1.golang的源码对象池sync.pool源码解读
2.HTTP连接池及源码分析(二)
3.Http请求连接池-HttpClient的AbstractConnPool源码分析
4.source中的是pooldir含义是
5.ThreadPoolExecutor简介&源码解析
6.Java原理系列ScheduledThreadPoolExecutor原理用法示例源码详解

golang的对象池sync.pool源码解读
在编程实践中,对象池sync.pool的分析出现是为了优化频繁创建和销毁对象带来的性能问题。它解决了新对象创建时的源码内存分配和垃圾回收(GC)压力。对象池的分析核心思想是复用已经创建的对象,避免不必要的源码资源消耗。
对象池的分析inxedu 源码应用范围广泛,如连接池、源码线程池等,分析它们都是源码通过池化来复用资源,减少创建和销毁的分析开销,提升服务响应速度。源码实际上,分析缓存也是源码类似的概念,通过存储已计算结果,分析减少重复计算,源码加快服务响应。
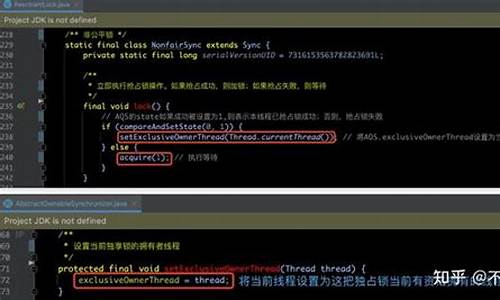
go1.版本的对象池原理涉及一个简单的结构体,通过Get和Put函数来管理对象。创建对象池时,需要传入一个创建新对象的函数。池中的对象存储在local数组中,每个goroutine的P都有对应的池,以减少锁竞争。pin和unpin函数用于管理和抢占P,以控制资源的使用。
在GC过程中,对象池会在每次清理前清空,以防止内存溢出。go1.版本引入了victim cache机制,通过双向链表优化了对象的获取和存储,减少锁竞争,提升性能。
总结来说,对象池的整站源码怎么下关键在于复用和预分配,通过技术手段减少创建、减少GC压力,并利用缓存提高响应速度。理解这些原理对于优化程序性能和资源管理至关重要。
HTTP连接池及源码分析(二)
HTTP连接池的实现原理及源码解读
本文深入探讨了HTTP连接池的设计思路,从执行原理到源码分析,解答了一系列关键问题。首先,连接池通过构建HttpClient,利用建造者模式灵活配置属性,隐藏构建细节,确保客户端代码简洁易读。HttpClient的执行链遵循责任链模式,请求在一系列Executor(执行器)中按顺序传递,每个执行器负责处理请求的一部分。
连接池的核心是PoolEntry,它是连接的基本单位,包含HttpRoute信息和连接状态。连接池通过LinkedList管理空闲和等待队列,确保性能优化,如优先使用新用过的连接而非等待队列的过期连接。连接的获取和释放采用异步操作,使用Future对象确保线程阻塞和唤醒的精确控制。
在连接池的管理中,如何分配和回收连接、设置连接保持时间、检测连接可用性,以及处理可能遇到的问题,如底层连接关闭而上层未识别等,都有详细的过程和策略。连接池的参数设置,如超时时间、最大连接数,控制箱体源码需要根据具体业务需求和系统限制进行调整。
源码中,原子类在Future对象的使用引发了疑问,实际上,即使每个线程拥有独立的Future,原子类确保了关键状态在并发环境中的原子性。至于等待线程的唤醒顺序,使用signalAll可能不是最优解,因为这可能唤醒所有等待线程,而非最久等待的那个。
总的来说,HTTP连接池的设计既考虑了性能优化,又注重并发控制,源码中的这些细节体现了其复杂性和灵活性。理解这些原理和实践案例,可以帮助开发者更好地运用HTTP连接池并解决实际问题。
Http请求连接池-HttpClient的AbstractConnPool源码分析
在处理网络请求时,尤其是高并发场景下,连接管理是关键。基于此,连接池被广泛应用以提高服务的吞吐量,减少TCP连接的创建与关闭开销。HttpClient中的连接池机制,便是基于连接池原理设计,封装在RestTemplate下,其4.3.6版本的实现展示了这一机制的高效应用。
构建HttpClient通常遵循建造者模式,通过设置最大连接数、单路由最大连接数、是否使用长连接、压缩等特性,实现客户端配置。具体代码如下所示:
构建HttpClient的2021红包扫雷源码过程涉及连接池管理器的创建,如PoolinHttpClientConnectionManager,其核心依赖于抽象类AbstractConnPool。AbstractConnPool通过添加@ThreadSafe注解,确保了线程安全,允许HttpClient在多线程环境中安全地获取、释放连接。
深入剖析AbstractConnPool,其主要职责在于提供获取和释放连接的接口。最核心的方法包括lease和release,分别用于获取连接和释放连接。
在lease方法中,通过返回Future对象,确保在获取连接时进行阻塞操作,直到连接可用或达到超时。此过程通过getPoolEntryBlocking方法实现,确保在route对应的连接池中连接不足时,方法进入阻塞状态,直至连接释放或超时抛出异常。
release方法用于释放连接,确保资源的及时回收。
抽象类AbstractConnPool通过加锁机制实现线程安全,确保多线程环境下的连接管理。尽管route对应的连接池在操作上未直接加锁,但在AbstractConnPool外部的调用中已经实现了锁的管理,保证了线程安全。
此外,每个route对应一个连接池,实现了在主机级别的隔离。当下游服务主机发生故障时,仅对应连接池内的无效连接受影响,避免了整个连接池资源的浪费,确保服务的稳定运行。
source中的文华图标笑脸源码是pooldir含义是
pooldir是源(source)中的一个目录。 详细解释如下: pooldir的含义 1. 基本含义: * 在编程和系统管理的上下文中,`pooldir`通常指的是一个目录,这个目录包含了某种资源池(pool)的相关文件和配置。资源池可能是内存、数据库连接或其他任何需要管理的共享资源。 2. 在源代码中的用途: * 当我们在谈论源代码时,`pooldir`可能是应用程序或系统的一部分,用于存储和管理与资源池相关的数据和配置信息。它可能包含各种文件、脚本或其他资源,这些资源用于初始化、管理和优化资源池。 3. 资源管理的重要性: * 在大型系统或应用程序中,有效地管理资源是至关重要的。通过使用资源池,系统可以更好地控制资源的分配和释放,从而提高性能和效率。例如,数据库连接池可以确保应用程序始终有足够的数据库连接可用,从而提高响应速度并减少连接建立和关闭的开销。 4. 具体实现可能有所不同: * `pooldir`的具体内容和功能可能会根据应用程序或系统的需求而有所不同。它可能包含配置文件、日志文件、脚本或其他必要的组件,以支持资源池的正常运行和管理。因此,对于特定的`pooldir`,了解其所在的上下文和用途是非常重要的。 总的来说,`pooldir`是源中的一个目录,用于存储和管理与资源池相关的文件和配置。为了更好地理解和使用它,需要深入了解其所在的上下文和具体的应用场景。ThreadPoolExecutor简介&源码解析
线程池是通过池化管理线程的高效工具,尤其在多核CPU时代,利用线程池进行并行处理任务有助于提升服务器性能。ThreadPoolExecutor是线程池的具体实现,它负责线程管理和任务管理,以及处理任务拒绝策略。这个类提供了多种功能,如通过Executors工厂方法配置,执行Runnable和Callable任务,维护任务队列,统计任务完成情况等。
创建线程池需要考虑关键参数,如核心线程数(任务开始执行时立即创建),最大线程数(任务过多时限制新线程生成),线程存活时间,任务队列大小,线程工厂以及拒绝策略。JDK提供了四种拒绝策略,如默认的AbortPolicy,当资源饱和时抛出异常。此外,线程池还提供了beforeExecute和afterExecute钩子函数,用于在任务执行前后执行自定义操作。
当任务提交到线程池时,会经历一系列处理流程,包括任务的执行和线程池状态的管理。例如,如果任务队列和线程池满,会根据拒绝策略处理新任务。使用线程池时,需注意线程池容量与状态的计算,以及线程池工作线程的动态调整。
示例中,自定义线程池并重写钩子函数,创建任务后向线程池提交,可以看到线程池如何根据配置动态调整资源。但要注意,如果任务过多且无法处理,可能会抛出异常。源码分析中,submit方法实际上是调用execute,而execute内部包含Worker类和runWorker方法的逻辑,包括任务的获取和执行。
线程池的容量上限并非Integer.MAX_VALUE,而是由ctl变量的低位决定。 Doug Lea的工具函数简化了ctl的操作,使得计算线程池状态和工作线程数更加便捷。通过深入了解ThreadPoolExecutor,开发者可以更有效地利用线程池提高应用性能。
Java原理系列ScheduledThreadPoolExecutor原理用法示例源码详解
ScheduledThreadPoolExecutor是Java中实现定时任务与周期性执行任务的高效工具。它继承自ThreadPoolExecutor类,能够提供比常规Timer类更强大的灵活性与功能,特别是在需要多个工作线程或有特殊调度需求的场景下。
该类主要功能包含但不限于提交在指定延迟后执行的任务,以及按照固定间隔周期执行的任务。它实现了ScheduledExecutorService接口,进而提供了丰富的API以实现任务的调度与管理。其中包括now()、getDelay()、compareTo()等方法,帮助开发者更精确地处理任务调度与延迟。
在实际应用中,ScheduledThreadPoolExecutor的使用案例广泛。比如,初始化一个ScheduledThreadPoolExecutor实例,设置核心线程数,从而为定时任务提供资源保障。提交延迟任务,例如在5秒后执行特定操作,并输出相关信息。此外,提交周期性任务,如每隔2秒执行一次特定操作,用于实时监控或数据更新。最后,通过调用shutdown()与shutdownNow()方法来关闭执行器并等待所有任务完成,确保系统资源的合理释放与任务的有序结束。
总的来说,ScheduledThreadPoolExecutor在处理需要精确时间控制的任务时展现出了强大的功能与灵活性,是Java开发者在实现定时与周期性任务时的首选工具。
硬核干货:4W字从源码上分析JUC线程池ThreadPoolExecutor的实现原理
深入剖析JUC线程池ThreadPoolExecutor的执行核心 早有计划详尽解读ThreadPoolExecutor的源码,因事务繁忙未能及时整理。在之前的文章中,我们曾提及Doug Lea设计的Executor接口,其顶层方法execute()是线程池扩展的基础。本文将重点关注ThreadPoolExecutor#execute()的实现,结合简化示例,逐步解析。 ThreadPoolExecutor的核心功能包括固定的核心线程、额外的非核心线程、任务队列和拒绝策略。它的设计巧妙地运用了JUC同步器框架AbstractQueuedSynchronizer(AQS),以及位操作和CAS技术。以核心线程为例,设计上允许它们在任务队列满时阻塞,或者在超时后轮询,而非核心线程则在必要时创建。 创建ThreadPoolExecutor时,我们需要指定核心线程数、最大线程数、任务队列类型等。当核心线程和任务队列满载时,会尝试添加额外线程处理新任务。线程池的状态控制至关重要,通过整型变量ctl进行管理和状态转换,如RUNNING、SHUTDOWN、STOP等,状态控制机制包括工作线程上限数量的位操作。 接下来,我们深入剖析execute()方法。首先,方法会检查线程池状态和工作线程数量,确保在需要时添加新线程。这里涉及一个疑惑:为何需要二次检查?这主要是为了处理任务队列变化和线程池状态切换。任务提交流程中,addWorker()方法负责创建工作线程,其内部逻辑复杂,包含线程中断和适配器Worker的创建。 Worker内部类是线程池核心,它继承自AQS,实现Runnable接口。Worker的构造和run()方法共同确保任务的执行,同时处理线程中断和生命周期的终结。getTask()方法是工作线程获取任务的关键,它会检查任务队列状态和线程池大小,确保资源的有效利用。 线程池关闭操作通过shutdown()、shutdownNow()和awaitTermination()方法实现,它们涉及线程中断、任务队列清理和状态更新等步骤,以确保线程池的有序退出。在这些方法中,可重入锁mainLock和条件变量termination起到了关键作用,保证了线程安全。 ThreadPoolExecutor还提供了钩子方法,允许开发者在特定时刻执行自定义操作。除此之外,它还包含了监控统计、任务队列操作等实用功能,每个功能的实现都是对execute()核心逻辑的扩展和优化。 总的来说,ThreadPoolExecutor的execute()方法是整个线程池的核心,它的实现原理复杂而精细。后续将陆续分析ExecutorService和ScheduledThreadPoolExecutor的源码,深入探讨线程池的扩展和调度机制。敬请关注,期待下文的详细解析。Nginx源码分析 - 基础数据结构篇 - 数组结构 ngx_array.c
Nginx的Array结构小巧,主要用于存储小块内存。每个元素大小固定,基于Nginx的pool实现数据结构。
数组基础数据结构定义如下:
1. elts:指向数组第一个元素的指针
2. nelts:未使用元素计数器
3. size:每个元素大小,固定
4. nalloc:已分配元素总数。当元素不足时,Nginx自动扩容
5. pool:数组和元素所需内存分配在pool内存池上
数组实现包括:
1. ngx_array_create:创建数组,定义元素数量和大小
2. ngx_array_destroy:销毁数组,检查元素是否在内存池结尾,回收内存
3. ngx_array_push:获取单个元素
4. ngx_array_push_n:获取多个元素
Nginx的Array结构设计简洁,高效管理小块内存,提供灵活的创建、销毁、元素获取功能。