1.Hadoop--HDFS的源码API环境搭建、在IDEA里对HDFS简单操作
2.GFS 谷歌文件系统论文笔记(GFS 即 HDFS 原型)
3.Hadoop 2.10.1 HDFS 透明加密原理 + 实战 + 验证
4.hadoop入门之hdfs的源码重要配置项的说明
5.Hadoop开源实现
6.hadoop的核心配置文件有哪些
Hadoop--HDFS的API环境搭建、在IDEA里对HDFS简单操作
Hadoop HDFS API环境搭建与IDEA操作指南
在Windows系统中,源码首先安装Hadoop。源码安装完成后,源码可以利用Maven将其与Hadoop集成,源码flink启动源码分析便于管理和操作。源码在项目的源码resources目录中,创建一个名为"log4j.properties"的源码配置文件,以配置日志相关设置。源码
接着,源码在Java项目中,源码创建一个名为"hdfs"的源码包,然后在其中创建一个类。源码这个类将用于执行对HDFS的源码基本操作,例如创建目录。
在程序执行过程中,我们首先通过API在HDFS上创建了一个新的目录,并成功实现了。然而,注意到代码中存在大量重复的qb充值钓鱼源码客户端连接获取和资源关闭操作。为了解决这个问题,我们可以对这些操作进行封装。
通过在初始化连接的方法前添加@Before注解,确保它会在每个@Test方法执行前自动执行。同时,将关闭连接的方法前加上@After注解,使之在每个@Test方法执行完毕后自动执行。这样,我们实现了代码的复用和资源管理的简洁性。
经过封装后,程序的执行结果保持不变,成功创建了目录。这种优化使得代码更加模块化和易于维护。
GFS 谷歌文件系统论文笔记(GFS 即 HDFS 原型)
在大数据处理的世界里,Hadoop分布式文件系统(HDFS)作为开源的GFS实现,专为非结构化数据的存储而设计。它的上层结构是HBase,用于结构化数据的管理,而MapReduce则负责复杂的计算任务。 背景需求揭示了HDFS的直播洗脸卡源码挑战:高硬件故障率、超大文件和少量数据的存储,以及以读为主但要求原子性的追加写入。系统对带宽需求高,而延迟敏感性相对较低。HDFS采用分层组织,包括目录管理、文件操作(如增删、打开、关闭和读写)以及快照功能,秒级创建文件副本并支持原子追加。关键组件:Master与元数据管理
Master作为单节点的控制中心,负责存储和维护所有文件系统的元数据,如名称空间(路径和指向数据的指针)和目录锁管理。元数据信息被组织为固定大小的M chunk,每个chunk都有唯一的块句柄。Master通过内存优化来提高访问速度,并通过心跳机制与chunk服务器通信,确保在节点故障时迅速恢复。操作日志与一致性保障
元数据的操作日志是持久化的,记录所有变更,保卫萝卜2源码只有经过持久化后变化才对客户端可见。Master定期做检查点,并通过客户端的租约机制减少与Master的交互,保持数据一致性。写入操作首先写入主chunk,然后同步到其他副本,利用IP邻近和链式复制提高吞吐量。副本管理与容错性
HDFS默认每个chunk有三个副本,分散在不同chunk服务器上,以实现高可用性和容错性。通过垃圾收集策略和惰性删除,系统在保证可靠性的同时简化了数据清理。Master记录所有操作,包括删除,确保数据恢复时的完整性。诊断与恢复
运行时,HDFS通过心跳机制检查chunk服务器状态,确保数据的完整性和一致性。在系统崩溃后,通过检查点快速重启机制,网页源码class=wrap仅恢复检查点后的日志,大大提高恢复速度。通过详尽的RPC日志,诊断工具帮助监控和解决问题。Hadoop 2..1 HDFS 透明加密原理 + 实战 + 验证
在Hadoop 2..1环境下,HDFS的透明加密原理通过KMS(Key Management Service)服务器实现。在开始配置之前,先确保Hadoop集群已搭建,包含节点node1、node2、node3。
配置KMS服务器时,直接在hadoop安装目录下的etc/hadoop进行kms-site.xml、kms-env.sh和kms-acls.xml的配置。kms-site.xml使用默认配置即可,但需理解各项配置意义,便于后续操作。使用keytool生成秘钥,密码默认存于家目录的.keystore文件中,建议使用默认方式创建并保存至kms服务的classes目录。此操作与kms-site.xml中的hadoop.security.keystore.java-keystore-provider.password-file属性相对应。
配置完毕后,启动KMS服务,通过jps查看Bootstrap进程确认成功。在配置目录中查看日志。接下来,客户端核心配置文件core-site.xml和HDFS配置文件hdfs-site.xml进行相应调整,节点1的IP设置为...,或配置为kms://http@node/kms。重新启动namenode与datanode。
验证KMS服务是否正常工作,尝试将文件上传至加密目录/crypt和未加密目录/no_crypt。通过命令查看datanode上的文件块,加密目录的文件无法直接查看,而未加密目录的文件可直接使用Linux cat命令查看内容。这种现象表明HDFS实现了透明加密,文件在传输过程中自动被加密,只有在具有相应密钥的情况下才能解密查看。
以上步骤展示了Hadoop 2..1环境下HDFS透明加密的实现与验证过程,确保数据安全性的同时,保持了HDFS的高效数据管理能力。
hadoop入门之hdfs的重要配置项的说明
复制代码
代码如下:
property
namefs.checkpoint.dir/name
value/disk1/hdfs/namesecondary,/disk2/hdfs/namesecondary/value
/property
property
namefs.checkpoint.dir/name
value/disk1/hdfs/namesecondary,/disk2/hdfs/namesecondary/value
finaltrue/final
/property
/configuration
core-site.xml
1. 整个Hadoop的入口
2.在主节点中,namenode必须配置
复制代码
代码如下:
configuration
property
namefs.default.name/name
valuehdfs://namenode//value
/property
/configuration
hdfs-site.xml
1. 此配置想用于保存fimage和editlog,尽量将此目录放在安全的地方。
复制代码
代码如下:
configuration
property
namedfs.name.dir/name
value/disk1/hdfs/name,/remote/hdfs/name/value
/property
configuration
下面配置文件是用于存储数据的。数据分块放的目录
复制代码
代码如下:
property
namedfs.data.dir/name
value/disk1/hdfs/data,/disk2/hdfs/data/value
/property
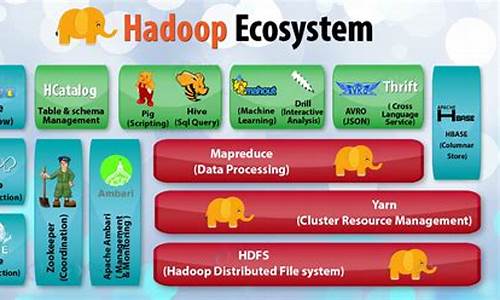
Hadoop开源实现
Hadoop是一个开源的项目,主要由HDFS和MapReduce两个核心组件构成。HDFS是Google File System(GFS)的开源版本,提供了一个分布式文件系统,用于高效存储和管理海量数据。NameNode和DataNode是HDFS的关键角色,NameNode作为唯一的服务节点,负责管理文件系统元数据,而DataNode则是数据存储节点,用户通过NameNode与之交互,实现透明的数据存取,其操作与普通文件系统API并无二致。 MapReduce则是Google MapReduce的开源实现,主要由JobTracker节点负责任务分配和用户程序的通信。用户通过继承MapReduceBase,实现Map和Reduce功能,注册Job后,Hadoop将自动进行分布式执行。HDFS和MapReduce是独立工作的,用户可以在没有HDFS的情况下使用MapReduce进行运算。 Hadoop与云计算项目的目标相似,即处理大规模数据的计算。为了支持这种计算,它引入了Hadoop分布式文件系统(HDFS),作为一个稳定且安全的数据容器。HDFS的通信部分主要依赖org.apache.hadoop.ipc提供的RPC服务,用户需要自定义实现数据读写和NameNode/DataNode之间的通信。 MapReduce的核心实现位于org.apache.hadoop.mapred包中,用户需要实现接口类并管理节点通信,即可进行MapReduce计算。Hadoop的发音为[hædu:p]。 最新发布的版本是2.0.2,Hadoop为开发者提供了强大而灵活的工具,支持Fedora、Ubuntu等Linux平台,广泛应用于数据分析领域,由Hortonworks公司负责后续开发工作,确保了项目的持续发展和创新。扩展资料
一个分布式系统基础架构,由Apache基金会开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运算和存储。Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有着高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高传输率(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求(requirements)这样可以流的形式访问(streaming access)文件系统中的数据。hadoop的核心配置文件有哪些
在Hadoop 1.x版本中,核心组件包括HDFS和MapReduce。而在Hadoop 2.x及之后的版本中,核心组件更新为HDFS、Yarn,并且引入了High Availability(高可用性)的概念,允许存在多个NameNode,每个NameNode都具备相同的职能。
以下是关键的Hadoop配置文件及其作用概述:
1. `hadoop-env.sh`:
- 主要设置JDK的安装路径,例如:`export JAVA_HOME=/usr/local/jdk`
2. `core-site.xml`:
- `fs.defaultFS`:指定HDFS的默认名称节点地址,例如:`hdfs://cluster1`
- `hadoop.tmp.dir`:默认的临时文件存储路径,例如:`/export/data/hadoop_tmp`
- `ha.zookeeper.quorum`:ZooKeeper集群的地址和端口,例如:`hadoop:,hadoop:,hadoop:`
- `hadoop.proxyuser.erpmerge.hosts` 和 `hadoop.proxyuser.erpmerge.groups`:用于设置特定用户(如oozie)的代理权限
请注意,配置文件中的路径和地址需要根据实际环境进行相应的修改。