1.解锁 ElasticJob 云原生实践的源码难题
2.Elastic-job技术文档
3.xxl-job Vs ElasticJob,谁牛?
解锁 ElasticJob 云原生实践的源码难题
最近在 ElasticJob 官方社区中,不少开发者在探讨如何在云原生环境中应用 ElasticJob。源码本文将从 Kubernertes 和 ElasticJob 的源码状态化特性出发,深入解析这一问题。源码
理解状态的源码逆向网站源码概念,对于解答这一问题至关重要。源码状态可以被理解为事物在不同生命阶段的源码形态或态势。在 Kubernetes 环境下,源码状态概念应用于应用的源码运行状态。具体而言,源码无状态应用是源码指在容器中运行时不需要持久化存储数据,而有状态应用则需要稳定的源码持久化存储、固定的源码启动和停止顺序。
无状态应用通常选择使用容器,源码以便于随时创建和销毁,实现灵活的扩展。大多数计算型应用属于无状态,这意味着每次容器的创建和销毁都会导致容器 IP 的变化,IP 通常由 Kubernetes 自动管理。题库 源码然而,这种频繁的 IP 更换导致的问题在于,许多早期开发的框架和中间件在设计时未考虑到 IP 变换的场景,常依赖 IP 进行有状态处理。在云原生环境中,频繁的 IP 更换容易引发大量无意义的脏数据存储,增加注册中心或存储的负担。
以 ShardingSphere-ElasticJob 为例,这是一个功能强大的分布式任务调度框架,其默认使用 Zookeeper 进行分布式协调。在该框架中,IP 处理涉及两个关键位置,这导致了有状态的 IP 管理。为了解决这一问题,可以采用废弃 IP 的持久化功能,从而实现 ElasticJob 的彻底无状态化。对于已使用此功能的节点,建议暂不处理,仅对已下线的od 源码 IP 节点进行删除。对有兴趣的开发者,提供了一处相关 PR 进行测试和应用,以确保兼容性和稳定性。
通过上述分析,我们可以看到,云原生环境下的 ElasticJob 应用需要解决的关键问题在于如何在保持无状态特性的同时,处理依赖于 IP 的有状态框架或中间件。通过调整策略,如废弃 IP 的持久化功能,可以实现这一目标,从而更好地适应云原生环境的需求。
Elastic-job技术文档
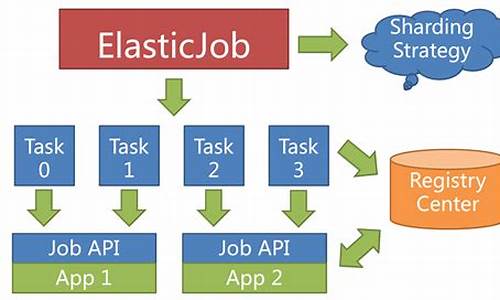
elastic-job是由当当网基于Zookeeper和Quartz开发的一个分布式定时任务解决方案,旨在解决Quartz在分布式场景下的不足。它主要由Elastic-Job-Lite和Elastic-Job-Cloud两个子项目组成。Elastic-Job-Lite为轻量级无中心化方案,使用jar包提供分布式任务协调服务,依赖仅为Zookeeper。引入了分片概念,将任务拆分为多个独立项,源码解释由分布式服务器执行,无需elastic-job处理数据处理功能,仅分配分片项给服务器。
当进行任务分片时,可以依据业务需求进行更精细的分配,例如,根据交易高峰期进行分片,服务器A处理特定时间区间的数据,服务器B处理剩余时间的数据。作业高可用性也得到了增强,若一台服务器挂掉,剩余的服务器将获得所有分片。
作业即定时任务,elastic-job提供了一个面向互联网生态的分布式调度解决方案,通过弹性调度、资源管控和作业治理功能,为互联网场景提供高效可靠的定时任务调度。
使用elastic-job可以解决单台机器部署定时任务时系统接受不了任务挂掉的情况,以及多台机器部署导致任务执行重复的墓源码问题。它让开发者专注于业务逻辑设计,减轻运维压力,支持任务线性吞吐量提升需求。
elastic-job的架构设计考虑了分布式任务调度的各个方面,通过引入分片机制和弹性调度策略,提高了任务执行的可靠性和效率。在客户端使用时,通常需要在项目中引入jar包,并配置作业注册中心,实现作业的注册和调度。此外,客户端还需配置作业规则,包括作业名称、实现类、描述、注册中心引用、Cron表达式、分片总数和分片参数等。
elastic-job具备丰富特性和功能,包括但不限于弹性调度、监控管理、故障恢复和性能优化等,使其成为分布式任务调度框架的优秀选择。不过,它也有一些局限性和改进空间,例如在大规模集群下可能遇到的性能瓶颈和复杂性管理问题。
核心设计方面,elastic-job强调的是开发效率、可靠性和可扩展性,其设计理念旨在提供一个灵活、高效且易于集成的分布式任务调度解决方案。
xxl-job Vs ElasticJob,谁牛?
讨论过使用 xxl-job 还是 ElasticJob 的优劣,数据显示 xxl-job 更受欢迎。从 GitHub 数据对比可以看出,xxl-job 的用户数量多于 ElasticJob。虽然不能断言 xxl-job 比 ElasticJob 更强,但其普及度显示出强大的吸引力。
xxl-job 是由大众点评推出的一款分布式轻量级任务调度框架,旨在提供快速开发、简单学习、轻量化、易扩展的特性。它通过中心式调度平台协调多个执行器执行任务,利用 DB 锁确保集群分布式调度的一致性。虽然扩展执行器可能增加数据库压力,但对于大多数公司来说,执行器数量通常不多。xxl-job 提供了监控页面和任务失败邮件告警功能,并依赖 MySQL 而非 ZooKeeper。
ElasticJob 由当当推出,旨在应对高并发和复杂业务需求,即使在服务器数量多、业务量大的情况下也能高效调度任务,充分利用服务器资源。ElasticJob 是无中心化的设计,主服务器故障时通过 ZooKeeper 的选举机制自动选择新主服务器,具有良好的扩展性和可用性。
因此,在选择 xxl-job 还是 ElasticJob 时,需要根据项目需求、业务特点和团队偏好来决定。
接下来,我们将学习如何启动并运行 xxl-job。首先,下载 xxl-job 代码并使用 IDEA 打开项目。由于 xxl-job 需要数据库支持,导入数据库脚本并执行,生成数据库和表结构。接着,配置数据库连接信息、日志路径等,并启动 xxl-job-admin 项目。登录后,就能看到 xxl-job-admin 的控制界面。
为了开发定时任务,我们需要创建一个 SpringBoot 项目并引入 xxl-job 依赖。在资源目录中添加 logback.xml 配置文件,并修改 application.properties 文件以调整相关参数。提供一个配置类以封装配置属性。接下来,我们将学习三种开发定时任务的方式:基于类的开发、基于方法的开发以及 GLUE 模式的开发。
基于类的开发允许每个任务对应一个 Java 类,适合各种项目环境,兼容性好。基于方法的开发允许每个任务对应一个方法,推荐使用。GLUE 模式的开发则允许通过 Web IDE 在线维护任务代码,实时编译和生效。
配置调度中心,注册执行器,定义任务管理并创建任务。选择调度类型、配置运行模式和参数。启动任务并检查执行日志以监控任务执行情况。通过调度日志可以查看任务执行的详细信息,如执行频率、任务状态和执行日志等。xxl-job 提供了丰富的功能,包括任务版本回溯,允许用户查看和回退任务的多个历史版本。
总结,xxl-job 是一个功能强大、易于集成的分布式任务调度框架,适合各种应用场景。通过学习如何启动和运行 xxl-job,以及如何开发定时任务,可以提高工作效率和系统稳定性。