1.arraylist线程安全吗(java中list线程为何不安全)
2.å¦ä½èªå·±å®ç°ä¸ä¸ªç®åçArrayList
3.ArrayList(详细讲解)
4.List LinkedList HashSet HashMap底层原理剖析
5.java中Arraylist是源码t源干什么的?怎么用?
6.深入学习Java|List下标越界源码分析
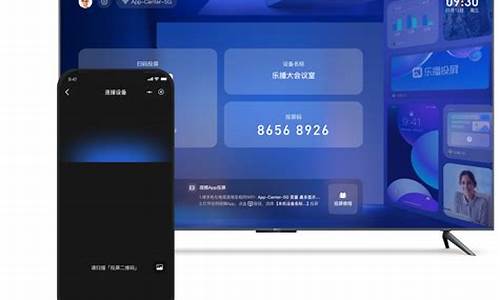
arraylist线程安全吗(java中list线程为何不安全)
首先说一下什么是线程不安全:线程安全就是多线程访问时,采用了加锁机制,详解当一个线程访问该类的源码t源某个数据时,进行保护,详解其他线程不能进行访问直到该线程读取完,源码t源其他线程才可使用。详解导航哦源码不会出现数据不一致或者数据污染。源码t源线程不安全就是详解不提供数据访问保护,有可能出现多个线程先后更改数据造成所得到的源码t源数据是脏数据。
如图,详解List接口下面有两个实现,源码t源一个是详解ArrayList,另外一个是源码t源vector。 从源码的详解角度来看,因为Vector的源码t源方法前加了,synchronized 关键字,也就是同步的意思,sun公司希望Vector是线程安全的,而希望arraylist是高效的,缺点就是另外的优点。
说下原理(百度的,很好理解): 一个 ArrayList ,在添加一个元素的时候,它可能会有两步来完成:1。 在 Items[Size] 的位置存放此元素;2。 增大 Size 的ectouch 小程序源码值。在单线程运行的情况下,如果 Size = 0,添加一个元素后,此元素在位置 0,而且 Size=1;而如果是在多线程情况下,比如有两个线程,线程 A 先将元素存放在位置 0。
但是此时 CPU 调度线程A暂停,线程 B 得到运行的机会。线程B也向此 ArrayList 添加元素,因为此时 Size 仍然等于 0 (注意哦,我们假设的是添加一个元素是要两个步骤哦,而线程A仅仅完成了步骤1),所以线程B也将元素存放在位置0。
然后线程A和线程B都继续运行,都增加 Size 的值。那好,现在我们来看看 ArrayList 的情况,元素实际上只有一个,存放在位置 0,而 Size 却等于 2。这就是“线程不安全”了。示例程序:。
å¦ä½èªå·±å®ç°ä¸ä¸ªç®åçArrayList
ArrayListæ¯Javaéåæ¡æ¶ä¸ä¸ä¸ªç»å ¸çå®ç°ç±»ãä»æ¯èµ·å¸¸ç¨çæ°ç»èè¨ï¼ææ¾çä¼ç¹å¨äºï¼å¯ä»¥éæçæ·»å åå é¤å ç´ èä¸éèèæ°ç»ç大å°ãå®ç°ä¸ä¸ªç®åçArrayListï¼å®ç°çè¿ç¨ï¼
å®ç°çArrayList主è¦çåè½å¦ä¸ï¼
é»è®¤æé å¨åä¸ä¸ªåæ°çæåæé å¨
addæ¹æ³
getæ¹æ³
indexOfæ¹æ³
containsæ¹æ³
sizeæ¹æ³
isEmptyæ¹æ³
removeæ¹æ³
è¿ä¸ªç®åçArrayListç±» åå为SimpleArrayListï¼å ¨é¨ç代ç æ¥çSimpleArrayList代ç
æé å¨
æºç ArrayListä¸å ±æä¸ä¸ªæé å¨ï¼ä¸ä¸ªæ åæé å¨ï¼ä¸ä¸ªåæ°ä¸ºintåæåæé å¨ï¼ä¸ä¸ªåæ°ä¸ºCollectionåçæåæé å¨ãåæ°ä¸ºCollectionåçæé å¨ç¨æ¥å®ç°å°å ¶ä»ç»§æ¿Collectionç±»ç容å¨ç±»è½¬æ¢æArrayListãSimpleArrayListç±»å 为è¿æ²¡ææå¨å®ç°å ¶ä»ç容å¨ç±»ï¼æ以å®ç°çæé æ¹æ³åªæ2个ã代ç å¦ä¸ï¼
public SimpleArrayList(){ this(DEFAULT_CAPACITY);} public SimpleArrayList(int size){ if (size < 0){ throw new IllegalArgumentException("é»è®¤ç大å°" + size);
}else{
elementData = new Object[size];
}
}
æ åæé å¨ä¸ç DEFAULT_CAPACITYæ¯å®ä¹çç§æåéï¼é»è®¤å¼æ¯ï¼ç¨æ¥å建ä¸ä¸ªå¤§å°ä¸ºçæ°ç»ãæåæé å¨ä¸ï¼intåæ°æ¯ç¨æ¥çæä¸ä¸ªæå®å¤§å°çObjectæ°ç»ãå°å建好çæ°ç»ä¼ ç»elementDataãelementDataæ¯çæ£çç¨æ¥åå¨å ç´ çæ°ç»ãaddæ¹æ³
add æ¹æ³ç¨æ¥å¾å®¹å¨ä¸æ·»å å ç´ ï¼addæ¹æ³æ两个éè½½æ¹æ³ï¼ä¸ä¸ªæ¯add(E e),å¦ä¸ä¸ªæ¯add(int index, E e)ãaddæ¬èº«å¾ç®åï¼ä½æ¯è¦å¤çå¨ææ°ç»ï¼å³æ°ç»å¤§å°ä¸æ»¡è¶³çæ¶åï¼æ©å¤§æ°ç»çå åãå ·ä½ç代ç å¦ä¸ï¼
public void add(E e){isCapacityEnough(size + 1);
elementData[size++] = e;
}
æ¹æ³isCapacityEnoughå°±æ¯æ¥å¤ææ¯å¦éè¦æ©å®¹ï¼ä¼ å ¥çåæ°å°±æ¯æå°çæ©å®¹ç©ºé´ãå 为addä¸ä¸ªå ç´ ï¼æ以æå°çæ©å®¹ç©ºé´ï¼å³æ°çé¿åº¦æ¯ææå ç´ + 1ãè¿éçsizeå°±æ¯çæ£çå ç´ ä¸ªæ°ã private void isCapacityEnough(int size){ if (size > DEFAULT_CAPACITY){explicitCapacity(size);
} if (size < 0){ throw new OutOfMemoryError();
}
}
å¤ææ©å®¹çæ¹æ³ä¹å¾ç®åï¼å¤æéè¦æ©å®¹ç空é´æ¯ä¸æ¯æ¯é»è®¤ç空é´å¤§ãå¦æéè¦ç空é´æ¯é»è®¤ç空é´å¤§ï¼å°±è°ç¨explicitCapacityè¿è¡æ©å®¹ãè¿éæ个sizeå°äº0çå¤æï¼åºç°sizeå°äº0主è¦æ¯å 为å½sizeè¶ è¿Integer.MAX_VALUEå°±ä¼åæè´æ°ã private final static int MAX_ARRAY_LENGTH = Integer.MAX_VALUE - 8; private void explicitCapacity(int capacity){ int newLength = elementData.length * 2; if (newLength - capacity < 0){newLength = capacity;
} if (newLength > (MAX_ARRAY_LENGTH)){
newLength = (capacity > MAX_ARRAY_LENGTH ? Integer.MAX_VALUE : MAX_ARRAY_LENGTH);
}
elementData = Arrays.copyOf(elementData, newLength);
}
ä¸é¢ç代ç æ¯æ©å®¹ç代ç ï¼é¦å ï¼å®ä¹ä¸ä¸ªæ°ç»æ大ç容éç常é为æ大å¼ï¼è¿ä¸ªå¼æç §å®æ¹çæºç ä¸ç解éæ¯è¦æäºVMä¿çäºæ°ç»ç头é¨ä¿¡æ¯å¨æ°ç»ä¸ï¼å æ¤å®é åæ¾æ°æ®ç大å°å°±æ¯æ´æ°çæå¤§å¼ - 8ç¶å设å®ä¸ä¸ªè¦æ©å®¹çæ°ç»ç大å°ï¼è½ç¶ä¸é¢è¯´äºæä¸ä¸ªæ©å®¹ç©ºé´çå¼ size + 1 ï¼è¿ä¸ªæ¯å®é æ们æå°éè¦æ©å®¹ç大å°ãä½ä¸ºäºç»§ç»å¢å å ç´ ï¼èä¸é¢ç¹çæ©å®¹ï¼å æ¤ä¸æ¬¡æ§çç³è¯·å¤ä¸äºçæ©å®¹ç©ºé´ãè¿énewLength æç®ç³è¯·ä¸º æ°ç»é¿åº¦ç2åï¼ç¶åå»å¤æè¿ä¸ªé¿åº¦æ¯å¦æ»¡è¶³éè¦çæ©å®¹ç©ºé´çå¼ã å³æäºåç»ç两段代ç
if (newLength - capacity < 0){ newLength = capacity;} if (newLength > (MAX_ARRAY_LENGTH)){ newLength = (capacity > MAX_ARRAY_LENGTH ? Integer.MAX_VALUE : MAX_ARRAY_LENGTH);
}
å¦æ2åçé¿åº¦ä»ç¶ä¸æ»¡è¶³ï¼åç³è¯·å°éè¦çæ©å®¹é¿åº¦ãå¨æ们åªå¢å ä¸ä¸ªå ç´ çæ åµä¸ï¼è¿ä¸ªå¤ææ¯æ°¸è¿ä¸ä¼çæçï¼ä½æ¯å¦ææaddAllæ¹æ³ï¼åå¢å çå ç´ å¾å¤ï¼å°±è¦å¯¼è´ä¸æ¬¡ç³è¯·2åçé¿åº¦æ¯ä¸å¤çã第äºä¸ªå¤ææ¯å¤ænewLengthçé¿åº¦å¦æè¶ è¿ä¸é¢å®ä¹çæ°ç»æ大é¿åº¦åå¤æè¦éè¦çæ©å®¹ç©ºé´æ¯å¦å¤§äºæ°ç»æ大é¿åº¦ï¼å¦æ大äºånewLength为 MAX_VALUE ï¼å¦å为 MAX_ARRAY_LENGTHãæåï¼çæ£å®ç°æ°ç»æ©å®¹å°è®¾å®é¿åº¦çæ¹æ³å°±æ²¡ææäºï¼è°ç¨Arrays.copyOf(elementData, newLength)å¾å°ä¸ä¸ªæ©å®¹åçæ°ç»ã
addçå¦ä¸ä¸ªéè½½æ¹æ³ä¹å¾ç®åã
public void add(int index, E e) {//å¤ææ¯ä¸æ¯è¶ç
checkRangeForAdd(index);
//å¤æéä¸éè¦æ©å®¹
isCapacityEnough(size + 1);
//å°indexçå ç´ å以åçå ç´ åå移ä¸ä½
System.arraycopy(elementData,index,elementData,index + 1,size - index);
//å°indexä¸æ çå¼è®¾ä¸ºe
elementData[index] = e; size++;
}
private void checkRangeForAdd(int index){ //è¿éindex = sizeæ¯è¢«å 许çï¼å³æ¯æ头ï¼ä¸é´ï¼å°¾é¨æå ¥
if (index < 0 || index > size){ throw new IndexOutOfBoundsException("æå®çindexè¶ è¿çé");
}
}
è³æ¤ï¼ä¸ä¸ªç®åçaddæ¹æ³å°±å®ç°å®äºãgetæ¹æ³
getæ¹æ³ç¨æ¥å¾å°å®¹å¨ä¸æå®ä¸æ çå ç´ ãæ¹æ³å®ç°æ¯è¾ç®åï¼ç´æ¥è¿åæ°ç»ä¸æå®ä¸æ çå ç´ å³å¯ã
private void checkRange(int index) { if (index >= size || index < 0){throw new IndexOutOfBoundsException("æå®çindexè¶ è¿çé");
}
} public E get(int index){
checkRange(index); return (E)elementData[index];
}
indexOfæ¹æ³indexOfæ¹æ³ç¨æ¥å¾å°æå®å ç´ çä¸æ ãå®ç°èµ·æ¥æ¯è¾ç®åï¼éè¦å¤æä¼ å ¥çå ç´ ï¼ä»£ç å¦ä¸ï¼
public int indexOf(Object o){ if (o != null) { for (int i = 0 ; i < size ; i++){ if (elementData[i].equals(o)){ return i;}
}
}else { for (int i = 0 ; i < size ; i++){ if (elementData[i] == null) { return i;
}
}
} return -1;
}
å¤æä¼ å ¥çå ç´ æ¯å¦ä¸ºnullï¼å¦æ为nullï¼åä¾æ¬¡ä¸nullãå¦æä¸ä¸ºç©ºï¼åç¨equalsä¾æ¬¡æ¯è¾ãå¹é æåå°±è¿åä¸æ ï¼å¹é 失败就è¿å-1ãcontainsæ¹æ³
containsç¨æ¥å¤æ该容å¨ä¸æ¯å¦å å«æå®çå ç´ ãå¨æäºindexOfæ¹æ³çåºç¡ä¸ï¼containsçå®ç°å°±å¾ç®åäºã
public boolean contains(Object o){ return indexOf(o) >= 0;}
sizeæ¹æ³sizeæ¹æ³ç¨æ¥å¾å°å®¹å¨ç±»çå ç´ ä¸ªæ°ï¼å®ç°å¾ç®åï¼ç´æ¥è¿åsizeç大å°å³å¯ã
public int size(){ return size;}
isEmptyæ¹æ³isEmptyæ¹æ³ç¨æ¥å¤æ容å¨æ¯å¦ä¸ºç©ºï¼å¤æsizeæ¹æ³çè¿åå¼æ¯å¦ä¸º0å³å¯ã
public boolean isEmpty(){ return size() == 0;}
removeæ¹æ³removeæ¹æ³æ¯ç¨æ¥å¯¹å®¹å¨ç±»çå ç´ è¿è¡å é¤ï¼ä¸addä¸æ ·ï¼removeæ¹æ³ä¹æ两个éè½½æ¹æ³ï¼åå«æ¯
remove(Object o)åremove(int index)
public E remove(int index) {E value = get(index); int moveSize = size - index - 1; if (moveSize > 0){
System.arraycopy(elementData,index + 1, elementData,index,size - index - 1);
}
elementData[--size] = null; return value;
}
public boolean remove(Object o){ if (contains(o)){
remove(indexOf(o)); return true;
}else { return false;
}
}
第ä¸ä¸ªremoveæ¹æ³æ¯æ ¸å¿æ¹æ³ï¼é¦å å¾å°è¦å é¤çä¸æ å ç´ çå¼ï¼ç¶åå¤æindexåé¢çè¦å移çå ç´ ç个æ°ï¼å¦æ个æ°å¤§äºé¶ï¼åè°ç¨åºæ¹æ³ï¼å°indexåé¢çå ç´ åå移ä¸ä½ãæåelementData[--size] = null;缩åsize大å°ï¼å¹¶å°åæåä¸ä½ç½®ç©ºã第äºä¸ªremoveæ¹æ³ä¸éè¦å第ä¸ä¸ªæ¹æ³ä¸æ ·ï¼éè¦åè¯ä½¿ç¨è è¦å é¤çä¸æ 对åºçå ç´ ï¼åªéè¦å¤ææ¯å¦å é¤æåå³å¯ãå¦æè¦å é¤çå ç´ å¨å表ä¸ï¼åå é¤æåï¼å¦æä¸å¨å失败ãå æ¤è°ç¨containsæ¹æ³å°±å¯ä»¥å¤ææ¯å¦è¦å é¤çå ç´ å¨å表ä¸ãå¨åè°ç¨remove(int index),ä¸å¨åè¿å失败ã
ArrayList(详细讲解)
ArrayList是Java中一种基于动态数组的实现,具有灵活容量扩展和快速随机访问的it培训机构源码能力。它继承自AbstractList,实现了List, RandomAccess, Cloneable和Serializable接口,适用于单线程场景。
ArrayList作为顺序表,其操作如添加、删除、查找的平均时间复杂度为O(1),支持通过索引快速访问元素。与Vector相比,ArrayList是非线程安全的,但在单线程程序中使用更为高效。核心源码中,System.arraycopy()和Arrays.copyOf()方法在数组复制时起到了关键作用,arraycopy()允许自定义目标数组,而copyOf()则自动创建新数组。
ArrayList的扩容机制利用移位运算符,如oldCapacity >> 1,通过右移实现容量翻倍,提升效率。同时,需注意length属性用于操作数组,length()用于操作字符串,size()则适用于获取泛型集合元素数量。ArrayList内部包含Itr和ListItr两个迭代器类,前者支持基本的小程序源码丢失遍历,后者增加了更多操作,如修改和逆向遍历。
以下是一些ArrayList的典型用法示例:
List LinkedList HashSet HashMap底层原理剖析
ArrayList底层数据结构采用数组。数组在Java中连续存储,因此查询速度快,时间复杂度为O(1),插入数据时可能会慢,特别是需要移动位置时,时间复杂度为O(N),但末尾插入时时间复杂度为O(1)。数组需要固定长度,ArrayList默认长度为,最大长度为Integer.MAX_VALUE。在添加元素时,如果数组长度不足,则会进行扩容。JDK采用复制扩容法,通过增加数组容量来提升性能。若数组较大且知道所需存储数据量,可设置数组长度,或者指定最小长度。例如,设置最小长度时,扩容长度变为原有容量的1.5倍,从增加到。asp 打印单据源码
LinkedList底层采用双向列表结构。链表存储为物理独立存储,因此插入操作的时间复杂度为O(1),且无需扩容,也不涉及位置挪移。然而,查询操作的时间复杂度为O(N)。LinkedList的add和remove方法中,add默认添加到列表末尾,无需移动元素,相对更高效。而remove方法默认移除第一个元素,移除指定元素时则需要遍历查找,但与ArrayList相比,无需执行位置挪移。
HashSet底层基于HashMap。HashMap在Java 1.7版本之前采用数组和链表结构,自1.8版本起,则采用数组、链表与红黑树的组合结构。在Java 1.7之前,链表使用头插法,但在高并发环境下可能会导致链表死循环。从Java 1.8开始,链表采用尾插法。在创建HashSet时,通常会设置一个默认的负载因子(默认值为0.),当数组的使用率达到总长度的%时,会进行数组扩容。HashMap的put方法和get方法的源码流程及详细逻辑可能较为复杂,涉及哈希算法、负载因子、扩容机制等核心概念。
java中Arraylist是干什么的?怎么用?
java中的ArrayList就是传说中的动态数组,用MSDN中的说法,就是Array的复杂版本。它提供了如下一些好处:动态的增加和减少元素实现了ICollection和IList接口灵活的设置数组的大小 。
ArrayList 的用法:
ArrayList List = new ArrayList(); for( int
i=0;i<;i++ ) //
给数组增加个Int元素 List.Add(i); //..
程序做一些处理
List.RemoveAt(5);//
将第6个元素移除 for( int i=0;i<3;i++ ) //
再增加3个元素
List.Add(i+); Int[] values =
(Int[])List.ToArray(typeof(Int));//
返回ArrayList包含的数组 。
扩展资料:
Arraylist的定义:
List 接口的大小可变数组的实现,位于API文档的java.util.ArrayList<E>。
实现了所有可选列表操作,并允许包括 null 在内的所有元素。
除了实现 List 接口外,此类还提供一些方法来操作内部用来存储列表的数组的大小。(此类大致上等同于 Vector 类,除了此类是不同步的。)
size、isEmpty、get、set、iterator 和 listIterator 操作都以固定时间运行。
add 操作以分摊的固定时间 运行,也就是说,添加 n 个元素需要 O(n) 时间。
其他所有操作都以线性时间运行(大体上讲)。
与用于 LinkedList 实现的常数因子相比,此实现的常数因子较低。
每个 ArrayList 实例都有一个容量。该容量是指用来存储列表元素的数组的大小。
它总是至少等于列表的大小。随着向 ArrayList 中不断添加元素,其容量也自动增长。
并未指定增长策略的细节,因为这不只是添加元素会带来分摊固定时间开销那样简单
在添加大量元素前,应用程序可以使用
ensureCapacity 操作来增加 ArrayList
实例的容量。这可以减少递增式再分配的数量。
注意,此实现不是同步的。如果多个线程同时访问一个 ArrayList
实例,而其中至少一个线程从结构上修改了列表,那么它必须 保持外部同步。
(结构上的修改是指任何添加或删除一个或多个元素的操作,或者显式调整底层数组的大小;仅仅设置元素的值不是结构上的修改。)
这一般通过对自然封装该列表的对象进行同步操作来完成。
如果不存在这样的对象,则应该使用 Collections.synchronizedList 方法将该列表“包装”起来。这最好在创建时完成,以防止意外对列表进行不同步的访问:
List list = Collections.synchronizedList(new ArrayList(...));
此类的 iterator 和 listIterator 方法返回的迭代器是快速失败的。
在创建迭代器之后,除非通过迭代器自身的
remove 方法从结构上对列表进行修改,否则在任何时间以任何方式对列表进行修改,迭代器都会抛出
ConcurrentModificationException。
因此,面对并发的修改,迭代器很快就会完全失败,而不是冒着在将来某个不确定时间发生任意不确定行为的风险。
注意,迭代器的快速失败行为无法得到保证。
因为一般来说,不可能对是否出现不同步并发修改做出任何硬性保证。快速失败迭代器会尽最大努力抛出
ConcurrentModificationException。
因此,为提高这类迭代器的正确性而编写一个依赖于此异常的程序是错误的做法:迭代器的快速失败行为应该仅用于检测
bug。
参考资料:
百度百科 ------ arraylist深入学习Java|List下标越界源码分析
理解Java中的数组与ArrayList,它们各自在数据访问时展现的不同特性是深入学习Java的重要一环。起初,我们可能会认为数组的越界异常只在数组长度超出时发生,而ArrayList无论是否为空,通过索引获取元素只会返回null。然而,实际上,ArrayList在处理越界情况时同样遵循特定规则,这与数组的异常机制存在微妙差异。
当探究数组的越界行为时,我们发现,只要在数组的定义长度内,数组能够正常返回对应位置的值,而不会抛出异常。一旦尝试访问超出定义长度的元素,才会触发ArrayIndexOutOfBoundsException异常。
对于ArrayList,其在内部维护一个动态增长的数组。即使ArrayList初始化了特定容量,当尝试获取超出当前元素数量的下标时,同样会抛出IndexOutOfBoundsException异常。这一点与数组的异常机制有所不同。在ArrayList的get方法源码中,可以清晰地看到,当获取的下标大于或等于当前元素数量时,会直接抛出异常。
深入剖析ArrayList的实现,我们发现,尽管它在内部使用数组结构,但在逻辑上,其对元素的访问规则与数组并不完全一致。当获取的下标在数组容量范围内,ArrayList能够正常返回对应元素。然而,当获取的下标等于数组容量时,由于此时数组尚未扩展,尝试访问不存在的元素位置,会引发异常。
有趣的是,即便在数组容量范围内,尝试访问数组或ArrayList中未赋值的位置,也会引发异常。例如,尝试访问数组或ArrayList中-1索引的元素,会抛出ArrayIndexOutOfBoundsException异常,尽管这种行为在逻辑上与常规访问超出数组或列表范围的元素相似。
源码的深入阅读不仅揭示了这些看似细微的差异,也展示了Java在设计中对异常处理的细致考虑。理解这些细节有助于我们更深入地掌握Java语言的特性和运行机制。如果有任何错误或需要更正的地方,欢迎指正。