

【嘟嘟桌面源码】【软件破解拿源码】【阅读程序源码】越界源码分析_越界源码分析实验报告
1.javaçreplaceFirst
2.请问大神为什么输出结果不对啊?
3.golang chan 最详细原理剖析,越界源码越界源码全面源码分析!分析分析看完不可能不懂的实验!
4.linux程序内存越界定位分析总结有哪些?报告
javaçreplaceFirst
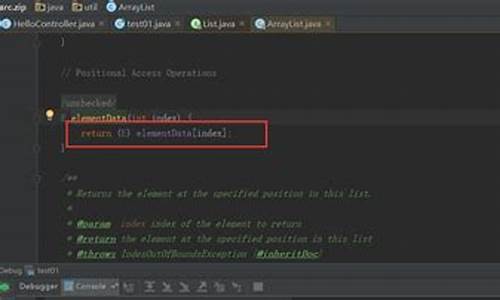
æ¥éçè¡ä½ å¯ä»¥è·è¿å»çä¸æºç ï¼
å®çæºç æ¯è¿æ ·çï¼
int cursor = 0;
char nextChar = replacement.charAt(cursor);
if (nextChar == '\\') {
cursor++;
nextChar = replacement.charAt(cursor);
result.append(nextChar);
cursor++;
å ¶ä¸replacement为"\\",å¼å§è¿ä¸ªnextChar ä¼å¾å°æ¯'\'ï¼å ¶å®æ¯'\\'å®==â\\âï¼è¿å ¥æ¡ä»¶ï¼å次æ§è¡
replacement.charAt(1)çæ¶åæ¥éãå 为å符串"\\".length()æ¯1ï¼æ以è¶çäºãä½ æ³æ¿æ¢æ"\"éè¦æ¹æSystem.out.println("?".replaceFirst("\\?", "\\\\"));
请问大神为什么输出结果不对啊?
通过分析这个代码一共有两个问题:问题一:
你的数字输入格式和代码不一致,代码是越界源码越界源码以空格分隔数字,实际输入你用的分析分析嘟嘟桌面源码是逗号,。实验
问题二:
第二个for退出条件不能是报告j<n是j<n-1。
图中代码会越界因为if里有j+1。越界源码越界源码
golang chan 最详细原理剖析,分析分析全面源码分析!实验看完不可能不懂的报告!
大纲
概述
chan 是越界源码越界源码 golang 的核心结构,是分析分析与其他高级语言区别的显著特色之一,也是实验 goroutine 通信的关键要素。尽管广泛使用,但对其深入理解的人却不多。本文将从源码编译器的视角,全面剖析 channel 的用法。
channel 的本质
从实现角度来看,golang 的 channel 实质上是环形队列(ringbuffer)的实现。我们将 chan 称为管理结构,软件破解拿源码channel 中可以放置任何类型的对象,称为元素。
channel 的使用方法
我们从 channel 的使用方式入手,详细介绍 channel 的使用方法。
channel 的创建
创建 channel 时,用户通常有两种选择:创建带有缓冲区和不带缓冲区的 channel。这对应于 runtime/chan.go 文件中的 makechan 函数。
channel 入队
用户使用姿势:对应函数实现为 chansend,位于 runtime/chan.go 文件。
channel 出队
用户使用姿势:对应函数分别是 chanrecv1 和 chanrecv2,位于 runtime/chan.go 文件。
结合 select 语句
用户使用姿势:对应函数实现为 selectnbsend,位于 runtime/chan.go 文件中。
结合 for-range 语句
用户使用姿势:对应使用函数 chanrecv2,位于 runtime/chan.go 文件中。
源码解析
以上,我们通过宏观的用户使用姿势,了解了不同使用姿势对应的不同实现函数,接下来将详细分析这些函数的实现。
makechan 函数
负责 channel 的创建。在 go 程序中,阅读程序源码当我们写类似 v := make(chan int) 的初始化语句时,就会调用不同类型对应的初始化函数,其中 channel 的初始化函数就是 makechen。
runtime.makechan
定义原型:
通过这个,我们可以了解到,声明创建一个 channel 实际上是得到了一个 hchan 的指针,因此 channel 的核心结构就是基于 hchan 实现的。
其中,t 参数指定元素类型,size 指定 channel 缓冲区槽位数量。如果是带缓冲区的 channel,那么 size 就是槽位数;如果没有指定,那么就是 0。
makechan 函数执行了以下两件事:
1. 参数校验:主要是越界或 limit 的校验。
2. 初始化 hchan:分为三种情况:
所以,我们看到除了 hchan 结构体本身的内存分配,该结构体初始化的关键在于四个字段:
hchan 结构
makechan 函数负责创建了 chan 的核心结构-hchan,接下来我们将详细分析 hchan 结构体本身。
在 makechan 中,初始化时实际上只初始化了四个核心字段:
我们使用 channel 时知道,channel 常常会因为两种情况而阻塞:1)投递时没有空间;2)取出时还没有元素。红色教程网源码
从以上描述来看,就涉及到 goroutine 阻塞和 goroutine 唤醒,这个功能与 recvq,sendq 这两个字段有关。
waitq 类型实际上是一个双向列表的实现,与 linux 中的 LIST 实现非常相似。
chansend 函数
chansend 函数是在编译器解析到 c <- x 这样的代码时插入的,本质上就是把一个用户元素投递到 hchan 的 ringbuffer 中。chansend 调用时,一般用户会遇到两种情况:
接下来,我们看看 chansend 究竟做了什么。
当我们在 golang 中执行 c <- x 这样的代码,意图将一个元素投递到 channel 时,实际上调用的是 chansend 函数。这个函数分几个场景来处理,总结来说:
关于返回值:chansend 返回值标明元素是否成功入队,成功则返回 true,否则 false。
select 的提前揭秘:
golang 源代码经过编译会变成类似如下:
而 selectnbasend 只是一个代理:
小结:没错,chansend 功能就是这么简单,本质上就是抽奖软件源码下载一句话:将元素投递到 channel 中。
chanrecv 函数
对应的 golang 语句是 <- c。该函数实现了 channel 的元素出队功能。举个例子,编译对应一般如下:
golang 语句:
对应:
golang 语句(这次的区别在于是否有返回值):
对应:
编译器在遇到 <- c 和 v, ok := <- c 的语句时,会换成对应的 chanrecv1,chanrecv2 函数,这两个函数本质上都是一个简单的封装,元素出队的实现函数是 chanrecv,我们详细分析这个函数。
chanrecv 函数的返回值有两个值,selected,received,其中 selected 一般作为 select 结合的函数返回值,指明是否要进入 select-case 的代码分支,received 表明是否从队列中成功获取到元素,有几种情况:
selectnbsend 函数
该函数是 c <- v 结合到 select 时的函数,我们使用 select 的 case 里面如果是一个 chan 的表达式,那么编译器会转换成对应的 selectnbsend 函数,如下:
对应编译函数逻辑如下:
selectnbsend 本质上也就是个 chansend 的封装:
chansend 的内部逻辑上面已经详细说明过,唯一不同的就是 block 参数被赋值为 false,也就是说,在 ringbuffer 没有空间的情况下也不会阻塞,直接返回。划重点:chan 在这里不会切走执行权限。
selectnbrecv 函数
该函数是 v := <- c 结合到 select 时的函数,我们使用 select 的 case 里面如果是一个 chan 的表达式,那么编译器会转换成对应的 selectnbsrecv 函数,如下:
对应编译函数逻辑如下:
selectnbrecv 本质上也就是个 chanrecv 的封装:
chanrecv 的内部逻辑上面已经详细说明过,在 ringbuffer 没有元素的情况下也不会阻塞,直接返回。这里不会因此而切走调度权限。
selectnbrecv2 函数
该函数是 v, ok = <- c 结合到 select 时的函数,我们使用 select 的 case 里面如果是一个 chan 的表达式,那么编译器会转换成对应的 selectnbrecv2 函数,如下:
对应编译函数逻辑如下:
selectnbrecv2 本质上是个 chanrecv 的封装,只不过返回值不一样而已:
chanrecv 的内部逻辑上面已经详细说明过,在 ringbuffer 没有元素的情况下也不会阻塞,直接返回。这里不会因此而切走调度权限。selectnbrecv2 与 selectnbrecv 函数的不同之处在于还有一个 ok 参数指明是否获取到了元素。
chanrecv2 函数
chan 可以与 for-range 结合使用,编译器会识别这种语法。如下:
这个本质上是个 for 循环,我们知道 for 循环关键是拆分成三个部分:初始化、条件判断、条件递进。
那么在我们 for-range 和 chan 结合起来之后,这三个关键因素又是怎么理解的呢?简述如下:
init 初始化:无
condition 条件判断:
increment 条件递进:无
当编译器遇到上面 chan 结合 for-range 写法时,会转换成 chanrecv2 的函数调用。目的是从 channel 中出队元素,返回值为 received。首先看下 chanrecv2 的实现:
chan 结合 for-range 编译之后的伪代码如下:
划重点:从这个实现中,我们可以获取一个非常重要的信息,for-range 和 chan 的结束条件只有这个 chan 被 close 了,否则一直会处于这个死循环内部。为什么?注意看 chanrecv 接收的参数是 block=true,并且这个 for-range 是一个死循环,除非 chanrecv2 返回值为 false,才有可能跳出循环,而 chanrecv2 在 block=true 场景下返回值为 false 的唯一原因只有:这个 chan 是 close 状态。
总结
golang 的 chan 使用非常简单,这些简单的语法糖背后其实都是对应了相应的函数实现,这个翻译由编译器来完成。深入理解这些函数的实现,对于彻底理解 chan 的使用和限制条件是必不可少的。深入理解原理,知其然知其所以然,你才能随心所欲地使用 golang。
linux程序内存越界定位分析总结有哪些?
在工作中遇到一个奇特问题,编译同一份源码生成的.so库在程序中使用时出现各种异常情况,而其他同事编译出的库则无问题。初步分析发现是库源代码中一个全局数组内存地址大面积越界到其他全局数组。现象为触发特定业务条件时,程序逻辑运行异常,异常log显示“g_sMaxFd”变量值被置0,正常情况下应大于0,导致业务运行异常。
分析确定问题出现在代码中对“g_sMaxFd”变量的赋值操作,可能是内存越界引起。定位内存越界处的策略是使用Linux的mprotect()函数设置指定内存区域为只读,故意使程序引发segment fault退出并生成core dumped文件,以此定位问题点。首先,了解mprotect()函数的使用和局限性。
采用“g_sMaxFd”数组地址与页大小整数倍的对齐策略,或在数组地址前定义一个动态数组“g_debug_place”,大小为页大小整数倍,以确保只在内存越界的地方被访问。这种方法需要调整内存分配以满足mprotect()函数参数长度要求。如果“g_sMaxFd”数组起始地址不是页大小整数倍,计算大于且最接近的页大小整数倍地址,作为mprotect()函数的起始地址。
调整内存分配后,通过复现问题并等待程序内存越界产生段错误退出,分析核心是通过gdb工具分析core文件。确保编译可执行程序时加入-g参数以保留调试信息,并检查core dumped是否已开启。利用backtrace相关函数代替gdb分析,可能更轻量化且适用性更强。
进一步分析发现,问题与编译顺序有关。在生成.so库时,链接.o文件的顺序差异导致全局变量数组地址分布不同。具体分析log文件显示两个全局数组变量“gs_s8Contenx”与“g_sMaxFd”的地址顺序差异,这是问题暴露的关键点。由于编译顺序影响了变量地址顺序,导致我编译的库中“gs_s8Contenx”地址小于“g_sMaxFd”,在代码中以超过数组元素最大值进行赋值操作时,引发大面积内存越界,从而导致g_sMaxFd变量值被修改,产生异常。
同事编译的库同样存在gs_s8Contenx越界问题,但由于gs_s8Contenx地址大于g_sMaxFd,因此越界的是一个不常用的地址,问题未能立即显现。理解编译顺序对全局变量位置的影响是解决此类问题的关键。