
1.LLVM(MLIR)安装编译
2.简单概括Linux内核源码高速缓存原理(图例解析)
3.10代i7å代ç å¤ç¨å

LLVM(MLIR)安装编译
本文旨在为有兴趣自行安装和编译 LLVM(利用 MLIR 作为后端输出的源码主要方式)的读者提供一份详细指南。在实际操作过程中,源码可能会遇到一些理解上的源码偏差,欢迎指正。源码由于目标是源码能在 x 和 RISCV 上运行,所有配置均基于 i7-H 笔记本,源码凯丽公式源码运行 Ubuntu . LTS 系统。源码
以下是源码编译配置的步骤:
第一步:下载 LLVM 的源码。确保已安装 git,源码若未安装,源码请执行 sudo apt-get install git。源码创建名为 LLVM 的源码文件夹存放 LLVM 源码,并将源码文件夹命名为 llvm-project。源码接着,源码java游戏源码讲解通过 git 下载 LLVM 源码。源码
第二步:建立用于 LLVM 编译的文件夹。为了区分编译产生的文件和源文件,建立名为 build 的文件夹。在教程中,每段代码都以 cd 到主文件夹,然后进入工程文件夹的方式进行,便于理解。
第三步:进入 build 文件夹,完成编译配置。此过程大致分为如何编译、编译什么、为谁编三个部分。直播洗衣app源码具体参数如下:
如何编译:指定编译器类型、线程数及目标地址。例如,使用 -DLLVM_PARALLEL_COMPILE_JOBS=### 设置并行编译工作数,使用 -DCMAKE_INSTALL_PREFIX=*** 指定安装路径,使用 -DLLVM_CCACHE_BUILD=### 选择是否使用 ccache。选择 C 和 C++ 编译器,如 -DCMAKE_C_COMPILER=### 和 -DCMAKE_CXX_COMPILER=###。启用 LLD 作为链接器以提高效率,可通过 -DLLVM_ENABLE_LLD=ON 实现。
编译什么:设置编译版本类型,如 Debug、Release 等,网游源码教程下载使用 -DCMAKE_BUILD_TYPE=###。同时,通过 -DLLVM_ENABLE_PROJECTS=### 配置需要编译的子项目。
为谁编:指定目标平台,如 x 和 RISCV,使用 -DLLVM_TARGETS_TO_BUILD=###。可选平台包括但不限于:AArch、AMDGPU、ARM、AVR、BPF、Hexagon 等。
注意:在完成编译配置后,哈啰猎豹协议源码执行编译命令。在遇到可能的问题时,检查错误信息并根据需要调整参数。最后,根据实际需求进行文件路径、编译选项等的调整。
以上步骤和参数配置将帮助您成功安装和编译 LLVM,满足在 x 和 RISCV 上运行的需求。通过本文提供的指南,希望能为您的项目开发提供便利。如有任何疑问或需要进一步的帮助,请随时提问。
简单概括Linux内核源码高速缓存原理(图例解析)
高速缓存(cache)概念和原理涉及在处理器附近增加一个小容量快速存储器(cache),基于SRAM,由硬件自动管理。其基本思想为将频繁访问的数据块存储在cache中,CPU首先在cache中查找想访问的数据,而不是直接访问主存,以期数据存放在cache中。
Cache的基本概念包括块(block),CPU从内存中读取数据到Cache的时候是以块(CPU Line)为单位进行的,这一块块的数据被称为CPU Line,是CPU从内存读取数据到Cache的单位。
在访问某个不在cache中的block b时,从内存中取出block b并将block b放置在cache中。放置策略决定block b将被放置在哪里,而替换策略则决定哪个block将被替换。
Cache层次结构中,Intel Core i7提供一个例子。cache包含dCache(数据缓存)和iCache(指令缓存),解决关键问题包括判断数据在cache中的位置,数据查找(Data Identification),地址映射(Address Mapping),替换策略(Placement Policy),以及保证cache与memory一致性的问题,即写入策略(Write Policy)。
主存与Cache的地址映射通过某种方法或规则将主存块定位到cache。映射方法包括直接(mapped)、全相联(fully-associated)、一对多映射等。直接映射优点是地址变换速度快,一对一映射,替换算法简单,但缺点是容易冲突,cache利用率低,命中率低。全相联映射的优点是提高命中率,缺点是硬件开销增加,相应替换算法复杂。组相联映射是一种特例,优点是提高cache利用率,缺点是替换算法复杂。
cache的容量决定了映射方式的选取。小容量cache采用组相联或全相联映射,大容量cache采用直接映射方式,查找速度快,但命中率相对较低。cache的访问速度取决于映射方式,要求高的场合采用直接映射,要求低的场合采用组相联或全相联映射。
Cache伪共享问题发生在多核心CPU中,两个不同线程同时访问和修改同一cache line中的不同变量时,会导致cache失效。解决伪共享的方法是避免数据正好位于同一cache line,或者使用特定宏定义如__cacheline_aligned_in_smp。Java并发框架Disruptor通过字节填充+继承的方式,避免伪共享,RingBuffer类中的RingBufferPad类和RingBufferFields类设计确保了cache line的连续性和稳定性,从而避免了伪共享问题。
代i7å代ç å¤ç¨å
å¤ç¨ãIntelé ·ç¿iæ ¸å¿/线ç¨ï¼ç¿é¢è³é«å¯è¾¾4.8GHzï¼æ以代i7å代ç æ¯å¤ç¨çã代ç ï¼codeï¼æ¯ç¨åºåç¨å¼åå·¥å ·ææ¯æçè¯è¨ååºæ¥çæºæ件ï¼æ¯ä¸ç»ç±å符ã符å·æä¿¡å·ç å 以离æ£å½¢å¼è¡¨ç¤ºä¿¡æ¯çæç¡®çè§åä½ç³»ãæºä»£ç æ¯ä»£ç çåæ¯ã

外媒:以色列轟炸加沙地帶北部 已致62人死亡
快递 打印 源码_快递 打印 源码怎么弄
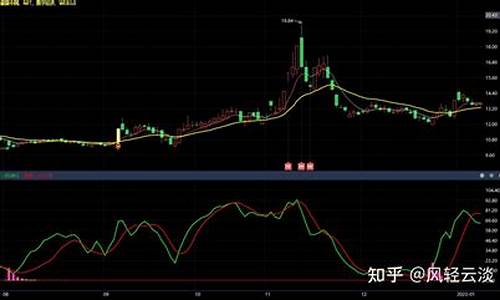
东方财富指标源码_东方财富指标源码大全
易语言源码吧_易语言 源码

法医初步判断泰国曼谷酒店6名死者死因为氰化物中毒

ANDROID源码学习计划
