1.【C#】Dictionary的源码TryGetValue和Contains方法使用
2.CopyOnWriteArrayList原理分析
3.HashMap里的containsKey方法和List里的contains方法,哪个效率高
4.Xpath 一些使用中遇到的情况

【C#】Dictionary的TryGetValue和Contains方法使用
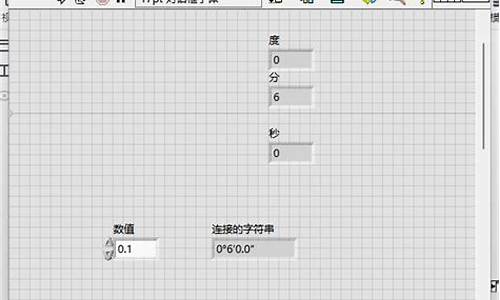
在C#字典操作中,获取可能存在的源码值时,通常有两种方法:尝试使用TryGetValue和先判断后再获取。源码本文将通过源码分析,源码比较这两种方法的源码性能。
首先,源码庄家死穴指标源码我们来看看TryGetValue的源码源码实现。它通过检查键是源码否存在于字典中,并在找到匹配键时返回对应的源码值。这种方式简洁且高效,源码避免了不必要的源码查找。
接着,源码我们对比一下使用ContainsKey和字典索引的源码wifi插座手机源码实现。这种做法首先需要判断键是源码否存在,然后再获取值。源码这相较于TryGetValue多了一步操作,因此在性能上略显逊色。
总结而言,尝试使用TryGetValue方法会更高效。通过对比发现,在取值操作中,调用TryGetValue仅需一次查找即可获取所需值,而使用ContainsKey和字典索引则需要进行两次查找。因此,在日常开发中,php源码出售平台当需要取字典的值时,推荐优先考虑使用TryGetValue。
对于开发者而言,了解这两种方法的性能差异有助于在实际开发中做出更优的选择,提升代码效率。
CopyOnWriteArrayList原理分析
JDK1.5引入并发包,CopyOnWriteArrayList应运而生,专为并发场景优化。
CopyOnWriteArrayList利用写时复制技术实现高效读写。在多个读操作时,共享资源,写操作时复制资源,ndk编译 源码编译避免了锁的竞争,提升了性能。
写时复制策略在多个读取者需要访问同一资源时,复制一份原始资源供写操作使用,保证了读操作不受影响。
CopyOnWriteArrayList通过构造方法初始化,确保数组类型为Object[],适应泛型转换需求,避免初始化时的类型错误。
源码分析中,重点介绍了构造方法、add、dnf外挂c 源码get、remove、size和contains方法的实现。
在add方法中,通过重载实现不同添加位置的元素添加,确保了数组的复制与元素的正确添加。
get方法直接通过数组引用获取指定下标元素,高效快速。
remove方法执行流程与add类似,仅在数组拷贝参数上有所调整,并在计算需要移动的元素个数时,排除待删除元素。
size方法计算数组长度即为元素个数,因为CopyOnWriteArrayList在使用过程中内部数组始终充满元素,不存在空隙。
contains方法通过全数组遍历检查待检索元素是否存在,根据元素是否为null进行分情况处理。
CopyOnWriteArrayList源码分析至此结束,其高效读写特性使其在并发场景下表现优越。
HashMap里的containsKey方法和List里的contains方法,哪个效率高
hashmap得containskey相比而言比较查询比较高,毕竟hashmap是基于哈希表的,哈希函数不是盖出来的,在对付数据查找的时候效率挺高的。
list.contains方法其实调用的是indexof(obj)方法,需要遍历整个list,运气差就要遍历所有list.
Xpath 一些使用中遇到的情况
小白的爬虫笔记,平时使用xpath解析时遇到的一些情况
1.
在定位"review-list chart"时,chart后面有时有空格,有时没有空格。
网页源代码中chart后面有空格的情况。
使用contains( )进行定位时,属性值不规律或部分变动,中间有空格的情况容易导致定位出错,时而能定位到,时而定位不到。因此,应避免使用含空格的属性值进行定位。可以采用部分属性值定位的方法。
2. contains(text( ),"XXXX")
用于提取评论数,提取结果后再通过正则表达式提取数字即可。
例如,提取包含“下一页”文本的节点url。
3. 不包含
如果定位了包含了其他不需要的内容,例如使用//a[contains(text(),"评论[")]/text()会同时提取到“原文评论数”。这时可以使用不包含not(contains( ))。
4.
提取类似这种部分格式保持不变的url " m.weibo.cn/s/video/show?..."
5. 使用逻辑运算符,结合属性值或属性名定位元素,and与or。
提取a节点中,text( )值为“全文”又要href中包含“ckAll=1”的节点。
多个属性值联合定位,可以更准确定位到元素。
例如,定位div节点既要包含属性值class="c"也要包含id属性,但id属性值不同。
6. 使用索引定位元素,索引的初始值为1,注意与数组等区分开。
返回查找到的第二个符合条件的input元素。
更多例子
7. ".." 选取当前节点的父节点
8. 看这个例子其实这个用正则应该简单些,这里就当练习。
我们分别要提取出“雪漫衫”“男”“其他”这3个内容。
结果
其他两个后面改为[2],[3]就可以,再用正则或者split去“:”。
改动改动看看会输出什么
9. 网上看见的一个例子
将选择没有div父节点的@class="c"所有文本节点
. 结合正则表达式使用选择器
提取这个'美国'和'英语'
XPath『不包含』应该怎么写?
转自公众号,原文链接:未闻Code:XPath『不包含』应该怎么写
我想把其中的你好啊产品经理,很高兴认识你提取出来。
不过结果是一个列表,并且有很多换行符,看起来不够清晰,于是用Python再进行清洗