能够区分符号位,那么计算机的基本电路设计就会变得更加复杂。
负的正数等于正的负数,2-1等于2+(-1)所以这个机器只做加法,不做减法。符号位参与运算,只保留加法运算。
(1)原始代码操作:
十进制操作:1-1=0。
1-1=1+(-1)=[源代码]+[源代码]=[源代码]=-2。
如果用原代码来表示,让符号位也参与计算,对于减法,结果显然是不正确的,所以计算机不使用原代码来表示一个数字。
(2)逆码运算:
为了解决原码相减的问题,引入了逆码。
十进制操作:1-1=0。
1-1=1+(-1)=[源代码]+[源代码]=[源代码]+[源代码]=[源代码]=[源代码]=-0。
使用反减法,结果的真值部分是正确的,但在特定的值“0”。虽然+0和-0在某种意义上是相同的,但是0加上符号是没有意义的,[源代码]和[源代码]都代表0。
(3)补充操作:
补语的出现解决了零和两个码的符号问题。
十进制运算:1-1=0。
1-1=1+(-1)=[原码]+[原码]=[补码]+[补码]=[补码]=[原码]=0。
这样,0表示为[],而之前的-0问题不存在,可以表示为[]-。
(-1)+(-)=[源代码]+[源代码]=[补充]+[补充]=[补充]=-。
-1-的结果应该是-。在补码操作的结果中,[补码]是-,但是请注意,由于-0的补码实际上是用来表示-的,所以-没有原码和逆码。(-的补码表[补码]计算出的[原码]是不正确的)。
CRCåçç®ä»
æè¿å好ææ¶é´ï¼æ´çäºä¸ä¸å ³äºCRCçèµæï¼è¯¦ç»å¯¹æ¯äºä¸ç¨åºçå®ç°è¿ç¨ååçï¼å½ç¶ï¼é«æé½æ¯ä¸å¨æçã
æ¬æ主è¦ä»ç»CRCçä¸äºåºç¡ç¥è¯ï¼ä¸ªäººæ¶è·æ¯åé¢å ³äºç½ä¸æ åDemoç¨åºçä¸äºè¯¦ç»è§£æãè§ä¸ä¸ç¯/p/c0dc2ece
声æï¼æ¬æå®ä¹é¨ååèç½ä¸å¤å¤èµæï¼åªæ¯ä¸ºäºæ¹ä¾¿å个ç¬è®°ï¼å¼ç¨ç½æåä¸äºæ´æ¹ï¼å¦æé·åï¼è¯·ç§ä¿¡è¯´æ并修æ¹ã
ä¸ãå ³äºCRCçä»ç»
CRCå³å¾ªç¯åä½æ ¡éªç ï¼Cyclic Redundancy Checkï¼ï¼æ°æ®éä¿¡é¢åä¸æ常ç¨çä¸ç§å·®éæ ¡éªç ï¼å ¶ä¿¡æ¯å段åæ ¡éªå段é¿åº¦å¯ä»¥ä»»ææå®ï¼ä½è¦æ±éä¿¡åæ¹å®ä¹çCRCæ åä¸è´ã
äºãå·¥ä½åç
对äºå·¥æ§é¢åï¼æ们主è¦å©ç¨CRCæ ¡éªæ¥å¤çåç§æ°æ®æµçæ°æ®æ£ç¡®æ§æ ¡éªã
CRCåç ï¼å¨Kä½ä¿¡æ¯ç ï¼ç®æ åéæ°æ®ï¼ååæ¼æ¥Rä½æ ¡éªç ï¼ä½¿æ´ä¸ªç¼ç é¿åº¦ä¸ºNä½ï¼å æ¤è¿ç§ç¼ç ä¹å«ï¼N,Kï¼ç ãéä¿ç说ï¼å°±æ¯å¨éè¦åéçä¿¡æ¯åé¢éå ä¸ä¸ªæ°ï¼å³æ ¡éªç ï¼ï¼çæä¸ä¸ªæ°çåéæ°æ®åéç»æ¥æ¶ç«¯ãè¿ä¸ªæ°æ®è¦æ±è½å¤ä½¿çæçæ°æ°æ®è¢«ä¸ä¸ªç¹å®çæ°æ´é¤ãè¿éçæ´é¤éè¦å¼å ¥æ¨¡ 2é¤æ³çæ¦å¿µï¼éä¸ç¾åº¦ç¾ç§å ³äºæ¨¡2计ç®çé¾æ¥ï¼
/item/模2è¿ç®/?fr=aladdin
é£ä¹ï¼CRCæ ¡éªçå ·ä½åæ³å°±æ¯
ï¼1ï¼éå®ä¸ä¸ªæ åé¤æ°ï¼Kä½äºè¿å¶æ°æ®ä¸²ï¼
ï¼2ï¼å¨è¦åéçæ°æ®ï¼mä½ï¼åé¢å ä¸K-1ä½0ï¼ç¶åå°è¿ä¸ªæ°æ°ï¼M+K-1ä½ï¼ä»¥æ¨¡2é¤æ³çæ¹å¼é¤ä»¥ä¸é¢è¿ä¸ªæ åé¤æ°ï¼æå¾å°çä½æ°ä¹å°±æ¯è¯¥æ°æ®çCRCæ ¡éªç ï¼æ³¨ï¼ä½æ°å¿ é¡»æ¯é¤æ°å°ä¸åªå°ä¸ä½ï¼ä¸å¤å°±è¡¥0ï¼
ï¼3ï¼å°è¿ä¸ªæ ¡éªç éå¨åmä½æ°æ®åé¢ï¼æææ°çM+K-1ä½æ°æ®ï¼åéç»æ¥æ¶ç«¯ã
ï¼4ï¼æ¥æ¶ç«¯å°æ¥æ¶å°çæ°æ®é¤ä»¥æ åé¤æ°ï¼å¦æä½æ°ä¸º0å认为æ°æ®æ£ç¡®ã
注æï¼ CRCæ ¡éªä¸æä¸¤ä¸ªå ³é®ç¹ï¼ä¸æ¯è¦é¢å ç¡®å®ä¸ä¸ªåé端åæ¥æ¶ç«¯é½ç¨æ¥ä½ä¸ºé¤æ°çäºè¿å¶æ¯ç¹ä¸²ï¼æå¤é¡¹å¼ï¼ï¼äºæ¯æåå§å¸§ä¸ä¸é¢éå®çé¤è¿è¡äºè¿å¶é¤æ³è¿ç®ï¼è®¡ç®åºFCSãåè å¯ä»¥éæºéæ©ï¼ä¹å¯æå½é ä¸éè¡çæ åéæ©ï¼ä½æé«ä½åæä½ä½å¿ é¡»å为â1â
å®ä¾ï¼å¯¹äºæ°æ®ï¼#B3ï¼ï¼ä»¥æå®é¤æ°æ±å®çCRCæ ¡éªç ï¼å ¶è¿ç¨å¦ä¸ï¼
å ³äºæ ¡éªç ç计ç®ï¼éç¹æ¥äºï¼
å纯è°CRCç模2é¤æ³å ¶å®å¹¶ä¸å°é¾ï¼ä½å®é 计ç®ä¸ç»å¸¸ä¼éå°è®¡ç®åºæ¥çç»æåå®é ä¸ä¸è´çæ åµï¼è¿ä¹æ¯è¿å 天æå¨ççä¸è¥¿ã
è¿ééè¦ç¥éå 个ç»æé¨åæè 说计ç®æ¦å¿µï¼å¤é¡¹å¼å ¬å¼ãå¤é¡¹å¼ç®è®°å¼ãæ°æ®å®½åº¦ãåå§å¼ãç»æå¼æå¼ãè¾å ¥å¼å转ãè¾åºå¼å转ãåæ°æ¨¡åã
1ãå¤é¡¹å¼å ¬å¼
对äºCRCæ åé¤æ°ï¼ä¸è¬ä½¿ç¨å¤é¡¹å¼ï¼æäºé¡¹å¼ï¼å ¬å¼è¡¨ç¤ºï¼å¦ä¸ä¾ä¸é¤æ°çäºé¡¹å¼ä¸ºG(X)=X4+X3+X+1ï¼Xçææ°å°±ä»£è¡¨äºè¯¥bitä½ä¸çæ°æ®ä¸º1,ï¼æä½ä½ä¸º0ï¼ãè¿éç¹å«æ³¨æä¸ä¸ä½æ°é®é¢ï¼é¤æ°çä½æ°ä¸ºäºé¡¹å¼æé«æ¬¡å¹+1ï¼4+1=5ï¼ï¼è¿ä¸ªå¾éè¦ã
2ãå¤é¡¹å¼ç®è®°å¼
éè¿å¯¹CRCçåºæ¬äºè§£æ们ç¥éï¼å¤é¡¹å¼çé¦å°¾å¿ å®ä¸º1ï¼èè¿ä¸ª1çä½ç½®å¨ä¸ä¸æ¥è®¡ç®ä¸å®ä¸º0ï¼æ以就æåé¢è¿ä¸ª1ç»çç¥æäºï¼åºç°äºä¸ä¸ªå«ç®è®°å¼çä¸è¥¿ï¼å¦ä¸ä¾ä¸é¤æ°çç®è®°å¼ä¸ºï¼å¾å¤çè¿CRCé«çº§è¯è¨æºç ç人ä¼ç¥éï¼å¯¹äºCRC_æ åä¸G(X)=X+X+X2+1ï¼#ï¼çpolyå¼å®é ä¸æ¯ï¼è¿é使ç¨çå°±æ¯ç®è®°å¼ãåé¢ä¼å¯¹è¿ä¸ªç¨æ³åä¸ä¸ªè¯´æã
3ãæ°æ®å®½åº¦
æ°æ®å®½åº¦æçå°±æ¯CRCæ ¡éªç çé¿åº¦ï¼äºè¿å¶ä½æ°ï¼ï¼ç¥éäºCRCçè¿ç®æ¦å¿µåå¤é¡¹å¼ï¼å°±å¯ä»¥ç解è¿ä¸ªæ¦å¿µäºï¼CRCé¿åº¦å§ç»è¦æ¯é¤æ°ä½æ°å°1ï¼ä¸ç®è®°å¼é¿åº¦æ¯ä¸è´çã
以ä¸ä¸ä¸ªæ°æ®å°±æ¯æ们ç»å¸¸è½å¤ç¨å°çåºæ¬æ°æ®
4ãåå§å¼ä¸ç»æå¼æå¼
å¨ä¸äºæ åä¸ï¼è§å®äºåå§å¼ï¼åæ°æ®å¨è¿è¡ä¸è¿°äºé¡¹å¼è¿ç®ä¹åï¼éè¦å å°è¦è®¡ç®çæ°æ®ä¸åå§å¼çæä½åèè¿è¡å¼æï¼ç¶ååä¸å¤é¡¹å¼è¿è¡è®¡ç®ã
èå¨ç»æå¼æå¼ä¸ä¸ºé¶çæ åµä¸ï¼åéè¦å°è®¡ç®å¾å°çCRCç»æå¼åä¸ç»æå¼æå¼è¿è¡ä¸æ¬¡å¼æ计ç®ï¼å¾å°çæç»å¼ææ¯æ们éè¦çCRCæ ¡éªç ã
è¿éå¯ä»¥çåºï¼åå§å¼ä¸ç»æå¼çä½æ°è¦æ±ä¸æ°æ®å®½åº¦ä¸è´ã
5ãè¾å ¥å¼å转ä¸è¾åºå¼å转
è¾å ¥å¼å转çæææ¯å¨è®¡ç®ä¹åå å°äºé¡¹å¼å转ï¼ç¶ååç¨å¾å°çæ°å¼åæ°æ®è¿è¡è®¡ç®ãå¦å¯¹äºG(X)=X+X+X2+1ï¼#ï¼ï¼å ¶æ£åå¼ä¸º1 ï¼å转å¼å为 1
è¾åºå¼å转åæ¯å°æç»å¾å°çCRCç»æå转ã
é常ï¼è¾å ¥å¼å转åçç»æå¼ä¹ä¼æ¯å转çï¼æ以è¿ä¸¤ä¸ªé项ä¸è¬æ¯ååçï¼æ们åªæå¨å¨çº¿CRC计ç®å¨ä¸ä¼çå°èªç±éæ©æ£å转çæ åµåå¨ã
é£ä¹ï¼è¿éå¼ç¨CSDNå主 bobde çä¸æ®µæ»ç»ï¼
CRCãCRCçå¤åèçæ ¡éªå¼ç计ç®æå ç¹éè¦æ¸ æ¥ï¼åªé对ä¸æ¬¡ä¸ä¸ªåèçç®æ³ï¼ï¼
1) åå§å¼ä¸ä¸º0çæ åµä¸ï¼è¯¥å¦ä½è®¡ç®ï¼
è¾å ¥æ°æ®éè¦å转ï¼å å°è¦è®¡ç®çæ°æ®ä¸åå§å¼çæä½åèè¿è¡å¼æï¼åä¸å转åçå¤é¡¹å¼è¿è¡è®¡ç®ã
è¾å ¥æ°æ®ä¸éè¦å转ï¼å å°è¦è®¡ç®çæ°æ®å·¦ç§»å°ä¸åå§å¼å¯¹é½çä½ç½®ï¼å¦CRCç®æ³ï¼å左移8ä½ï¼ä½ä½å¡«å 0ï¼å¦CRCç®æ³ï¼å左移ä½ï¼ä½ä½å¡«å 0ï¼ä¸åå§å¼è¿è¡å¼æï¼åä¸æ£å¸¸çå¤é¡¹å¼è¿è¡è®¡ç®ã
2) ç»æå¼æå¼ä¸ä¸º0çæ åµï¼ç¬¬ä¸æ¥ç®å¾å°çCRCå¼åä¸ç»æå¼æå¼è¿è¡å¼ææä½å¾å°æç»çæ ¡éªå¼ï¼
è¾åºæ°æ®å转ï¼å¦æè¾å ¥æ°æ®æ¯å转ç模å¼ï¼åç»æä¹æ¯å转ç
è¾åºæ°æ®ä¸å转ï¼å¦æè¾å ¥æ°æ®æ¯ä¸å转ç模å¼ï¼åç»æä¹æ¯ä¸å转ç
3ï¼åå§å¼çéæ©æ¯å¯èªå·±å®ä¹ï¼å¾å¤ä¸åçå家使ç¨çåå§å¼æ¯ä¸ä¸æ ·ï¼ä¸ä¸æ ·çåå§å¼å¾å°çç»æä¹æ¯ä¸ä¸æ ·çã
---------------------
åæï¼/bobde/article/details/
ä¸åçäºé¡¹å¼ãåå§å¼ãç»æå¼æå¼ãå转ååé½ä¼é ææç»çç»æä¸ä¸è´ï¼è¿å°±æ¯ä¸ºä»ä¹æææ¯æ£ç¡®ç计ç®æ¹å¼ï¼ææ¶åç®åºæ¥çç»æå´æ»æ¯ä¸æ£ç¡®ã
é£ä¹ï¼å¦ä½å»å¤æåºè¯¥éç¨åªäºååå¢ï¼è¿éè°å°æåä¸ä¸ªæ¦å¿µï¼
6ãåæ°æ¨¡å
è½ç¶CRCå¯ä»¥ä»»æå®ä¹äºé¡¹å¼ãæ°æ®é¿åº¦çï¼ä½æ²¡æä¸ä¸ªç»ä¸çæ åçè¯ï¼å°±ä¼è®©æ´ä¸ªè®¡ç®åå¾é常ç麻ç¦ãä½å®é ä¸ï¼ä¸åçå家ç»å¸¸éç¨ä¸åçæ åç®æ³ï¼è¿éååºäºä¸äºå½é 常ç¨ç模å表ï¼
以ä¸ä¸ºå ³äºCRCçç¬è®°ï¼ä¸ä¸ç¯è®²ä¸è®²é«çº§è¯è¨å®ç°æè·¯
如何计算小数的原码和补码?
一、小数部分的原码和补码可以表示为两个复数的分子和分母,然后计算二进制小数系统,根据下面三步的方法就会找出小数源代码和补码的百位形式。/=B/2^6=0.B
-/=B/2^7=0.B
二、将十进制十进制原始码和补码转换成二进制十进制,然后根据下面三步的方法求出十进制源代码和补码形式。一个
0.=0.B
0.=0.B
三、二进制十进制对应的原码和补码
[/]源代码=[0.B]源代码=B
[-/]源代码=[0.b]源代码=B
[0.]原码=[0.b]原码=B
[0.]源代码=[0.B]源代码=B
[/]补体=[0.B]补体=B
[-/]补体=[0.b]补体=B
[0.]补码=[0.b]补码=B
[0.]补体=[0.B]补体=B
扩展资料:
原码、逆码、补码的使用:
在计算机中对数字编码有三种方法,对于正数,这三种方法返回的结果是相同的。
+1=[原码]=[逆码]=[补码]
对于这个负数:
对计算机来说,加、减、乘、除是最基本的运算。有必要使设计尽可能简单。如果计算机能够区分符号位,那么计算机的基本电路设计就会变得更加复杂。
负的正数等于正的负数,2-1等于2+(-1)所以这个机器只做加法,不做减法。符号位参与运算,只保留加法运算。
(1)原始代码操作:
十进制操作:1-1=0。
1-1=1+(-1)=[源代码]+[源代码]=[源代码]=-2。
如果用原代码来表示,让符号位也参与计算,对于减法,结果显然是不正确的,所以计算机不使用原代码来表示一个数字。
(2)逆码运算:
为了解决原码相减的问题,引入了逆码。
十进制操作:1-1=0。
1-1=1+(-1)=[源代码]+[源代码]=[源代码]+[源代码]=[源代码]=[源代码]=-0。
使用反减法,结果的真值部分是正确的,但在特定的值“0”。虽然+0和-0在某种意义上是相同的,但是0加上符号是没有意义的,[源代码]和[源代码]都代表0。
(3)补充操作:
补语的出现解决了零和两个码的符号问题。
十进制运算:1-1=0。
1-1=1+(-1)=[原码]+[原码]=[补码]+[补码]=[补码]=[原码]=0。
这样,0表示为[],而之前的-0问题不存在,可以表示为[]-。
(-1)+(-)=[源代码]+[源代码]=[补充]+[补充]=[补充]=-。
-1-的结果应该是-。在补码操作的结果中,[补码]是-,但是请注意,由于-0的补码实际上是用来表示-的,所以-没有原码和逆码。(-的补码表[补码]计算出的[原码]是不正确的)。