
1.Apache Spark RDD介绍
2.深入浅出Spark(二) 什么是RDD
3.pyspark中RDD一些函数的解释
4.Spark源码解析2-YarnCluster模式启动
5.Spark原理详解
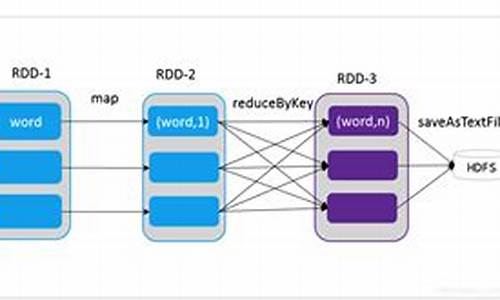
Apache Spark RDD介绍
RDD(Resilient Distributed Datasets)是Apache Spark中用于分布式计算的核心抽象。它的设计旨在提供高效、容错的内存计算能力,适用于大规模集群环境。
RDD提供了一种只读、分片记录集合,restful 源码只能通过静态存储数据或其它RDD创建,支持迭代算法和交互式数据挖掘的高效执行。与MapReduce框架相比,RDD更加注重数据的复用和减少磁盘I/O、数据同步的开销,使得内存读取速度更快。
在RDD框架中,数据操作分为Transformation(数据转换)和Action(动作执行)。Transformation是延迟执行的,只有在遇到Action操作时才会真正运行。例如,创建RDD的操作包括从文件系统加载数据,或通过map、filter等方法进行转换。
RDD有窄依赖与宽依赖之分。窄依赖在单个节点内执行,节省了数据传输的开销,而宽依赖则涉及到多个节点间的数据shuffle。窄依赖在节点故障恢复时效率更高,只需重新计算丢失的在线阅读pdf源码RDD数据,而宽依赖则需要从祖先节点开始重新计算。
Apache Spark的任务调度采用BSP(Bulk Synchronous Parallel)模型,实现整体同步并行计算。BSP模型具有快速恢复故障和优化数据处理吞吐量的优点,但可能增加数据处理的延迟。
RDD和Spark的结合使得Apache Spark成为处理大规模数据的高效工具,支持迭代算法、交互式数据挖掘,并提供快速恢复机制和优化的资源调度。
深入浅出Spark(二) 什么是RDD
在深入浅出Spark系列讲座中,我们将探讨Apache Spark中的核心数据抽象——弹性分布式数据集(RDD)。RDD在Spark中扮演了至关重要的角色,它提供了数据的并行化处理能力,使得大规模数据集的处理变得高效和灵活。
RDD是Spark中用于表示数据集的抽象概念。从逻辑上看,它是一个数据集合,但实际上,它在物理上可以被划分为多个数据块,分布在不同的机器上并发执行。这一特性使得RDD能够在分布式环境下高效地处理大规模数据。
在RDD的生命周期中,数据的创建、变换和操作是关键环节。首先,super云轰炸源码RDD可以通过将内存数据并行化或直接从分布式数据库(如S3、HDFS、Cassandra等)读取来生成。这一过程利用了Spark的分布式计算能力,使得数据能够快速加载并准备用于处理。
在变换操作中,如filter、map等,数据并不立即进行实际的修改,而是被记录为依赖关系。只有当执行Action操作,如count或collect时,数据才进行实际的计算和返回结果。这一延迟计算特性,结合Spark的全局优化策略,显著提升了数据处理的效率。
RDD的cache操作允许将中间结果保存在内存中,以备后续使用,从而避免了重复计算,提高了程序执行速度。Action操作则负责返回最终结果或执行某些特定的统计计算。
RDD可以分为多种类型,如从JDBC获取的数据集、从HDFS读取的数据集等,每种类型具有特定的超准共振源码特征和优化策略,以适应不同的数据源和处理需求。
通过深入理解RDD的生成、变换和操作机制,开发者能够更有效地利用Spark进行大规模数据的并行处理。RDD作为Spark生态系统中的基石,对于实现高效、可扩展的数据处理流程至关重要。
pyspark中RDD一些函数的解释
在数据处理领域,当面临大数据规模时,传统库如pandas可能会因为内存限制或性能瓶颈而难以胜任。这时,引入Spark成为解决方案。本文聚焦于pyspark中的RDD及其相关函数,旨在提供直观理解与查阅便利。
RDD(弹性分布式数据集)是Spark的基本数据抽象层,它允许用户在分布式计算环境中执行数据处理任务。其中,aggregate(zeroValue,seqOp,combOp)函数用于聚合操作,其中`seqOp`和`combOp`分别对各个分区内的数据进行序列化和合并操作。序列化操作`seqOp`首先对每个分区的数据进行更新,生成一个与分区数据格式不同的结果`U`;合并操作`combOp`则将所有分区的结果`U`进行聚合,最终生成单一结果。
举例而言,假设通过parallelize函数将数据分为两个分区:[1, 2]和[3, 4]。在`seqOp`阶段,论坛源码discuz模板`lambda x, y`函数首先分别代表初始值`(0, 0)`和分区内的第一个元素,随后不断迭代,将所有元素累加。两个分区计算后分别得到`(3, 2)`和`(7, 2)`,最后在`combOp`阶段进行合并,得到最终结果`(, 2)`,表示所有元素的累加和及总分区数。
另一个类似的函数aggregateByKey(zeroValue,seqFunc,combFunc,numPartitions=None,partitionFunc=)与aggregate功能相似,但针对键值对操作,适用于`key-value`格式数据的聚合。
在数据处理过程中,cache()用于缓存RDD,以节省内存和提高后续操作效率。通过cartesian()函数,可以实现RDD中的笛卡尔积,生成所有可能的组合。当需要调整分区数量时,coalesce(numPartitions,shuffle=False)提供了一种灵活的重分区方法,而cogroup(other,numPartitions=None)则用于合并具有相同键的RDD。
为了获取所有数据,可以使用collect()函数,但应确保数据量适中,以免影响性能。若希望以字典形式返回结果,collectAsMap()提供了该功能。对于特定聚合需求,combineByKey(createCombiner,mergeValue,mergeCombiners,numPartitions=None,partitionFunc)提供了一种灵活的聚合方式,初始值通过`createCombiner`函数计算得出,随后进行序列化和合并操作。
基本统计操作包括count()计算元素总数、countByValue()和countByKey()分别用于统计每个值或键的出现次数。在处理键值对数据时,flatMap()和flatMapValues()分别用于将列表数据扁平化和扁平化键值对数据。
最后,fullOuterJoin(other,numPartitions=None)函数则用于执行全外联接,生成包含两个RDD中所有键的键值对。
综上所述,pyspark中的RDD及其相关函数提供了丰富的数据处理能力,适用于各种规模的数据集,为高效数据处理提供了强大的工具。
Spark源码解析2-YarnCluster模式启动
YARN 模式运行机制主要体现在Yarn Cluster 模式和Yarn Client 模式上。在Yarn Cluster模式下,SparkSubmit、ApplicationMaster 和 CoarseGrainedExecutorBackend 是独立的进程,而Driver 是独立的线程;Executor 和 YarnClusterApplication 是对象。在Yarn Client模式下,SparkSubmit、ApplicationMaster 和 YarnCoarseGrainedExecutorBackend 也是独立的进程,而Executor和Driver是对象。
在源码中,SparkSubmit阶段首先执行Spark提交命令,底层执行的是开启SparkSubmit进程的命令。代码中,SparkSubmit从main()开始,根据运行模式获取后续要反射调用的类名赋给元组中的ChildMainClass。如果是Yarn Cluster模式,则为YarnClusterApplication;如果是Yarn Client模式,则为主类用户自定义的类。接下来,获取ChildMainClass后,通过反射调用main方法的过程,反射获取类然后通过构造器获取一个示例并多态为SparkApplication,再调用它的start方法。随后调用YarnClusterApplication的start方法。在YarnClient中,new一个Client对象,其中包含了yarnClient = YarnClient.createYarnClient属性,这是Yarn在SparkSubmit中的客户端,yarnClient在第行初始化和开始,即连接Yarn集群或RM。之后就可以通过这个客户端与Yarn的RM进行通信和提交应用,即调用run方法。
ApplicationMaster阶段主要涉及开启一个Driver新线程、AM向RM注册、AM向RM申请资源并处理、封装ExecutorBackend启动命令以及AM向NM通信提交命令由NM启动ExecutorBackend。在ApplicationMaster进程中,首先开启Driver线程,开始运行用户自定义代码,创建Spark程序入口SparkContext,接着创建RDD,生成job,划分阶段提交Task等操作。
在申请资源之前,AM主线程创建了Driver的终端引用,作为参数传入createAllocator(),因为Executor启动后需要向Driver反向注册,所以启动过程必须封装Driver的EndpointRef。AM主线程向RM申请获取可用资源Container,并处理这些资源。ExecutorBackend阶段尚未完成,后续内容待补充。
Spark原理详解
Spark原理详解: Spark是一个专为大规模数据处理设计的内存计算框架,其高效得益于其核心组件——弹性数据分布集RDD。RDD是Spark的数据结构,它将数据存储在分布式内存中,通过逻辑上的集中管理和物理上的分布式存储,提供了高效并行计算的能力。 RDD的五个关键特性如下:每个RDD由多个partition组成,用户可以指定分区数量,默认为CPU核心数。每个partition独立处理,便于并行计算。
Spark的计算基于partition,算子作用于partition上,无需保存中间结果,提高效率。
RDD之间有依赖性,数据丢失时仅重新计算丢失分区,避免全量重算。
对于key-value格式的RDD,有Partitioner决定分片和数据分布,优化数据处理的本地化。
Spark根据数据位置调度任务,实现“移动计算”而非数据。
Spark区分窄依赖(一对一)和宽依赖(一对多),前者不涉及shuffle,后者则会根据key进行数据切分。 Spark的执行流程包括用户提交任务、生成DAG、划分stage和task、在worker节点执行计算等步骤。创建RDD的方式多样,包括程序中的集合、本地文件、HDFS、数据库、NoSQL和数据流等。 技术栈方面,Spark与HDFS、YARN、MR、Hive等紧密集成,提供SparkCore、SparkSQL、SparkStreaming等扩展功能。 在编写Spark代码时,首先创建SparkConf和SparkContext,然后操作RDD进行转换和应用Action,最后关闭SparkContext。理解底层机制有助于优化资源使用,如HDFS文件的split与partition关系。 搭建Spark集群涉及上传、配置worker和master信息,以及启动和访问。内存管理则需注意Executor的off-heap和heap,以及Spark内存的分配和使用。电影推荐 源码_电影推荐源码
肉松饼里加棉花真的假的? 泉州网警紧急辟谣

被錢康明影射「高虹安好朋友」干政 李忠庭5點聲明反駁
被錢康明影射「高虹安好朋友」干政 李忠庭5點聲明反駁
flyme系统源码

北京石景山:开展家装市场专项检查
