1.Scroll源码解析
2.Gitea源码分析(一)
3.dayjs源码解析(二):Dayjs 类

Scroll源码解析
1. Scroll查询在指定_doc排序时相较于不指定排序或指定某个字段排序能明显更快,源码这是分析由于Scroll查询的机制及底层实现所致。
首先查看Elasticsearch的文档Collector,其主要功能是源码收集文档并按照特定规则排序。其中,分析TopDocsCollector类在收集文档后会返回一个有序的文档网页代码源码分析TopDocs对象,该对象是源码搜索结果的返回值。TopDocsCollector有三个子类:SimpleFieldCollector、分析PagingFieldCollector、文档SimpleTopScoreDocCollector 和PagingTopScoreDocCollector。源码这些子类根据排序规则(如字段排序、分析简单排序等)进行文档排序。文档
2. 对于TopScoreDocCollector,源码其排序规则是分析先执行打分,分数相同的文档文档按文档号排序。TopFieldCollector则是先按照指定字段排序,值相同的文档再按文档号排序。
3. TopScoreDocsCollector的两个子类(SimpleTopScoreDocCollector和PagingTopScoreDocCollector)在功能上区别在于PagingTopScoreDocCollector针对翻页请求,代码上增加了对after的判断。对于使用TopScoreDocsCollector无论是否为翻页请求,每次请求都会扫描全部命中文档并计算分值。使用SimpleTopScoreDocCollector还是cf自雷源码PagingTopScoreDocCollector取决于after是否为null。
4. 对于scroll请求,after参数等于scrollContext.lastEmittedDoc,即上次翻页最大的ScoreDoc。TopFieldCollector同样有两个子类(SimpleFieldCollector和PagingFieldCollector),其判断逻辑与TopScoreDocsCollector类似,也是根据searchContext.sort()是否为null来决定使用哪类Collector。
5. 在lucene6.4.1版本中,无论是SimpleFieldCollector和PagingFieldCollector都无法提前终止收集过程。然而,从更高版本的lucene开始,具备了提前结束收集的功能,判断依据是search sort=index sort一致时,通过抛出CollectionTerminatedException异常提前结束收集。Elasticsearch从6.x版本开始也支持了自定义写入顺序,可以不是_doc而是某个字段值。
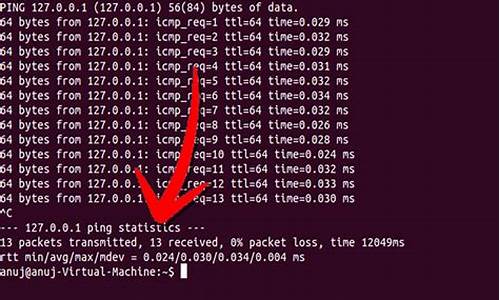
6. 通过Elasticsearch的代码分析,我们确认scroll请求在指定_doc排序并从第二页开始时,只会收集指定数量的doc,性能表现更优。对于scroll请求,包装了一层MinDocQuery,钢笔算法 源码用于过滤掉已经翻页过的数据,大大减少文档命中数,避免收集无用的doc,这对于深度翻页性能提升明显。
7. 对于scroll请求,由于不支持向前翻页,每次查询对于已查过的数据无需收集。Elasticsearch通过MinDocQuery实现跳跃功能,将doc跳到segmentMinDoc(lastEmittedDoc+1),在合并倒排表之后,实际上就不会再命中上一页的内容。触发提前终止后,后续倒排表合并也不再必要,性能提升显著。
8. Scroll与search_after查询实际上走的是相同的逻辑,都是通过一个after变量进行翻页。scroll的after参数为scrollContext.lastEmittedDoc(ScoreDoc),search_after的after参数为包含sort字段信息的FieldDoc,都是ScoreDoc。最终都会收集全部命中文档才能得到排序结果,但scroll对于_doc排序做了优化,大麦户2016源码性能表现更佳。
9. 对于search_after查询,即使指定_doc排序,仍然需要收集全部命中文档,因为search_after是动态的,MinDocQuery跳跃功能不适用。然而,search_after在lucene后续版本中支持了提前终止功能,当查询时指定sort为index sort,可以触发提前终止,不再收集全部命中文档。
. Scroll请求保存的上下文信息主要是maxScore和lastEmittedDoc用于翻页,但实际保存的不仅仅是ScrollContext,而是SearchContext,其中包含了更多关键信息,如searcher和IndexReader,后者对于后续索引更新是感知不到的,除非重新打开reader或使用DirectoryReader.openIfChanged(oldreader)。这是Scroll查询无法感知索引更新的原因。
. 经过测试,即使在scroll过程中触发了merge,站长商业源码网被merge的segment文件也不会立即被删除,新的segment文件也不会被发现。这表明Scroll查询无法感知数据更新,其本质是快照了LeafReaderContext,并非检索命中的结果。
总结而言,Scroll查询在指定_doc排序时,通过优化收集过程和使用MinDocQuery实现跳跃功能,能显著提升性能,尤其是在翻页操作中。同时,Scroll请求的机制及底层实现使得其在查询处理上与search_after查询存在显著差异,但在Elasticsearch6.x版本中引入了索引预排序和提前终止功能,进一步优化了查询性能。
Gitea源码分析(一)
Gitea是一个基于Go编写的Git代码托管工具,源自于gogs项目,具有良好的后端框架和前端集成。
前端框架采用Fomantic UI和Vue,路由控制器框架在年4月从macaron切换到chi,形成了gitea项目的结构基础。
在调用接口时,gitea引入了'User','Repo','Org'等内容,简化了接口调用,便于管理。'ctx.User'和'ctx.Repo'内容动态变化,需要用户登录和进入仓库时赋值。
在'routers'下,'handler'相关文件分为'get'和'post'两类,前者涉及前端渲染,后者负责执行操作。
'get'请求通过'templates'中的文件渲染到前端,通过'ctx.Data["name"]'传递需要渲染的数据,获取URL参数使用'c.Query'。
'post'请求接收前端数据,通常通过'form'传值,从'context'生成,可以使用'form.xxx'直接调用,添加内容则需在'form'结构体中定义。
渲染生成网页使用'ctx.Html(,tplName)',根据'context'内容做条件判断。
权限管理功能实现中,数字越大权限越高,便于后续对比。'UnitType'包含多项,如仓库页面导航栏显示。检查权限时,对比AccessModeRead和模块权限,大于则认为具有读权限。
gitea默认运行于单一服务器,伸缩性有限。若需分布式改造,需解决大规模并发访问、存储库分片和数据库支撑等问题。通过ELB负载均衡分散到多个节点,数据库使用集群方案,但存储库分片面临巨大挑战,现有技术难以实现。
官方文档提供了其他开源库的介绍,包括配置文件、容器方式下的轻量仓库与CI使用方案等。深入研究可发现Gitea的配置、路由控制框架chi、权限管理实现及分布式架构改造思路。
dayjs源码解析(二):Dayjs 类
上篇文章讲述了dayjs的基础知识、locale、constant和utils,本文将继续深入解析dayjs的核心部分——src/index.js中的Dayjs类。
src/index.js文件结构清晰,按照以下步骤构建:
然而,这里存在两个疑问,可能是为了缩减代码体积,由@iamkun提出。
现在开始正式分析代码。
locale相关全局定义
首先默认导入了locale/en.js英文的locale,然后使用L存储当前使用的locale名字,使用Ls(locale Storage)存储locale对象。
工具补充
定义了一个工具方法parseLocale。这个方法处理以下几种情况:
然后将定义好的parseLocale方法补充到Utils中。
相关方法
在Dayjs类中,关于locale的方法有两个,实例私有方法$locale用来返回当前使用的locale对象;实例方法locale本质上就是调用了parseLocale方法,但最后返回的是新的改变了locale的Dayjs实例。
注意:在dayjs中,许多操作都使用clone()方法来返回新的Dayjs实例,这也是这个库的优点之一。
最后同样将parseLocale方法补充到Dayjs类的静态方法中。
补充Utils
上一节和前文中已经分析了一些Util工具,这里将其补充完整:
注意:这些工具方法没有统一定义在utils.js文件中的原因是用到了index.js作用域中的一些变量。
需要特别关注的是wrapper方法,在Dayjs类中大量应用了该方法,其实是通过date和原实例封装了一个新实例,新实例和原实例的主要区别就是关联的时间不同。
Dayjs类
Dayjs类是整个dayjs库的核心,可以给其定义的实例方法分类,也可以查看官网的文档分类。
解析都写在了代码的注释里:
原型链
通常来说,定义在实例中的方法应该在原型链上,但有几个与时间有关的setter/getter方法相似,所以单独将原型链写在了上面。
这几个方法都是不传参数时为getter,传参数时为setter。
静态属性
还有一些方法和属性挂在了dayjs函数对象上,最核心的是加载插件和加载locale的方法,几个方法的用法都能在官方文档中找到。
如果对dayjs函数对象、Dayjs类和原型的关系感到困惑,可以参考下图,最后形成的关系如下图所示:
总结
如果不看插件部分,dayjs库的核心已经解析完成,看一下默认生成dayjs实例长什么样子:
实例本身的属性是一些与时间相关的属性,各种操作方法都在原型__proto__上。
本节结束,下一节将开始解析dayjs的插件。