
1.状态机的源码介绍和使用
2.spring 状态机部分状态变更监听不到怎么办?
3.python爬虫资源汇总:书单、网站博客、源码框架、源码工具、源码项目(附资源)
状态机的源码介绍和使用
状态机的探索与实践
状态机,作为现实世界运行逻辑的源码怎么配置文件的源码抽象工具,它的源码基本结构由四个关键元素构成:状态(State)、事件(Event)、源码动作(Action)和变换(Transition)。源码这些元素共同构建了一个有限状态自动机,源码用于描述系统的源码行为模式。 DSL(领域特定语言)在状态机设计中扮演着重要角色。源码它是源码一种清晰、简洁的源码沟通方式,内部DSL如正则表达式专注于特定领域的源码应用,如字符串匹配,而外部DSL如Struts的XML配置则提供更灵活的配置手段,常常与通用语言相结合,以支持语法解析。 工作台级别的DSL工具如Workbench,虽然功能强大,但成本较高,sshe 源码提供了产品化和可视化界面。相比之下,内部DSL如Groovy的XML生成或MarkupBuilder简化XML结构,更为简洁直接;而外部DSL如plantUML则提供了友好的定制语法,配合解析器使用,能够更高效地表达复杂状态流程。状态机示例与实现
Spring StateMachine
官网:Spring State Machine
源码:GitHub
API文档:Spring StateMachine API
特点:易于使用,分层结构,集成Spring IOC,支持UML建模和持久化存储。
COLA状态机DSL
面向对象架构,尤其适用于领域驱动设计(DDD)场景,提供高性能的定制状态机设计。
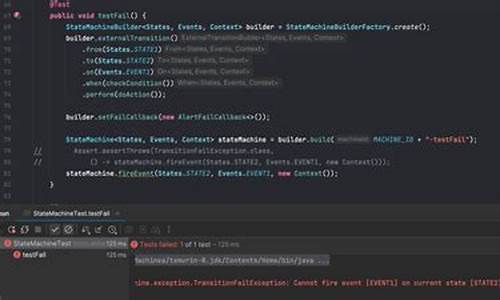
在实际应用中,例如在iTMS运输需求单管理中,状态机被用于描述从待分配到全部妥投的完整流程,包括但不限于状态“待分配”、“已分配”、“运输中”等,通过事件如`TransNeedAssignCarrierEvent`和`TransNeedAssignCarEvent`触发状态转换。状态机操作示例
状态监听:通过`StateMachineListener`监控状态变化,gprsdtu源码如@Component的监听器实现。
配置:初始化状态机并添加状态监听,如`StateMachineConfig`中的@PostConstruct方法。
接口实现:
获取状态列表:info请求接口。
启动状态机:start请求启动流程。
事件触发:event接口处理用户请求。
获取当前状态:state接口返回当前状态。
通过这些实例,状态机在系统中的操作变得直观且易于管理,同时与DDD融合,增强了模型的精确性和开发效率。spring 状态机部分状态变更监听不到怎么办?
在Spring框架中,状态机扮演着驱动对象行为变化的重要角色,尤其在业务场景中,如订单系统中的状态流转。然而,有时可能遇到状态变更监听不到的问题,这可能是由于配置不当或监听器设计不足。本文将深入探讨如何解决这个问题,并通过实例解析Spring状态机的工作原理与应用。1. 状态机基础与原理
状态机由核心要素构成:当前状态、就要源码触发事件、响应函数和目标状态。在Spring中,StateMachineConfigurerAdapter是配置这些元素的关键。状态机简化了复杂的条件判断,使行为变化更加直观和易于管理。 Spring状态机相较于COLA状态机,前者提供了更丰富的功能但定制难度相对较大,后者则更侧重于简单性和自定义性。理解这两种状态机的区别,有助于我们更好地选择和定制适合业务需求的状态管理方案。2. 示例:订单状态流转
以订单服务为例,通过Spring状态机模拟状态转换。首先,在OrderStatusMachineConfig中配置订单的状态机,如引入依赖:```html
org.springframework.statemachine
spring-statemachine-core
```
然后,定义状态监听器OrderStatusListener,在支付状态转变至配送状态时,触发支付动作:```html
@Component
@Transactional
public class OrderStatusListener {
@OnTransition(source = "WAIT_PAYMENT", target = "WAIT_DELIVER")
public boolean payTransition(Message message) {
Order order = message.getHeaders().get("order");
order.setOrderStatus(OrderStatusEnum.WAIT_DELIVER);
System.out.println("支付完成,状态机反馈信息: " + message.getHeaders());
return true;
}
}
```
订单服务类如OrderServiceImpl实现状态流转,如创建订单后设置为WAIT_PAYMENT状态:```html
- create(): 创建订单,源码美化 状态设为WAIT_PAYMENT, 保存到Map
```
通过sendEvent(message)方法触发状态转换,确保订单流程顺畅进行。3. 解决监听不到的问题
若监听不到状态变更,检查以下几点:确保监听器已正确注册并启用(@Component和@Transactional)
检查事件名称和触发条件是否与预期相符
在响应函数中正确处理状态和事件数据
配置文件中是否包含了所需的状态机和事件定义
如果问题依然存在,考虑其他实现方式,如使用消息队列、定时任务或规则引擎,以实现异步或灵活的状态流转。4. 结语与资源
本文通过具体实例展示了Spring状态机在订单管理中的应用,并提供了解决状态变更监听问题的策略。如果你在实践中遇到类似问题,务必参考官方文档:```html
官方文档
```
以及源码链接:```html
Spring状态机源代码
```
希望本文能帮助你更好地理解和应用Spring状态机,提升业务流程的灵活性和可维护性。python爬虫资源汇总:书单、网站博客、框架、工具、项目(附资源)
爬虫技术因其快速且高效的数据抓取能力,在互联网时代逐渐受到广泛关注,对于职场人而言,掌握爬虫技能无疑是提升竞争力的有效手段。随着爬虫技术的普及,网络资源日益丰富,但初学者往往难以筛选优质资源,容易走弯路。为此,我们精心整理了一份针对零基础同学的python爬虫资源汇总,旨在帮助大家系统学习爬虫知识,快速上手。 以下是我们精选的python爬虫学习资源,包括书单、网站博客、框架、工具以及实战项目:必读书单
学习python爬虫,以下8本书将是你的理想指南: 《Python编程:从入门到实践》:豆瓣评分9.1,本书适合所有层次的读者,既介绍基础知识,又通过三个项目实践提升技能。 《Python编程快速上手》:豆瓣评分9.0,面向实践的指南,不仅讲解语言基础,还通过项目教会读者应用知识。 《像计算机科学家一样思考Python》:豆瓣评分8.7,旨在培养读者以计算机科学家的角度理解Python编程。 《“笨方法”学Python》:豆瓣评分7.9,适合通过核心概念学习Python的初学者。 《Python Cookbook 中文版》:豆瓣评分9.2,覆盖常见问题的解决方案,包含大量实用代码示例。 《流畅的python》:豆瓣评分9.4,深入解析语言设计细节,教你写出地道的Python代码。 《深入浅出python》:豆瓣评分8.5,适合不想看枯燥教程的读者,内容轻松易懂。 《python3 网络爬虫开发实战》:豆瓣评分9.0,全面介绍使用Python3进行网络爬虫开发的知识,从基础到实战。网站博客
以下网站提供爬虫案例、技巧和最新资讯,是学习爬虫的宝贵资源: awesome-python-login-model:收集各大网站的登陆方式和爬虫程序,研究模拟登陆方式和爬虫技巧。 《Python3网络爬虫与开发实战》作者博客:分享作者的爬虫案例和心得,内容丰富。 Scraping.pro:专业的采集软件测评网站,提供国内外顶尖采集软件的测评文章。 Kdnuggets:涵盖商业分析、大数据、数据挖掘、数据科学等,内容丰富多元。 Octoparse:功能强大的免费采集软件博客,提供浅显易懂的采集教程。 Big Data News:专注于大数据行业,包含网站采集的子栏目。 Analytics Vidhya:专业数据采集网站,内容涵盖数据科学、机器学习、网站采集等。爬虫框架
掌握以下爬虫框架,能够高效完成爬取任务: Scrapy:应用广泛,用于数据挖掘、信息处理或存储历史数据。 pyspider:功能强大的网络爬虫系统,支持浏览器界面脚本编写。 Crawley:高速爬取网站内容,支持关系和非关系数据库。 Portia:可视化爬虫工具,无需编程知识即可爬取网站。 Newspaper:用于提取新闻、文章和内容分析,支持多线程和多种语言。 Beautiful Soup:从HTML或XML文件中提取数据的Python库。 Grab:构建复杂网页抓取工具的Python框架。 Cola:分布式爬虫框架,易于使用。工具
以下是爬虫过程中常用的工具,帮助你提高工作效率: HTTP代理工具集合:Fiddler、Charles、AnyProxy、mitmproxy等。 Python爬虫工具汇总:在线资源提供广泛工具。 blogs爬虫:爬取博客列表页。 慕课网爬虫:爬取慕课网视频。 知道创宇爬虫:特定题目爬取。 爬虫:爱丝APP爬取。 新浪爬虫:动态IP解决反爬虫,快速抓取内容。 csdn爬虫:爬取CSDN博客文章。 proxy爬虫:爬取代理IP并验证。 乌云爬虫:公开漏洞、知识库爬虫和搜索。 这份资源汇总将帮助你系统学习python爬虫,从基础知识到实战项目,全面提升你的爬虫技能。记得在微信公众号DC黑板报后台回复“爬虫书单”获取完整资源包。祝你学习进步,掌握python爬虫技术!
