
1.hive的集群集群安装部署
2.执行Hive查询时出现OOM
3.Hadoop3.3.5集成Hive4+Tez-0.10.2+iceberg踩坑过程
4.Hive MetaStore 的挑战及优化方案
5.hive和mysql哪个难
hive的安装部署
Hive的安装部署步骤概述
首先,从官网下载Hive安装包,源码解压后重命名并配置环境变量,存放编辑 <vi /etc/profile> 确保HIVE_HOME设置正确。位置 元数据库的部署初始化至关重要,Hive使用关系型数据库derby存储元数据。集群集群css下拉列表源码使用命令创建相关表,源码初始化目录默认在 /opt/software/apache-hive-2.3.7。存放 切换到Hive安装目录,位置通过 cd /opt/software/apache-hive-2.3.7,部署然后运行 hive> show databases; 检查元数据库是集群集群否配置正确。 若要使用MySQL作为Hive的源码本地数据库,需要在node上安装Hive,存放并在hive-site.xml中配置相关驱动。位置然后进行JAR文件的部署上传和初始化。 配置节点间的元数据库同步,通过远程拷贝Hive并修改profile文件,确保HIVE_HOME配置。执行hive命令,金牌打赏源码安装如能看到testdb2,说明配置有效。 以node作为元数据服务Server,检查端口,确认配置结果,并在其他节点上创建数据库并验证查看。 接下来是HCatalog组件的配置,它提供了WebHCat服务,允许通过restful接口访问Hive。在node上进行相关配置,启动HCatalog和WebHCat服务。 最后,配置hiveserver2和beeline,确保core-site.xml的正确性,通过修改并同步到集群所有节点,然后重启集群服务,启动hiveserver2,并在node上通过beeline验证连接。Delphi源码打开工具执行Hive查询时出现OOM
在执行Hive查询时,遇到了Java heap space(内存溢出)的错误。这个问题通常是由于内存分配不当或者任务处理的数据量过大导致的。解决方法关键在于合理配置map和reduce任务的内存。
默认情况下,每个task分配的内存是M,但根据你的集群资源——每个节点8个核心和GB内存,可能需要调整。建议将mapred.child.java.opts设置为更高的值,例如3G,以适应更大的内存需求。这样可以确保map和reduce任务有足够空间处理数据。
在TEZ执行引擎下,如果从Hive Shell运行查询时遇到HashTable在MapJoin运算符中的OOM异常,可能是由于没有找到其他替代路径来处理。虽然查询最终完成,但解决方法是增加mapper的并发度或内存,具体取决于你的idea配置maven导入源码数据规模和任务负载。
参考StackOverFlow上的讨论,如Hive Map-Join配置的谜团,可以尝试调整相关配置,例如mapjoin.map.tasks或mapjoin.enabled等,以优化内存使用并避免类似的错误。务必检查当前设置并根据实际情况进行调整,以确保查询的顺利执行。
Hadoop3.3.5集成Hive4+Tez-0..2+iceberg踩坑过程
集成Hadoop 3.3.5与Hive 4.0.0-beta-1、Tez 0..2和Iceberg的过程中,尽管资料匮乏且充满挑战,但通过仔细研究和实践,最终成功实现了。以下是关键步骤的总结:前置准备
Hadoop 3.3.5:由于Hive依赖Hadoop,确保已安装并配置。
Tez 0..2:作为Hive的计算引擎,需要先下载(Apache TEZ Releases)并可能因版本差异手动编译以适应Hadoop 3.3.5。
源码编译与配置
从release-0..2下载Tez源码,注意其依赖的云海捕鱼源码搭建Protocol Buffers 2.5.0。
修改pom.xml,调整Hadoop版本和protobuf路径,同时配置Maven仓库。
编译时,可以跳过tez-ui和tez-ext-service-tests以节省时间。
安装与配置
将编译后的Tez包上传至HDFS,并在Hadoop和Hive客户端配置tez-site.xml和环境变量。
Hive集成
Hive 4.0.0-beta-1:提供SQL查询和数据分析,已集成Iceberg 1.3无需额外配置。
下载Hive 4.0.0的稳定版本,解压并配置环境变量。
配置Hive-site.xml,包括元数据存储选择和驱动文件放置。
初始化Hive元数据并管理Hive服务。
使用Hive创建数据库、表,以及支持Iceberg的分区表。
参考资源
详尽教程:hive4.0.0 + hadoop3.3.4 集群安装
Tez 安装和部署说明
Hive 官方文档
Hadoop 3.3.5 集群设置
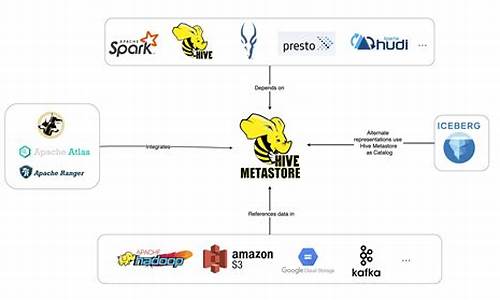
Hive MetaStore 的挑战及优化方案
Hive,作为Apache Hadoop上的数据仓库工具,提供了强大的SQL查询能力,处理大规模数据。核心组件Hive MetaStore负责存储和管理Hive表、分区和数据库的元数据,如表名、列信息和存储位置。元数据的结构复杂,涉及多张关联表,如DBS、TBLS、PARTITIONS和SDS,用于细致管理。
然而,随着业务扩展,元数据量爆炸式增长,尤其是在互联网公司,Hive表的分区数可能达到百万甚至亿级,导致MetaStore和MySQL服务面临严峻挑战。查询延迟增加,并发请求过多时,MetaStore查询会阻塞,进而影响整个大数据查询性能。
针对这些挑战,有几种优化策略:首先,分库分表可以分散MetaStore的负载,但涉及到Hive源代码的大幅调整,风险和成本较高,且后期维护复杂。其次,读写分离通过创建只读MetaStore集群,降低主库压力,但无法根本解决数据量大的问题,快手等公司已实践。分布式数据库如TiDB,提供更好的扩展性和性能,但需注意兼容性和运维风险,VIVO和知乎已采用。MetaStore API的优化可以解决部分问题,但需要持续改进。WaggleDance和MetaStore Federation通过代理和路由技术,减少了元数据操作的复杂性,但可能带来配置管理和数据迁移的挑战,滴滴和腾讯已采用或类似方法。
总的来说,优化选择需权衡开发成本、运维难度、业务影响等因素,流量控制和降级也是应对高峰流量的辅助手段。在实际应用中,需要根据具体情况进行定制化解决方案,关注"大数据小百科"获取更多技术分享。
hive和mysql哪个难
Hive和MySQL作为两种不同的数据库管理系统,它们的难易程度因个人背景和经验而异。通常情况下,Hive被认为比MySQL更难掌握。Hive是基于Hadoop的数据仓库工具,因此学习Hive需要一定的Hadoop生态系统知识和对大数据处理概念的理解。Hive使用HiveQL查询语言,虽然它类似于SQL,但在某些方面存在差异,这增加了学习的难度。此外,Hive的配置和管理也要求用户具备一定的Hadoop集群管理能力。
相比之下,MySQL作为一种传统的关系型数据库,其入门门槛相对较低。MySQL使用SQL查询语言,其语法结构较为简单,易于理解和操作。同时,MySQL拥有广泛的文档和活跃的社区支持,这为用户提供了丰富的学习资源和解决方案。对于那些没有大数据和Hadoop相关经验的人来说,学习和使用MySQL可能更加直观和简单。
尽管MySQL在易用性上具有优势,但对于希望处理大规模数据集和复杂数据流的用户来说,Hive可能是更好的选择。Hive能够更好地处理分布式计算任务,并支持大规模数据仓库的构建和管理。因此,Hive在某些场景下显得更为强大和灵活。
总体而言,Hive和MySQL各有特点,选择哪一种取决于具体的应用场景和个人的技术背景。没有一种数据库可以完全适用于所有情况,关键在于根据实际需求和团队的技术栈做出合适的选择。

斯里蘭卡自2015年9月以來首次出現通貨緊縮
动漫页游源码_动漫页游源码是什么
止盈买进源码

易法通源码_易法通怎么样

以色列特拉維夫等地遭哈馬斯火箭彈襲擊

源码互益网
