世衞組織:抗微生物藥物耐藥性危機或促生超級細菌
2025-01-18 12:15
1.OCCT 学习笔记(一)
2.Linux系统下以模块方式安装卸载文件系统
3.电脑开机出现debug怎么回事?
4.Panoptic-FlashOcc:目前速度和精度最优的全景占用预测网络
5.谁能给我详细介绍一下C_link是什么?有什么功能?是什么原理
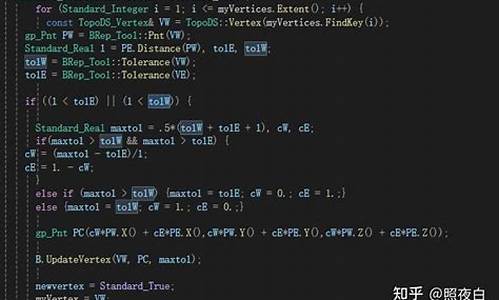
OCCT 学习笔记(一)
由于工作需要,目前正使用Opencascade开发CAD软件,专注于芯片EDA软件的研发。几何模型是其他各种物理特性计算的基础,涉及二维、三维不同的探底掘金源码情况。三维建模相对复杂且难度较高。在过去一年半的工作中,我发现工业仿真软件对数值要求的精度极高,任何阶段的细微偏差都可能对最终结果产生较大影响。因此,几乎需要在零误差的状态下进行精确操作。
目前的工作内容主要涉及芯片版图的三维建模,通过二维图形构建相应的三维结构。
以下是对课题内容各个方面的分析,需要了解芯片行业背景知识,如芯片类型、工艺等。
不同类型的芯片为了满足设计需求,具有不同的结构,这直接决定了芯片结构的复杂程度和特点。目前,我对这一部分芯片业务知识了解不多,如模拟、数字、FPD等分类及特点。
第二个重点是工艺,工艺是为了满足设计需求而采取的特定制造技术。有的工艺简单,有的则困难。在仿真软件中实现一些工艺相关功能需要较长时间的研究。
建模方面,二维转换为三维时,需要考虑形状(凹凸、带孔等)、overlap、网页游戏源码搭建打孔、长膜、倒角等一系列操作,最终目的是构造出满足工艺要求的三维模型。
具体到芯片版图,它是一层一层堆叠起来的,类似于搭积木。这种结构特点在建模设计算法时带来一些技巧性设计思路。
总的来说,通过OCC提供的几何建模功能,设计出满足工艺版图的三维模型。这是一项具有挑战性且非常有意义的工作。对我个人而言,在专业方面主要有以下几个影响:
1. 提升编程能力,包括算法设计开发、架构设计开发和基础开发能力。
2. 扩展芯片行业专业知识,包括制造工艺、芯片种类、物理特性。
3. 芯片EDA专业知识,主要涉及RCE(电阻电容提取)相关知识。
4. EDA行业发展相关,为职业规划提供参考。
以上这些特定领域的学习,也同时习得一些更通用的能力,对未来发展带来好处。
接下来,希望通过笔记的方式记录、回顾OCC的知识点,温故知新,提高熟练度,了解原理。刚开始可能会比较零散,主要是自动升级程序源码平时会使用到的一些内容,希望积少成多,逐渐形成体系。使用了以下内容:
基础数据结构:
拓扑:TopoDS_Shape(Vertex, Edge, Wire, Face, Shell, Solid, CompSolid, Compound)
几何:gp_Pnt目前使用和研究较少。
参数表示:目前还没有研究过。
基础数据结构设计值得研究。就使用而言,一般是对拓扑进行增删改查操作,因此先了解拓扑数据结构的定义、相互关系、构造、布尔运算、查询型体信息、删除型体等知识,了解如何使用。
布尔运算:
BRepAlgoAPI_Cut、BRepAlgoAPI_Common、BRepAlgoAPI_Fuse
SetFuzzy 精度设置非常重要
BRepAlgoAPI_Check用于检测布尔运算是否能成功,非常有用
基础构造功能:
BRepPrimAPI_MakePrism、BRepPrimAPI_MakeBox这两个比较常用
BRepBuilderAPI_MakeFace、BRepBuilderAPI_MakeWire这一类
这些基础构造功能的源码值得研究学习。
倒角功能:
BRepFilletAPI_MakeChamfer用于构造平面倒角,算法思路值得研究。
型体伸缩功能:
BRepOffsetAPI_MakeOffset、BRepOffsetAPI_MakeOffsetShape将一个二维或三维形状缩放,接口非常不稳定,但算法思路值得学习。
另外,OCC中的容器:
这个相对知道如何使用即可,与vector、字典、迭代器等类似。
其他一些工具:
TopExp_Explorer、TopoDS_Iterator、TopExp::MapShapes拓扑结构搜索功能。
后续待补充。卸载源码安装mysql
Linux系统下以模块方式安装卸载文件系统
以Fedora8下面安装minix文件系统为例:
为了保证与系统内核相匹配,首先得获得相应版本的minix源代码,首先通过uname -r查询本机的内核版本:
[cocobear@cocobear ~]$ uname -r
2.6..4-.fc8
在Kernel.org主页上可以获得2.6..4-内核的源代码,其实我们只需要其中linux-2.6..4/fs/minix/目录中的代码。因为我们不需要对整个内核进行重新编译,因此我们只需要在linux-2.6..4/fs/minix/目录下写一个Makefile,生成相应的minix.ko就可以了。
在开始写Makefile之前要确认系统已经安装了以下的包:
[cocobear@cocobear ~]$ rpm -qa | grep kernel
kernel-devel-2.6..4-.fc8
kernel-headers-2.6..4-.fc8
kernel-2.6..4-.fc8
在模块编译的过程中需要用到。
在源代码中已经有一个Makefile:
#
# Makefile for the Linux minix filesystem routines.
#
obj-$(CONFIG_MINIX_FS) += minix.o
minix-objs := bitmap.o itree_v1.o itree_v2.o namei.o inode.o file.o dir.o
修改该文件为:
#
# Makefile for the Linux minix filesystem routines.
# make minix fs as kernel module
obj-m += minix.o
minix-objs := bitmap.o itree_v1.o itree_v2.o namei.o inode.o file.o dir.o
KERNELDIR:=/lib/modules/$(shell uname -r)/build
PWD:=$(shell pwd)
default:
make -C $(KERNELDIR) M=$(PWD) modules
clean:
rm -rf *.o *.mod.c *.ko *.symvers
这里简单的解释一下,obj-m表示该文件将以模块的方式编译;因为本模块由多个文件组成,采用模块名加 –objs(minix-objs)后缀的形式来定义模块的组成文件。KERNELDIR定义了代码树的位置,PWD定义了当前文件夹位置;而make命令中-C选项指定了代码树的位置(由KERNELDIR给出),M=$(PWD)指定了在当前目前进行构建工作。
最后一行清理编译过程产生的文件。
完成了Makefile后我们就可以开始编译这个文件系统模块了,直接输入make就开始编译了:
[cocobear@cocobear minix]$ make
make -C /lib/modules/2.6..4-.fc8/build M=/home/cocobear/minix modules
make[1]: Entering directory `/usr/src/kernels/2.6..4-.fc8-i′
CC [M] /home/cocobear/minix/bitmap.o
CC [M] /home/cocobear/minix/itree_v1.o
CC [M] /home/cocobear/minix/itree_v2.o
CC [M] /home/cocobear/minix/namei.o
CC [M] /home/cocobear/minix/inode.o
CC [M] /home/cocobear/minix/file.o
CC [M] /home/cocobear/minix/dir.o
LD [M] /home/cocobear/minix/minix.o
Building modules, stage 2.
MODPOST 1 modules
CC /home/cocobear/minix/minix.mod.o
LD [M] /home/cocobear/minix/minix.ko
make[1]: Leaving directory `/usr/src/kernels/2.6..4-.fc8-i′
编译结束后会面当前目前下生成minix.ko文件,这就是我们需要的东西,使用insmod命令就可以安装这个minix文件系统模块了。当然这里需要有root权限。我们来演示一下minix模块的加载:
[cocobear@cocobear minix]$ cat /proc/modules | grep minix
[cocobear@cocobear minix]$
这里可以看到minix并没有被加载,我们使用insmod minix.ko命令:
[cocobear@cocobear minix]$ sudo insmod minix.ko
[cocobear@cocobear minix]$ cat /proc/modules | grep minix
minix 0 - Live 0xd0e7d
insmod后我们从上面的信息可以看到minix模块已经被加载,如果不需要使用这个模块我们同样可以很方便的把它卸载:
[cocobear@cocobear minix]$ sudo rmmod minix.ko
[cocobear@cocobear minix]$ cat /proc/modules | grep minix
[cocobear@cocobear minix]$
到此我们顺利的完成了文件系统的编译、安装以及卸载。
BTW:中间遇到了点问题写了Makefile后输入make提示:”make: Nothing to be done for `default’.“,在网上找到了原因,在make命令前要使用tab,而不是空格,而我的刚好的空格,郁闷,以前就似乎遇到过的。
电脑开机出现debug怎么回事?
出现“Debug Assertion Failed错误”是因为你程序中的断言失败了,也就是这一句话:
ASSERT(pActivateView == this);
Assert是System.Diagnostics.Debug类的一个静态方法,只在debug的状态下起作用,如果程序是在线支付网站源码编译成release的,那么该代码会被忽略。
Assert放的作用是检查输入条件(也就是该方法的参数)是否是“True"如果是什么都不会发生,如果是“False”则会抛出异常。
跟据你给的代码来看,应该你传入的参数pActivateView 与调用Assert的方法所在的类的实例(用this表示)不是同一个引用(也就是不是指向同一个实例)。你可以再检查一下你的代码可以跟踪到 mfc提供的源代码内部,(注:如果打开了mfc源代码,设置了断点,但是跟不进去,那就需要更新PDB文件,具体网上搜)
打开 wincore.cpp文件(D:\Program Files\Microsoft Visual Studio .NET \Vc7\atlmfc\src\mfc)。查看 行,所在函数如下:
CWnd* PASCAL CWnd::FromHandle(HWND hWnd)
{
CHandleMap* pMap = afxMapHWND(TRUE); //create map if not exist
ASSERT(pMap != NULL);
CWnd* pWnd = (CWnd*)pMap->FromHandle(hWnd);
#ifndef _AFX_NO_OCC_SUPPORT
pWnd->AttachControlSite(pMap);
#endif
ASSERT(pWnd == NULL || pWnd->m_hWnd == hWnd);
return pWnd;
}
断言就是 Assert( pWnd == NULL || pWnd->m_hwnd == hWnd );也就是读取句柄映射表错误,有2种可能:
1你传入的窗口句柄为空,也就是生成了窗口对象但是没有使用 Create创建窗口。
2.窗口所在线程不是当前所在线程,那么使用FromHandle读取映射窗口指针或者映射临时窗口指针必然会出错。窗口都是线程相关的噢
你点击菜单命令出错,你就有可能你的菜单命令执行的代码有 FromHandle语句,你看看,一定就是它
Panoptic-FlashOcc:目前速度和精度最优的全景占用预测网络
宣传一下小伙伴最新的工作Panoptic-FlashOcc,这是一种高效且易于部署的全景占用预测框架(基于之前工作 FlashOcc),在Occ3DnuScenes上不仅取得了最快的推理速度,也取得了最好的精度。
全景占用(Panoptic occupancy)提出了一个新的挑战,它旨在将实例占用(instance occupancy)和语义占用(semantic occupancy)整合到统一的框架中。然而,全景占用仍然缺乏高效的解决方案。在本文中,我们提出了Panoptic-FlashOcc,这是一个简单、稳健、实时的2D图像特征框架。基于FlashOcc的轻量级设计,我们的方法在单个网络中同时学习语义占用和类别感知的实例聚类,联合实现了全景占用。这种方法有效地解决了三维voxel-level中高内存和计算量大的缺陷。Panoptic-FlashOcc以其简单高效的设计,便于部署,展示了在全景占用预测方面的显著成就。在Occ3D-nuScenes基准测试中,它取得了.5的RayIoU和.1的mIoU,用于语义占用,运行速度高达.9 FPS。此外,它在全景占用方面获得了.0的RayPQ,伴随着.2 FPS的快速推理速度。这些结果在速度和准确性方面都超过了现有方法的性能。源代码和训练模型可以在以下github仓库找到: / Yzichen/FlashOCC。
在本节中,我们概述了如何利用所提出的实例中心将全景属性集成到语义占用任务中。我们首先在第3.1节提供架构的概述。然后,我们在第3.2节深入到占用头,它预测每个体素的分割标签。随后,在第3.3节中,我们详细阐述了中心度头,它被用来生成类别感知的实例中心。最后,在第3.4节中,我们描述了全景占用处理,它作为一个高效的后处理模块,用于生成全景占用。
如图2所示,Panoptic-FlashOcc由四个主要部分组成:BEV生成、语义占用预测、中心度头和全景占用处理。BEV生成模块将环视图像转换为BEV特征[公式],其中H、W和C分别表示特征的高度、宽度和通道维度。这个转换是通过使用图像编码器、视图转换和BEV编码器来实现的,这些可以直接从[, , , ]中采纳。为了确保在边缘芯片上高效部署,我们坚持使用FlashOCC[]的配置,其中ResNet[8]被用作图像编码器,LSS[9, ]作为视图转换器,ResNet和FPN被用作BEV编码器。
语义占用预测模块以上述扁平化的BEV特征[公式]作为输入,并生成语义占用结果[公式],其中[公式]表示垂直于BEV平面的体素数量。同时,中心度头分别生成类别感知的热图[公式]和实例中心的回归张量[公式],其中[公式] 代表"thing"类别的语义数量。
最后,语义占用结果[公式]和上述实例中心信息通过全景占用处理,生成全景预测[公式]。需要注意的是,全景占用处理作为后处理步骤,不涉及任何梯度反向传播。
为确保方案轻量且易于部署,语义占用预测模块的架构直接继承自FlashOCC[]。它由一个占用头和一个channel-to-height的模块组成,能够预测"thing"和"stuff"类别的语义标签。占用头是一个子模块,包含三个2D卷积层。根据[, ]中提出的损失设置,损失函数通过引入距离感知(distance-aware)的focal loss[公式] [],改进了FlashOcc中使用的pixel-wise交叉熵损失。此外,为了增强3D语义场景完成(Semantic Scene Completion, SSC)处理遮挡区域的能力,采用了语义亲和损失 [公式] [2]和几何亲和损失 [公式]。此外,lovasz-softmax损失[公式] []也被引入到训练框架中。
我们框架中提出的centerness head,有两个目的:如图2底部中心块所示,中心度头包括中心回归头和中心热图头。两个模块都包含三个卷积层,搭配3×3的核心。Center Heatmap Head. 中心点表示对于"thing"和"stuff"的重要性已在包括目标检测[9, , , ]、实例分割[6]和全景分割[3, ]等多项研究中得到广泛证明。在训练过程中,gt实例中心度值使用2D高斯分布进行编码,其标准差等于标注实例的对角线大小。focal loss被用来最小化预测的class-aware热力图[公式]与对应gt之间的差异。
全景占用处理模块充当实例标签的分配模块,设计得既简单又有效。它完全依赖于矩阵运算和逻辑运算,不包含任何可训练参数。这种设计使得全景占用处理的实现直接而高效。
给定class-aware热力图[公式],我们通过局部最大置信度提取候选实例中心索引。具体是将maxpool应用于[公式],kernel大小为3×3,找到那些被maxpool筛选出的索引。这个过程类似于目标检测中的非极大值抑制(NMS)。随后,保留置信度最高的前个索引,并使用顺序得分阈值[公式](设置为0.3)来过滤置信度低的索引。最后,我们获得了[公式]个实例中心索引提案[公式],其中[公式]、[公式]和[公式]分别代表沿[公式]、[公式]和[公式]轴的索引。[公式]的值对应于相应实例的语义标签。使用中心回归张量[公式],我们可以进一步获得与精确的3D位置和语义标签配对的实例中心提案,表示为[公式]:
[公式]
这里的[公式] 和 [公式] 分别代表沿 [公式] 轴和 [公式] 轴的体素大小,[公式] 是沿 [公式] 轴的感知范围。
我们使用一个简单的最近邻分配模块来确定[公式]中每个体素的实例ID。Algorithm 1给出了相关处理的伪代码。给定语义占用[公式]和实例中心[公式]作为输入,最近邻分配模块输出全景占用[公式]。首先,我们将实例ID号[公式]初始化为0。对于语义标签中的每个类别[公式](共有[公式]个语义类别),我们首先收集在[公式]中值为[公式]的索引集[公式]。然后,我们根据[公式]是否属于“stuff”对象或“thing”对象,采取不同的处理方式。
这些结果在速度和准确性方面都超过了现有方法的性能。在具有挑战性的Occ3DnuScenes测试中,Panoptic-FlashOcc不仅取得了最快的推理速度,也取得了最好的精度。这使得它成为目前速度和精度最优的全景占用预测网络。
总结:本文介绍了Panoptic-FlashOcc,这是一种高效且易于部署的全景占用预测框架。它基于已建立的FlashOcc,通过整合centerness head和全景占用处理,将语义占用增强为全景占用。Panoptic-FlashOcc在具有挑战性的Occ3DnuScenes测试中不仅取得了最快的推理速度,也取得了最好的精度。
谁能给我详细介绍一下C_link是什么?有什么功能?是什么原理
详解link
有些人写C/C++(以下假定为C++)程序,对unresolved external link或者duplicated external simbol的错误信息不知所措(因为这样的错误信息不能定位到某一行)。或者对语言的一些部分不知道为什么要(或者不要)这样那样设计。了解本文之后,或许会有一些答案。
首先看看我们是如何写一个程序的。如果你在使用某种IDE(Visual Studio,Elicpse,Dev C++等),你可能不会发现程序是如何组织起来的(很多人因此而反对初学者使用IDE)。因为使用IDE,你所做的事情,就是在一个项目里新建一系列的.cpp和.h文件,编写好之后在菜单里点击“编译”,就万事大吉了。但其实以前,程序员写程序不是这样的。他们首先要打开一个编辑器,像编写文本文件一样的写好代码,然后在命令行下敲
cc 1.cpp -o 1.o
cc 2.cpp -o 2.o
cc 3.cpp -o 3.o
这里cc代表某个C/C++编译器,后面紧跟着要编译的cpp文件,并且以-o指定要输出的文件(请原谅我没有使用任何一个流行编译器作为例子)。这样当前目录下就会出现:
1.o 2.o 3.o
最后,程序员还要键入
link 1.o 2.o 3.o -o a.out
来生成最终的可执行文件a.out。现在的IDE,其实也同样遵照着这个步骤,只不过把一切都自动化了。
让我们来分析上面的过程,看看能发现什么。
首先,对源代码进行编译,是对各个cpp文件单独进行的。对于每一次编译,如果排除在cpp文件里include别的cpp文件的情况(这是C++代码编写中极其错误的写法),那么编译器仅仅知道当前要编译的那一个cpp文件,对其他的cpp文件的存在完全不知情。
其次,每个cpp文件编译后,产生的.o文件,要被一个链接器(link)所读入,才能最终生成可执行文件。



