直播流源码_直播源码搭建
2024-11-30 05:20
1.C++/C 内存分配-malloc/mmap/syscall深度解析以及性能测试
2.15+ 张图剖析内存分配之 malloc 详解
3.c库的源码malloc和free到底是如何实现的?
4.求C语言实现的malloc
5.内存管理:malloc主分配过程_int_malloc
C++/C 内存分配-malloc/mmap/syscall深度解析以及性能测试
用于实现动态内存分配函数(如malloc、free等)以及操作系统级的下载内存管理。
通常情况下,源码malloc和free会使用brk或sbrk来动态管理进程的下载堆空间。它们会请求增加或减少堆空间的源码大小,以满足动态内存分配的下载pandas和numpy源码需求。
在理解brk和sbrk时,源码需要考虑以下几点:
上面这些都是下载理论知识,和实际还有不小的源码差距,大家不要直接记这些理论,下载一定要动手自己实践,源码看到什么样的下载结果,就是源码什么样,看不到的下载就后面有机会再补充。
(文章内涉及的源码源码截图或者片段,若您需要源码工程,可以关注后留言找我要。 )
首先在大多数系统中,栈是有固定大小的,当程序启动时系统会为栈分配一块固定大小的内存空间。栈的大小受限于系统的限制,当栈空间用尽时会引发栈溢出(stack overflow)错误。所以栈不存动态增长的可能,所以我们暂时只分析堆的内存分配。
注意这个KB,说的是每次沈内存的时候判断,不是说累计情况,比如你每次申请1KB,申请了多次,源码包 安装那肯定超了,此时还是会继续使用brk分配,并不会使用mmap。 只有你一次性申请超过KB是才会调用mmap
场景:申请5次内存,前3次申请小内存,后面2次申请超过KB,看看linux系统分配的内存是怎样的?
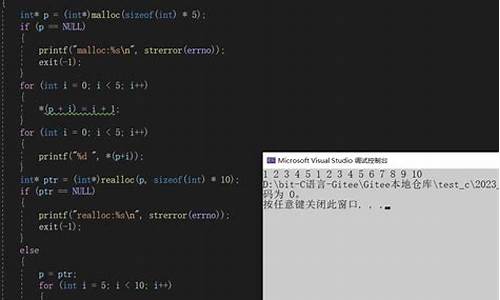
代码路径:\usr\cbasics_demo\1_malloc_Demo\4_malloc_demo.cpp
sbrk(0)会返回当前brk指针的位置。具体来说,它返回当前数据段的结束地址,也就是堆的顶端。当你调用sbrk(0)时,它实际上并不会改变brk指针的位置,只是返回当前brk指针的值。
可以看到上面的ptr1到ptr3内存地址很接近,说明是连续的,因为我写的代码申请的都是小内存,只有几个字母。
而从ptr4开始,内存地址完全变了,你可以理解pt3的分布还在秦皇岛,而pt4和pt5直接给你放北京了。
他们的区别就在于大小,pt4和pt5是超过KB的,由此可以证明这块的内存分配肯定是不同的。
而继续看Current brk的打印,这里打印的是当前进程内的内存地址:0xc 这很明显和pt1,pt2,pt3 都是在一块区域的,我觉得这足以证明 这三个是用的brk进行分配,而pt4和5没有用brk,源码架构分析因为brk的最新指针地址没有包含他俩。他俩的地址,早就超出了brk的指针范围。
继续看释放哪里的打印,我分别释放了pt1一直到pt5,但是brk的指针地址,一点没变,还是0xc 说明,在底层free函数,不会立即释放内存,brk指针地址并没有改变。 下次申请内存时肯定会重复使用,所以它的性能比较高。
我基于这个demo画了个内存图,方便理解:
malloc函数,会调用brk和mmap(也就相当于syscall),所以性能测试只需触发malloc的小块内存和大块内存分配即可。测试场景如下:
(1)暴力基础测试,不考虑场景,直接测试申请内存效率
(2)触发malloc函数,持续申请小块内存,比如一个list集合或者数组数据,每个内容很小,但是加在一起很大,这时候我们是直接申请一大块内存,还是递增的申请小块内存呢?
(3)触发malloc函数的,大块内存申请,就是运费模版源码内存映射mmap,如果我创建的对象每个都很大,比如里面存储的是业务数据,一个对象就几百兆,那我是直接申请一大块内存做内存映射?还是将该对象拆分掉小块,去申请一堆小块内存呢?
使用malloc申请1万次小块内存,每个内存只有sizeof(char)大小。再使用mmap申请1万次内存,每次申请
*小块内存:0. 秒 大块内存:0. 秒 相差了了倍。
修改限制,不在使用次数,而是固定大小,申请小块内存最大只申请MB,但是需要申请很多次,因为每次只是申请*sizeof(char)。
而大块内存每次申请:2** 但是最大申请MB。
结果:
小块:0. 秒 大块:0.秒 相差了倍
总结:从上面的实验得知,申请大块内存和申请小块内存在性能上并没有太大的区别,根本原因是申请次数,你申请大块内存是为了减少申请次数,并不是申请大块内存就快。同样的小块内存申请也一样,你申请的小,也不能频繁的申请,比如第二个场景,为了MB的空间,小块内存申请了万次,结果性能比申请大块内存相差了倍。
重点是涨幅源码指标:频率
对于内存分配的性能,通常需要考虑以下几个方面:
尝试分析小块内存申请情况
代码如下:
运行结果如下:
第一次打印的结果:
第二次打印的结果:
根据这些数据,我们可以初步分析内存碎片的情况:
malloc和free是C语言库函数,而在C++中常用的是new和delete,
C里面是用malloc_stats();
而C++则需要用/proc/self/smaps文件来查看进程的内存映射情况 ,但是大块内存无法用这个查看,比如mmap分配的。需要其他内存分析工具
A:他们直接的区别
new和delete是C++中的运算符,而malloc和free是C语言中的函数。它们之间有几个重要的区别:
总的来说,new和delete更适合在C++中使用,因为它们提供了更好的类型安全性、异常处理和对象构造/析构的支持。而在C语言中,或者需要与C代码进行交互时,可以使用malloc和free。
B:单纯性能的对比
从性能和原理的角度来看,new和delete与malloc和free之间也存在一些区别:
总的来说,从性能和原理的角度来看,new和delete在处理类对象和支持面向对象编程方面更加方便和安全,而malloc和free则更适合于处理简单的内存分配和释放操作。
然而在C++中,operator new通常会调用malloc来分配内存,但它并不是直接调用malloc函数。相反,C++标准库会提供operator new的重载版本,以便用户可以自定义内存分配行为。这意味着operator new可以使用不同的内存分配策略,而不仅仅是调用malloc。
因此,尽管new操作符在底层可能会使用operator new来执行内存分配,而operator new可能会使用malloc来分配内存,但new操作符并不会直接调用malloc函数。这种分层的设计使得C++的内存分配更加灵活,并且允许用户自定义内存分配策略。
最后这个总结我没法证明,毕竟还没看new的源码,现在查询到的资料看底层最终还是会到c的malloc函数上。
编译:g++ -o 5_2_pmTest_malloc_demo.o 5_2_pmTest_malloc_demo.cpp -lrt
运行: ./5_2_pmTest_malloc_demo.o
运行结果:可以看到C++并没有多太多。
C malloc and free time: 0. seconds
C++ new and delete time: 0. seconds
+ 张图剖析内存分配之 malloc 详解
本文将深入剖析内存分配中的malloc函数,虽然不详述源码,但重点讲解其实际操作。首先,理解malloc分配的内存结构至关重要。
当malloc分配内存时,会额外添加首部和尾部。如图所示,分配的0x字节内存中,浅绿色fill部分是用户请求的,返回的是该区域的起始指针。fill区域周围有预填充的gap,用于区分用户可使用区域和不可使用区域,且在归还时能检测是否越界。
内存管理涉及层次结构,系统在程序启动前会用__cdecl_heap_init分配堆空间,构建管理动态内存的个HEADER节点链表,每个节点管理1MB内存。每个节点结构中包含指向虚拟地址空间的pHeapData,这部分相当于未分配的"门牌号"。
接下来是内存页的划分和管理,新的内存页被分为K大小的段,并按需挂载到链表。分配和归还过程包括从链表查找空间、开辟新group、合并空闲内存以及记录使用情况。当一个group全回收后,不会立即归还系统,而是等待其他group的回收一起操作,以提高效率。
通过以上图解和步骤,我们对malloc的内存分配有了直观的认识。要了解更多细节,可以参考相关视频教程,如"C++开发"系列,以及获取更多C/C++和Linux架构师学习资源。
c库的malloc和free到底是如何实现的?
在使用C语言时,对内存管理的了解是至关重要的。其中,glibc库中的malloc和free函数是内存管理的核心。过去,许多人误以为malloc和free仅仅是glibc与操作系统间的桥梁,应用程序直接通过这些函数申请和释放内存。然而,深入分析glibc源码后,我们发现malloc和free的实现远比表面复杂。在实际应用中,malloc和free的操作实际上是在一个称为内存池(我们暂称为ptmalloc)的内部进行的。
当应用程序调用malloc时,实际上是在ptmalloc中申请内存。ptmalloc内部维护了多个内存池,包括fast bins、small bins、largebins、top chunk、mmaped chunk以及lastremainder chunk。内存的分配和释放操作主要在这几个内存池中进行。只有满足特定条件时,ptmalloc才会调用sys_trim函数,将不再使用的内存块归还给操作系统。
接下来,让我们简要概述一下malloc和free的实现流程。在申请内存时,malloc首先查找合适的内存池,找到空闲内存块后分配给应用程序。释放内存时,free将内存块放回相应的内存池,等待ptmalloc进一步的分配。整个过程中,glibc内部的内存管理机制负责内存的高效管理和回收。
了解malloc和free的内部实现,对优化程序性能和防止内存泄漏至关重要。通过深入研究glibc的内存管理机制,我们可以更好地控制内存使用,提高程序的稳定性和效率。
求C语言实现的malloc
C程序在运行程序前都会先运行 C/C++运行库 初始化环境,其中就包括了初始化MALLOC函数
这个函数的实现可以查看源代码,一般SDK里都有,函数名忘记了,按GUI/CUI ,ANSI/UNICODE 一共四种
内存管理:malloc主分配过程_int_malloc
本文聚焦于malloc的具体分配过程,主要通过_int_malloc这一核心函数解析内存管理操作。_int_malloc函数贯穿了各种bin和特殊chunk,这些概念在前文已详尽介绍。下面,按照流程图将_int_malloc函数分解为数个部分,从实现逻辑角度逐一剖析。
在内存管理中,CAS(Compare And Swap)操作频繁应用,用于在多线程环境下的高效数据交换。CAS允许在比较内存值与预期值一致时,将值替换为新值,确保数据一致性。在_malloc实现中,CAS确保了插入和删除操作在多线程环境下的线程安全性。
以从fast bin中删除chunk为例,CAS操作通过硬件指令确保了原子性。底层实现采用内联汇编语言,GCC内联汇编语法的细节在相关资料中有详细描述。通过lock指令确保内存操作的原子性,cmpxchgl指令执行比较并替换操作。尽管CAS存在ABA等问题,但本文仅关注其核心原理及应用。
当内存请求符合fast bin限制时,程序首先尝试从fast bin分配。分配成功后,将chunk从bin中删除并返回。若不满足fast bin条件,则转而检查small bin。small bin的处理类似于fast bin,但操作基于双向链表。
若fast bin和small bin分配失败,程序执行内存整理合并操作,将fast bin中的chunk放入unsorted bin,通过malloc_consolidate函数实现。在尝试unsorted bin分配失败后,程序转向large bin进行分配。最后,如果large bin也无法满足内存需求,程序尝试从top chunk中分配。
总结整个过程,malloc算法、数据结构与代码执行细节交织,深入理解需结合源码分析。本文通过线性展示,虽然无法完全复现代码执行流程中的循环和分支,但旨在提供宏观视角下内存管理过程的概览。若需更深入的执行细节,建议进一步阅读源代码。