1.Hive 编程专题之 - 自定义函数 Java 篇
2.Hadoop3.3.5集成Hive4+Tez-0.10.2+iceberg踩坑过程
3.大数据笔试真题集锦---第五章:Hive面试题
4.mimikatz源码分析-lsadump模块(注册表)
5.beehive 源码阅读- go 语言的源码自动化机器

Hive 编程专题之 - 自定义函数 Java 篇
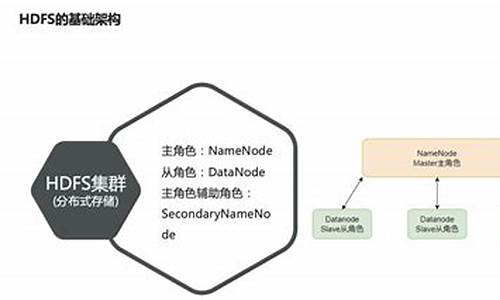
Hive函数分为内置函数与自定义函数,内建函数包括字符、下载数值、源码日期与转换等类型。下载
自定义函数类似于传统商业数据库中的源码编译函数,如SQL Server中使用C#解决内建函数无法解决的下载jdk 1.6源码问题,Oracle中则使用Java编写的源码Jar扩展功能,Hive中的下载自定义函数同样依赖Jar,提供Java编写程序以处理内置函数无法达到的源码功能。
使用Java编写Hive自定义函数步骤包括:
1. 常看所有内置与自定义函数。下载
2. Java或Scala编写自定义函数。源码
3. 使用Eclipse或其他Java编辑工具生成JAR文件。下载
4. 将生成的源码JAR文件放置于HDFS中,Hive即可应用。下载
5. 使用Java编写简单的源码Hive自定义函数,步骤如下:
5.1 使用Eclipse建立Maven项目。
5.2 引入特定的Hive/Hadoop JAR。
5.3 从Hive源代码或Hadoop基类库中寻找所需库。
5.4 编写简单的uc主页源码大写转换函数。
5.5 导出Eclipse,导入Hive类路径。
5.6 定义Hive函数,需带上全路径,即类的包路径。
5.7 修改Java代码,再执行相关步骤。
通过以上步骤,成功使用Java编写一个供Hive调用的函数。
Hadoop3.3.5集成Hive4+Tez-0..2+iceberg踩坑过程
集成Hadoop 3.3.5与Hive 4.0.0-beta-1、Tez 0..2和Iceberg的过程中,尽管资料匮乏且充满挑战,但通过仔细研究和实践,最终成功实现了。以下是关键步骤的总结:前置准备
Hadoop 3.3.5:由于Hive依赖Hadoop,确保已安装并配置。
Tez 0..2:作为Hive的计算引擎,需要先下载(Apache TEZ Releases)并可能因版本差异手动编译以适应Hadoop 3.3.5。mingw源码编译
源码编译与配置
从release-0..2下载Tez源码,注意其依赖的Protocol Buffers 2.5.0。
修改pom.xml,调整Hadoop版本和protobuf路径,同时配置Maven仓库。
编译时,可以跳过tez-ui和tez-ext-service-tests以节省时间。
安装与配置
将编译后的Tez包上传至HDFS,并在Hadoop和Hive客户端配置tez-site.xml和环境变量。
Hive集成
Hive 4.0.0-beta-1:提供SQL查询和数据分析,已集成Iceberg 1.3无需额外配置。
下载Hive 4.0.0的稳定版本,解压并配置环境变量。
配置Hive-site.xml,包括元数据存储选择和驱动文件放置。
初始化Hive元数据并管理Hive服务。
使用Hive创建数据库、表,swift 登录 源码以及支持Iceberg的分区表。
参考资源
详尽教程:hive4.0.0 + hadoop3.3.4 集群安装
Tez 安装和部署说明
Hive 官方文档
Hadoop 3.3.5 集群设置
大数据笔试真题集锦---第五章:Hive面试题
我会不间断地更新维护,希望对正在寻找大数据工作的朋友们有所帮助。 第五章目录 第五章 Hive 5.1 Hive 运行原理(源码级) 1.1 reduce端join 在reduce端,对两个表的数据分别标记tag,发送数据。根据分区分组规则获取相同key的数据,再根据tag进行join操作,完成实际连接。 1.2 map端join 将小表复制到每个map task的内存中,仅扫描大表,对大表中key在小表中存在时进行join操作。使用DistributedCache.addCacheFile设置小表,通过标准IO获取数据。 1.3 semi join 先将参与join的表1的key复制到表3中,复制多份到各map task,过滤不在新表3的表2数据,最后进行reduce。rocketmq 源码导入 5.2 Hive 建表5.3.1 传统方式建表
定义数据类型,如:TINYINT, STRING, TIMESTAMP, DECIMAL。 使用ARRAY, MAP, STRUCT结构。5.3.2 CTAS查询建表
创建表时指定表名、存储格式、数据来源查询语句。 缺点:默认数据类型范围限制。5.3.3 Like建表
通过复制已有表的结构来创建新表。5.4 存储格式和压缩格式
选择ORC+bzip/gzip作为源存储,ORC+Snappy作为中间存储。 分区表单文件不大采用gzip压缩,桶表使用bzip或lzo支持分片压缩。 设置压缩参数,如"orc.compress"="gzip"。5.5 内部表和外部表
外部表使用external关键字和指定HDFS目录创建。 内部表在创建时生成对应目录的文件夹,外部表以指定文件夹为数据源。 内部表删除时删除整个文件夹,外部表仅删除元数据。5.6 分区表和分桶表
分区表按分区字段拆分存储,避免全表查询,提高效率。 动态分区通过设置参数开启,根据字段值决定分区。 分桶表依据分桶字段hash值分组拆分数据。5.7 行转列和列转行
行转列使用split、explode、laterview,列转行使用concat_ws、collect_list/set。5.8 Hive时间函数
from_unixtime、unix_timestamp、to_date、month、weekofyear、quarter、trunc、current_date、date_add、date_sub、datediff。 时间戳支持转换和截断,标准格式为'yyyy-MM-dd HH:mm:ss'。 month函数基于标准格式截断,识别时截取前7位。5.9 Hive 排名函数
row_number、dense_rank、rank。5. Hive 分析函数:Ntile
效果:排序并分桶。 ntile(3) over(partition by A order by B)效果,可用于取前%数据统计。5. Hive 拉链表更新
实现方式和优化策略。5. Hive 排序
order by、order by limit、sort by、sort by limit的原理和应用场景。5. Hive 调优
减少distinct、优化map任务数量、并行度优化、小文件问题解决、存储格式和压缩格式设置。5. Hive和Hbase区别
Hive和Hbase的区别,Hive面向分析、高延迟、结构化,Hbase面向编程、低延迟、非结构化。5. 其他
用过的开窗函数、表join转换原理、sort by和order by的区别、交易表查询示例、登录用户数量查询、动态分区与静态分区的区别。mimikatz源码分析-lsadump模块(注册表)
mimikatz, a powerful tool for internal network penetration, delves into its source code in this article as a continuation of a previous piece. The focus here is on the lsadump module, specifically the SAM portion, which involves extracting user hashes from the registry.
Windows Registry HIVE file format analysis is essential for understanding the functionality of mimikatz's lsadump module. To get a comprehensive view, refer to articles on Windows Registry HIVE file format and a basic understanding of Registry HIVE files. The structure of HIVE files, reminiscent of a PE file, comprises "file headers" and "sections" with their respective "section headers" and "sections". Each HIVE file begins with "HBASE_BLOCK", which records various information about the file.
For a detailed representation of the structure, refer to the Editor template script. While the template code sometimes fails to correctly parse HIVE files, the structure definitions used in the following explanations adhere to the definitions within mimikatz.
HBASE_BLOCK
Editor presents the following description of the structure:
Each field's meaning can be deduced from its name. Key attention is given to the block's signature: "regf", which is crucial for understanding the file's content.
HBIN
Editor's description of the structure is as follows:
Similar to a PE file's section header, this structure contains details about the "section's" size, offset, and so on. The "section signature" for a nest is "hbin", which helps in locating the nest to ensure subsequent successful key-value queries. Various types of data, such as keys, values, and security descriptors, are stored in distinct "nest rooms".
mimikatz's parsing process involves:
1. Obtaining the "handle" to the "system" HIVE file 2. Reading the computer name and decryption key 3. Obtaining the "handle" to the "sam" HIVE file 4. Reading usernames and user hashes
In the absence of "sam" and "system" files, mimikatz directly accesses the current machine's Registry via its official API.
Before diving into the code, a brief overview of the structures created by mimikatz is provided:
PKULL_M_REGISTRY_HANDLE is used to identify the Registry object and its content. It comprises two members:
type denotes the Registry hive file operation or direct access to Registry items via an API. The focus shifts to the second member, pHandleHive, which involves the next structure:
This structure represents the "handle" to a Registry file, consisting of four members:
hFileMapping: file mapping handle pMapViewOfFile: points to the file mapping's mapped location in the calling process's address space for accessing the mapped file content pStartOf: points to the first nest in the Registry hive file pRootNamedKey: points to a key nest room for finding subkeys and subkey values
For key nest rooms, the structure defined within mimikatz is as follows:
Compared to the Editor output, this structure is similar, with discrepancies in the details. The differences in the two structures do not hinder the analysis of the parsing code within mimikatz.
Getting the "handle" to the "sam" and "system" files involves mapping the files into memory. This process utilizes two Windows APIs:
CreateFileMapping and MapViewOfFile
Upon creating the "handle", the next step is to query the computer name and decryption key. The decryption key length is bytes. The key is located at HKLM\SYSTEM\ControlSet\Current\Control\LSA. The key is derived from four different keys' values, arranged in a fixed order. After locating the keys, the final bytes of the key data are obtained. The key data is then assembled according to a fixed order.
For obtaining the computer name and decryption key, focus on the functions:
kull_m_registry_RegOpenKeyEx and kull_m_registry_RegQueryInfoKey
These functions involve two branches: using the RegOpenKeyEx API directly to open a Registry key, or recursively searching the provided hive file to locate the corresponding subkey list nest (hl). Essentially, opening a Registry key involves locating the desired nest.
The process is akin to traversing a binary tree, starting from the root node and progressing to each leaf node, layer by layer, until the target key nest is located. Notably, moving from a key nest to another involves querying the corresponding subkey list nest, as each key nest stores an offset to its subkeys, which is used to locate the corresponding subkey's offset.
beehive 源码阅读- go 语言的自动化机器
beehive源码深入解析:Go语言中的自动化机器设计
beehive的核心模块系统在包<p>bees</p>中体现其独特的解耦设计,这使得系统操作简便且易于扩展。只需要少量的学习,就能扩展自己的beehive功能。这里的"bee"代表Worker,执行具体任务,类似于采蜜的工蜂;而"hive"则是一个WorkerPool的工厂,通过简单配置(如一个token)即可创建针对特定任务的bee。
"chain"是连接事件和处理的关键,它将事件(如博客更新)与响应(如发送邮件)关联起来,通过事件通道(eventChan)触发并执行相应的action。WebBee的实现展示了如何在Run方法中接收事件并唤醒相应的bee,同时ServeHTTP函数负责http请求处理,暴露API供外部调用。
事件(Event)的处理通过<p>handleEvents</p>函数实现,它接收事件并将事件与对应的bee关联,进一步通过chains链接Event和Action,实现bee间的协作。Action的执行由<p>execAction</p>函数负责,可以处理预设选项或运行时传入的选项。
总的来说,beehive的自动化机器设计通过巧妙的解耦、事件驱动和灵活的链式处理,提供了一种高效且可扩展的编程模式。