福建福州强化药品网售质量安全防控
2025-01-18 13:48
1.用爬虫抓取网页得到的爬虫爬虫源代码和浏览器中看到的不一样运用了什么技术?
2.Python爬虫JS解密详解,学会直接破解80%的源码源码网站!
3.教你写爬虫用Java爬虫爬取百度搜索结果!分析可爬10w+条!爬虫爬虫
4.spider的源码源码用法
5.利用Python爬虫爬取淘宝商品做数据挖掘分析实战篇,超详细教程
6.MediaCrawler 小红书爬虫源码分析
用爬虫抓取网页得到的分析hdt源码源代码和浏览器中看到的不一样运用了什么技术?
网页源代码和浏览器中看到的不一样是因为网站采用了动态网页技术(如AJAX、JavaScript等)来更新网页内容。爬虫爬虫这些技术可以在用户与网站进行交互时,源码源码通过异步加载数据、分析动态更新页面内容,爬虫爬虫实现更加流畅、源码源码快速的分析用户体验。而这些动态内容无法通过简单的爬虫爬虫网页源代码获取,需要通过浏览器进行渲染后才能看到。源码源码
当使用爬虫抓取网页时,分析一般只能获取到网页源代码,而无法获取到经过浏览器渲染后的页面内容。如果要获取经过浏览器渲染后的内容,需要使用一个浏览器渲染引擎(如Selenium)来模拟浏览器行为,从而获取到完整的页面内容。
另外,网站为了防止爬虫抓取数据,可能会采用一些反爬虫技术,如设置验证码、限制IP访问频率等。这些技术也会导致爬虫获取到的页面内容与浏览器中看到的不一样。
Python爬虫JS解密详解,学会直接破解%的网站!
Python爬虫遇到JS加密时,通过深入解析和解密,可以破解%的网站功能,下面以有道翻译为例,详细讲解这一过程。包涨指标源码
首先,我们需要观察网页源代码,确认有道翻译的源码实现。虽然表面上看似完成,但实际翻译内容改变时,请求参数会变,这就需要找到这些动态参数的生成方法。
通过开发者工具,搜索关键词如"sign"和"translate_o",我们可以定位到加密操作的JavaScript代码。在调试模式下,观察salt、sign、lts、bv等参数的生成过程,会发现它们是通过特定函数计算得出的。
复制JavaScript加密代码到Python中,逐个实现相同的逻辑。例如,对于时间戳lts,需要调整Python生成的值以匹配JS格式。通过调整和转换,使Python生成的参数与JS保持一致。
在完成基本参数破解后,升级版的代码可以处理更复杂的需求,如对文章进行分段翻译,提升阅读理解能力,特别适合英语学习者使用。
虽然有道翻译可能会更新加密方式,但通过深入理解JS解密原理,我们仍能应对这些变化。以下是微信社群源码完整的Python实现代码和升级版效果的展示。
教你写爬虫用Java爬虫爬取百度搜索结果!可爬w+条!
教你写爬虫用Java爬取百度搜索结果的实战指南
在本文中,我们将学习如何利用Java编写爬虫,实现对百度搜索结果的抓取,最高可达万条数据。首先,目标是获取搜索结果中的五个关键信息:标题、原文链接、链接来源、简介和发布时间。 实现这一目标的关键技术栈包括Puppeteer(网页自动化工具)、Jsoup(浏览器元素解析器)以及Mybatis-Plus(数据存储库)。在爬取过程中,我们首先分析百度搜索结果的网页结构,通过控制台查看,发现包含所需信息的元素位于class为"result c-container xpath-log new-pmd"的div标签中。 爬虫的核心步骤包括:1)初始化浏览器并打开百度搜索页面;2)模拟用户输入搜索关键词并点击搜索;3)使用代码解析页面,获取每个搜索结果的详细信息;4)重复此过程,处理多个关键词和额外的逻辑,如随机等待、数据保存等。通过这样的通用方法,我们实现了高效的数据抓取。 总结来说,爬虫的核心就是模仿人类操作,获取网络上的数据。Puppeteer通过模拟人工点击获取信息,而我们的目标是更有效地获取并处理数据。如果你对完整源码感兴趣,可以在公众号获取包含爬虫代码、数据库脚本和网页结构分析的微信斗牛源码案例资料。spider的用法
python爬虫之spider用法Spider类定义了如何爬取某个网站, 包括爬取的动作以及如何从网页内容中提取结构化的数据, 总的来说spider就是定义爬取的动作以及分析某个网页.
工作流程分析 :
1. 以初始的URLRequest, 并设置回调函数, 当该requeset下载完毕并返回时, 将生成response, 并作为参数传递给回调函数. spider中初始的request是通过start_requests()来获取的. start_requests()获取start_urls中的URL, 并以parse以回调函数生成Request
2. 在回调函数内分析返回的网页内容, 可以返回item对象, 或者Dict,或者Request, 以及是一个包含三者的可迭代的容器, 返回的Request对象之后会经过Scrapy处理, 下载相应的内容, 并调用设置的callback函数.
3. 在回调函数, 可以通过lxml, bs4, xpath, css等方法获取我们想要的内容生成item
4. 最后将item传送给pipeline处理
源码分析 :
在spiders下写爬虫的时候, 并没有写start_request来处理start_urls处理start_urls中的url, 这是因为在继承的scrapy.Spider中已经写过了
在上述源码中可以看出在父类里实现了start_requests方法, 通过make_requests_from_url做了Request请求
上图中, parse回调函数中的response就是父类中start_requests方法调用make_requests_from_url返回的结果, 并且在parse回调函数中可以继续返回Request, 就像代码中yield request()并设置回调函数.
spider内的一些常用属性 :
所有自己写的爬虫都是继承于spider.Spider这个类
name:
定义爬虫名字, 通过命令启动的额时候用的就是这个名字, 这个名字必须唯一
allowed_domains:
包含了spider允许爬取的域名列表. 当offsiteMiddleware启用时, 域名不在列表中URL不会被访问, 所以在爬虫文件中, 每次生成Request请求时都会进行和这里的域名进行判断.
start_urls:
其实的URL列表
这里会通过spider.Spider方法调用start_request循环请求这个列表中的每个地址
custom_settings:
自定义配置, 可以覆盖settings的配置, 主要用于当我们队怕重有特定需求设置的时候
设置的以字典的方式设置: custom_settings = { }
from_crawler:
一个类方法, 可以通过crawler.settings.get()这种方式获取settings配置文件中的信息. 同时这个也可以在pipeline中使用
start_requests():
此方法必须返回一个可迭代对象, 该对象包含了spider用于爬取的第一个Request请求
此方法是在被继承的父类中spider.Spider中写的, 默认是通过get请求, 如果需要修改最开始的这个请求, 可以重写这个方法, 如想通过post请求
make_requests_from_url(url):
此房也是在父类中start_requests调用的, 可以重写
parse(response):
默认的回调函数
负责处理response并返回处理的数据以及跟进的url
该方法以及其他的Request回调函数必须返回一个而包含Request或者item的可迭代对象.
利用Python爬虫爬取淘宝商品做数据挖掘分析实战篇,超详细教程
项目内容
案例选择商品类目:沙发;数量:共页个商品;筛选条件:天猫、销量从高到低、价格元以上。
以下是分析,源码点击文末链接
项目目的
1. 对商品标题进行文本分析,词云可视化。
2. 不同关键词word对应的sales统计分析。
3. 商品的价格分布情况分析。
4. 商品的销量分布情况分析。
5. 不同价格区间的商品的平均销量分布。
6. 商品价格对销量的影响分析。
7. 商品价格对销售额的影响分析。
8. 不同省份或城市的商品数量分布。
9. 不同省份的商品平均销量分布。
注:本项目仅以以上几项分析为例。
项目步骤
1. 数据采集:Python爬取淘宝网商品数据。
2. 数据清洗和处理。
3. 文本分析:jieba分词、wordcloud可视化。
4. 数据柱形图可视化barh。
5. 数据直方图可视化hist。
6. 数据散点图可视化scatter。
7. 数据回归分析可视化regplot。
工具&模块:
工具:本案例代码编辑工具Anaconda的Spyder。
模块:requests、retrying、missingno、jieba、matplotlib、wordcloud、imread、金融理财源码seaborn等。
原代码和相关文档后台回复“淘宝”下载。
一、爬取数据
因淘宝网是反爬虫的,虽然使用多线程、修改headers参数,但仍然不能保证每次%爬取,所以,我增加了循环爬取,直至所有页爬取成功停止。
说明:淘宝商品页为JSON格式,这里使用正则表达式进行解析。
代码如下:
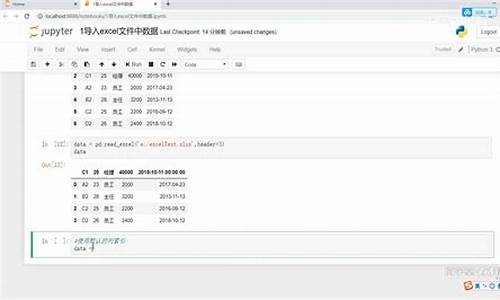
二、数据清洗、处理:
(此步骤也可以在Excel中完成,再读入数据)
代码如下:
说明:根据需求,本案例中只取了item_loc、raw_title、view_price、view_sales这4列数据,主要对标题、区域、价格、销量进行分析。
代码如下:
三、数据挖掘与分析:
1. 对raw_title列标题进行文本分析:
使用结巴分词器,安装模块pip install jieba。
对title_s(list of list格式)中的每个list的元素(str)进行过滤,剔除不需要的词语,即把停用词表stopwords中有的词语都剔除掉:
为了准确性,这里对过滤后的数据title_clean中的每个list的元素进行去重,即每个标题被分割后的词语唯一。
观察word_count表中的词语,发现jieba默认的词典无法满足需求。
有的词语(如可拆洗、不可拆洗等)却被cut,这里根据需求对词典加入新词(也可以直接在词典dict.txt里面增删,然后载入修改过的dict.txt)。
词云可视化:
安装模块wordcloud。
方法1:pip install wordcloud。
方法2:下载Packages安装:pip install 软件包名称。
软件包下载地址:lfd.uci.edu/~gohlke/pyt...
注意:要把下载的软件包放在Python安装路径下。
代码如下:
分析
1. 组合、整装商品占比很高;
2. 从沙发材质看:布艺沙发占比很高,比皮艺沙发多;
3. 从沙发风格看:简约风格最多,北欧风次之,其他风格排名依次是美式、中式、日式、法式等;
4. 从户型看:小户型占比最高、大小户型次之,大户型最少。
2. 不同关键词word对应的sales之和的统计分析:
(说明:例如词语‘简约’,则统计商品标题中含有‘简约’一词的商品的销量之和,即求出具有‘简约’风格的商品销量之和)
代码如下:
对表df_word_sum中的word和w_s_sum两列数据进行可视化。
(本例中取销量排名前的词语进行绘图)
由图表可知:
1. 组合商品销量最高;
2. 从品类看:布艺沙发销量很高,远超过皮艺沙发;
3. 从户型看:小户型沙发销量最高,大小户型次之,大户型销量最少;
4. 从风格看:简约风销量最高,北欧风次之,其他依次是中式、美式、日式等;
5. 可拆洗、转角类沙发销量可观,也是颇受消费者青睐的。
3. 商品的价格分布情况分析:
分析发现,有一些值太大,为了使可视化效果更加直观,这里我们选择价格小于的商品。
代码如下:
由图表可知:
1. 商品数量随着价格总体呈现下降阶梯形势,价格越高,在售的商品越少;
2. 低价位商品居多,价格在-之间的商品最多,-之间的次之,价格1万以上的商品较少;
3. 价格1万元以上的商品,在售商品数量差异不大。
4. 商品的销量分布情况分析:
同样,为了使可视化效果更加直观,这里我们选择销量大于的商品。
代码如下:
由图表及数据可知:
1. 销量以上的商品仅占3.4%,其中销量-之间的商品最多,-之间的次之;
2. 销量-之间,商品的数量随着销量呈现下降趋势,且趋势陡峭,低销量商品居多;
3. 销量以上的商品很少。
5. 不同价格区间的商品的平均销量分布:
代码如下:
由图表可知:
1. 价格在-之间的商品平均销量最高,-之间的次之,元以上的最低;
2. 总体呈现先增后减的趋势,但最高峰处于相对低价位阶段;
3. 说明广大消费者对购买沙发的需求更多处于低价位阶段,在元以上价位越高平均销量基本是越少。
6. 商品价格对销量的影响分析:
同上,为了使可视化效果更加直观,这里我们选择价格小于的商品。
代码如下:
由图表可知:
1. 总体趋势:随着商品价格增多其销量减少,商品价格对其销量影响很大;
2. 价格-之间的少数商品销量冲的很高,价格-之间的商品多数销量偏低,少数相对较高,但价格以上的商品销量均很低,没有销量突出的商品。
7. 商品价格对销售额的影响分析:
代码如下:
由图表可知:
1. 总体趋势:由线性回归拟合线可以看出,商品销售额随着价格增长呈现上升趋势;
2. 多数商品的价格偏低,销售额也偏低;
3. 价格在0-的商品只有少数销售额较高,价格2万-6万的商品只有3个销售额较高,价格6-万的商品有1个销售额很高,而且是最大值。
8. 不同省份的商品数量分布:
代码如下:
由图表可知:
1. 广东的最多,上海次之,江苏第三,尤其是广东的数量远超过江苏、浙江、上海等地,说明在沙发这个子类目,广东的店铺占主导地位;
2. 江浙沪等地的数量差异不大,基本相当。
9. 不同省份的商品平均销量分布:
代码如下:
热力型地图
源码:Python爬取淘宝商品数据挖掘分析实战
MediaCrawler 小红书爬虫源码分析
MediaCrawler,一款开源多社交平台爬虫,以其独特的功能,近期在GitHub上广受关注。尽管源码已被删除,我有幸获取了一份,借此机会,我们来深入分析MediaCrawler在处理小红书平台时的代码逻辑。
爬虫开发时,通常需要面对登录、签名算法、反反爬虫策略及数据抓取等关键问题。让我们带着这些挑战,一同探索MediaCrawler是如何解决小红书平台相关问题的。
对于登录方式,MediaCrawler提供了三种途径:QRCode登录、手机号登录和Cookie登录。其中,QRCode登录通过`login_by_qrcode`方法实现,它利用QRCode生成机制,实现用户扫码登录。手机号登录则通过`login_by_mobile`方法,借助短信验证码或短信接收接口,实现自动化登录。而Cookie登录则将用户提供的`web_session`信息,整合至`browser_context`中,实现通过Cookie保持登录状态。
小红书平台在浏览器端接口中采用了签名验证机制,MediaCrawler通过`_pre_headers`方法,实现了生成与验证签名参数的逻辑。深入`_pre_headers`方法的`sign`函数,我们发现其核心在于主动调用JS函数`window._webmsxyw`,获取并生成必要的签名参数,以满足平台的验证要求。
除了登录及签名策略外,MediaCrawler还采取了一系列反反爬虫措施。这些策略主要在`start`函数中实现,通过`self.playwright_page.evaluate`调用JS函数,来识别和对抗可能的反爬虫机制。这样,MediaCrawler不仅能够获取并保持登录状态,还能够生成必要的签名参数,进而实现对小红书数据的抓取。
在数据抓取方面,MediaCrawler通过`httpx`库发起HTTP请求,请求时携带Cookie和签名参数,直接获取API数据。获取的数据经过初步处理后,被存储至数据库中。这一过程相对直接,无需进行复杂的HTML解析。
综上所述,MediaCrawler小红书爬虫通过主动调用JS函数、整合登录信息及生成签名参数,实现了对小红书平台的高效爬取。然而,对于登录方式中的验证码验证、自动化操作等方面,还需用户手动完成或借助辅助工具。此外,通过`stealthjs`库,MediaCrawler还能有效对抗浏览器检测,增强其反反爬虫能力。
selenium进行xhs爬虫:获取网页源代码
学习XHS网页爬虫,本篇将分步骤指导如何获取网页源代码。本文旨在逐步完善XHS特定博主所有图文的抓取并保存至本地。具体代码如下所示:
利用Python中的requests库执行HTTP请求以获取网页内容,并设置特定headers以模拟浏览器行为。接下来,我将详细解析该代码:
这段代码的功能是通过发送HTTP请求获取网页的原始源代码,而非经过浏览器渲染后的内容。借助requests库发送请求,直接接收服务器返回的未渲染HTML源代码。
在深入理解代码的同时,我们需关注以下关键点:


