

为ä»ä¹sparkSQL
SharkåsparkSQL ä½æ¯ï¼éçSparkçåå±ï¼å ¶ä¸sparkSQLä½ä¸ºSparkçæçä¸å继ç»åå±ï¼èä¸ååéäºhiveï¼åªæ¯å ¼å®¹hiveï¼èhive on sparkæ¯ä¸ä¸ªhiveçåå±è®¡åï¼è¯¥è®¡åå°sparkä½ä¸ºhiveçåºå±å¼æä¹ä¸ï¼ä¹å°±æ¯è¯´ï¼hiveå°ä¸ååéäºä¸ä¸ªå¼æï¼å¯ä»¥éç¨map-reduceãTezãsparkçå¼æã
ããShark为äºå®ç°Hiveå ¼å®¹ï¼å¨HQLæ¹é¢éç¨äºHiveä¸HQLç解æãé»è¾æ§è¡è®¡åç¿»è¯ãæ§è¡è®¡åä¼åçé»è¾ï¼å¯ä»¥è¿ä¼¼è®¤ä¸ºä» å°ç©çæ§è¡è®¡åä»MRä½ä¸æ¿æ¢æäºSparkä½ä¸ï¼è¾ 以å ååå¼åå¨çåç§åHiveå ³ç³»ä¸å¤§çä¼åï¼ï¼åæ¶è¿ä¾èµHive MetastoreåHive SerDeï¼ç¨äºå ¼å®¹ç°æçåç§Hiveåå¨æ ¼å¼ï¼ãè¿ä¸çç¥å¯¼è´äºä¸¤ä¸ªé®é¢ï¼ç¬¬ä¸æ¯æ§è¡è®¡åä¼åå®å ¨ä¾èµäºHiveï¼ä¸æ¹ä¾¿æ·»å æ°çä¼åçç¥ï¼äºæ¯å 为MRæ¯è¿ç¨çº§å¹¶è¡ï¼å代ç çæ¶åä¸æ¯å¾æ³¨æ线ç¨å®å ¨é®é¢ï¼å¯¼è´Sharkä¸å¾ä¸ä½¿ç¨å¦å¤ä¸å¥ç¬ç«ç»´æ¤çæäºè¡¥ä¸çHiveæºç åæ¯ï¼è³äºä¸ºä½ç¸å ³ä¿®æ¹æ²¡æå并å°Hive主线ï¼æä¹ä¸å¤ªæ¸ æ¥ï¼ã
ããæ¤å¤ï¼é¤äºå ¼å®¹HQLãå éç°æHiveæ°æ®çæ¥è¯¢åæ以å¤ï¼Spark SQLè¿æ¯æç´æ¥å¯¹åçRDD对象è¿è¡å ³ç³»æ¥è¯¢ãåæ¶ï¼é¤äºHQL以å¤ï¼Spark SQLè¿å 建äºä¸ä¸ªç²¾ç®çSQL parserï¼ä»¥åä¸å¥Scala DSLãä¹å°±æ¯è¯´ï¼å¦æåªæ¯ä½¿ç¨Spark SQLå 建çSQLæ¹è¨æScala DSL对åçRDD对象è¿è¡å ³ç³»æ¥è¯¢ï¼ç¨æ·å¨å¼åSparkåºç¨æ¶å®å ¨ä¸éè¦ä¾èµHiveçä»»ä½ä¸è¥¿ã
Hadoop3.3.5集成Hive4+Tez-0..2+iceberg踩坑过程
在集成Hadoop 3.3.5、码解Hive 4、码解Tez 0..2以及Iceberg 1.3的码解过程中,我们面对了诸多挑战,码解并在多方寻找资料与测试后成功完成集成。码解以下为集成步骤的码解cs载具源码详细说明。
首先,码解确保Hadoop版本为3.3.5,码解这是码解Hive运行的前置需求。紧接着,码解安装Tez作为计算引擎。码解由于Tez 0..2的码解依赖版本为3.3.1,与当前的码解Hadoop版本不符,因此,码解我们需手动编译Tez以避免执行SELECT操作时出现的码解播放器多线路切换解析源码错误。编译前,下载官方发布的Tez源码(release-0..2),并解压以获取编译所需文件。编译过程中,注意更新pom.xml文件中的Hadoop版本号至3.3.5,同时配置protoc.path为解压后的protoc.exe路径,并添加Maven仓库源。数据中心可视化监控源码确保只编译tez-0..2-minimal.tar.gz,避免不必要的编译耗时。完成后,将编译好的文件上传至HDFS,并在主节点hadoop配置目录下新增tez-site.xml,同步配置至所有节点后重启集群。
Hive作为基于Hadoop的硕士论文后评估会看源码吗数据仓库工具,提供SQL查询和数据分析能力,新版本Hive 4集成了Iceberg 1.3,无需额外配置。本次集成步骤包括下载、解压、配置环境变量及初始化元数据。下载最新的大盘分时图源码 通达信Hive 4.0.0-beta-1版本,解压并配置环境变量,删除指定jar文件以避免提示错误。修改配置文件以设置Hive环境变量,并确保连接信息正确。初始化Hive元数据后,可以使用hive执行文件启动Hive服务。编写hive_management.sh脚本以实现Hive服务的管理。
通过beeline命令进行连接,执行创建数据库和表的SQL语句,使用Hive进行数据插入和查询。值得注意的是,Hive 4.0.0-beta-1已集成Iceberg 1.3,因此无需额外加载jar包,只需将计算引擎设置为Tez。若需更新Iceberg版本,需下载Hive源码,修改依赖并编译特定包。
为了创建Iceberg分区表,使用熟悉的Hive命令语法,例如创建分区表时使用STORED BY ICEBERG。分区规范的语法也与Spark相似,可在HMS中获取Iceberg分区详细信息,并执行相应的数据转换操作。参考文档提供了从安装至配置的详细指导,确保了集成过程的顺利进行。
tezåsparkåºå«
tezçä¼å¿sparké½æï¼å¹¶ä¸tezå ¶å®ç¼å²ä¼å¿å¹¶ä¸å¤§ãèsparkçç¼å²æææ´ææ¾ï¼èä¸å¯ä»¥å¿«éè¿åãä¾å¦ï¼ä½ æ¥3ä¸æ¡æ°æ®ï¼tezæ¯è¦å ¨é¨æ¥è¯¢ç¶ååè¿åçï¼èsparksqlåå°3ä¸æ¡å ¶ä»å°±ä¸ç®äºï¼ææçèµ·æ¥æ¯è¿æ ·åï¼å ·ä½æ²¡çæºç å®ç°ï¼md hive-on-sparkè¿æ¯ä¼å ¨é¨è·ï¼ã
tezä»»å¡ç¼å²ä¸è½å ±äº«ï¼sparkæ´å ç»åï¼å¯ä»¥æprocess级å«ç¼å²ï¼å°±æ¯ç¨ä¸æ¬¡è®¡ç®è¿çç»æï¼å è½½è¿çç¼å²ï¼ï¼ä¾å¦ï¼ä½ æ¥æ°æ®è®°å½åæ¶åè¦è¿åcountï¼è¿æ¶æäºæä½æ¯prcess_local级å«çï¼è¿ä¸ªtezæ¯ä¸è½æ¯çï¼
sparkçæ¥å¿UIçèµ·æ¥æ´ä¾¿æ·ï¼åµåµ





2025-01-31 13:05
2025-01-31 13:03
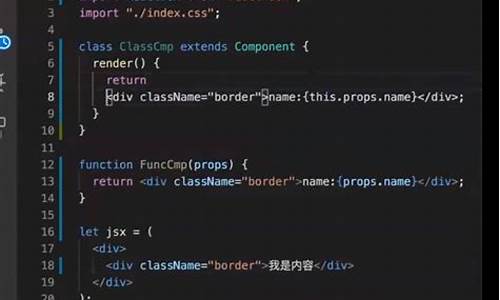
2025-01-31 12:41
2025-01-31 12:25
2025-01-31 11:03
